为什么我使用了索引,查询还是慢?( 二 )
我们看上面这个语句的explain的输出结果显示的是PRIMARY 。 其实从数据上你是知道的 , 这个语句一定是做了全面扫描 。 但是优化器认为 , 这个语句的执行过程中 , 需要根据主键索引 , 定位到第1个满足ID>0的值 , 也算用到了索引 。
所以即使explain的结果里写的KEY不是 , 实际上也可能是全表扫描的 , 因此InnoDB里面只有一种情况叫做没有使用索引 , 那就是从主键索引的最左边的叶节点开始 , 向右扫描整个索引树 。
也就是说 , 没有使用索引并不是一个准确的描述 。
- 你可以用全表扫描来表示一个查询遍历了整个主键索引树;
- 也可以用全索引扫描 , 来说明像select a from t;这样的查询 , 他扫描了整个普通索引树;
- 而select * from t where id=2这样的语句 , 才是我们平时说的使用了索引 。 他表示的意思是 , 我们使用了索引的快速搜索功能 , 并且有效的减少了扫描行数 。
假设你现在维护了一个表 , 这个表记录了中国14亿人的基本信息 , 现在要查出所有年龄在10~15岁之间的姓名和基本信息 , 那么你的语句会这么写 ,
select * from t_people where age between 10 and 15 。你一看这个语句一定要在age字段上开始建立索引了 , 否则就是个全面扫描 , 但是你会发现 , 在你建立索引以后 , 这个语句还是执行慢 , 因为满足这个条件的数据可能有超过1亿行 。
我们来看看建立索引以后 , 这个表的组织结构图:
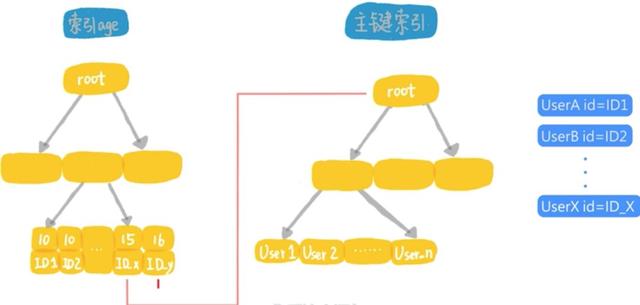 文章插图
文章插图这个语句的执行流程是这样的:
- 从索引上用树搜索 , 取到第1个age等于10的记录 , 得到它的主键id的值 , 根据id的值去主键索引取整行的信息 , 作为结果集的一部分返回;
- 在索引age上向右扫描 , 取下一个id的值 , 到主键索引上取整行信息 , 作为结果集的一部分返回;
- 重复上面的步骤 , 直到碰到第1个age大于15的记录;
对于一个大表 , 不止要有索引 , 索引的过滤性还要足够好 。
像刚才这个例子的age , 它的过滤性就不够好 , 在设计表结构的时候 , 我们要让所有的过滤性足够好 , 也就是区分度足够高 。
回表的代价那么过滤性好了 , 是不是表示查询的扫描行数就一定少呢?
我们再来看一个例子:
如果你的执行语句是
select * from t_people where name='张三' and age=8t_people表上有一个索引是姓名和年龄的联合索引 , 那这个联合索引的过滤性应该不错 , 可以在联合索引上快速找到第1个姓名是张三 , 并且年龄是8的小朋友 , 当然这样的小朋友应该不多 , 因此向右扫描的行数很少 , 查询效率就很高 。
但是查询的过滤性和索引的过滤性可不一定是一样的 , 如果现在你的需求是查出所有名字的第1个字是张 , 并且年龄是8岁的所有小朋友 , 你的语句会怎么写呢?
你的语句要怎么写?很显然你会这么写:
select * from t_people where name like '张%' and age=8;在MySQL5.5和之前的版本中 , 这个语句的执行流程是这样的:
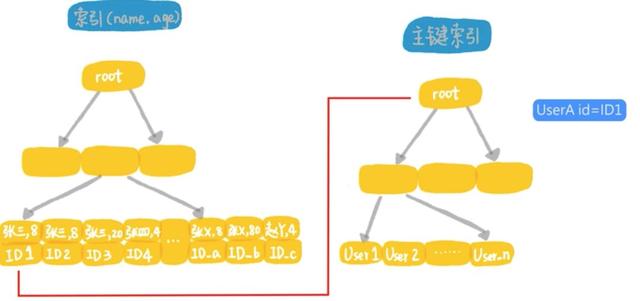 文章插图
文章插图- 首先从联合索引上找到第1个年龄字段是张开头的记录 , 取出主键id , 然后到主键索引树上 , 根据id取出整行的值;
- 判断年龄字段是否等于8 , 如果是就作为结果集的一行返回 , 如果不是就丢弃 。
- 在联合索引上向右遍历 , 并重复做回表和判断的逻辑 , 直到碰到联合索引树上名字的第1个字不是张的记录为止 。
你可以看到这个执行过程 , 它的回表次数特别多 , 性能不够好 , 有没有优化的方法呢?
在MySQL5.6版本 , 引入了index condition pushdown的优化 。 我们来看看这个优化的执行流程:
- 看不上|为什么还有用户看不上华为Mate40系列来看看内行人怎么说
- 先别|用了周冬雨的照片,我会成为下一个被告?自媒体创作者先别自乱阵脚
- 巨头|“社区薇娅”都不够用了 一线互联网巨头全员下场卖菜
- 手机|iPhone12 Pro居然比mini还好卖?网友:24期免息起作用了!
- 制药领域|为什么AI制药这么火,为什么是现在?
- 手机壳里头|为什么要在手机壳里面夹钱?10个有9个不懂,我才知道大有讲究
- 短视频|全球最火APP?抖音爆火背后离不开这几剂“猛药”为什么抖音能够这么火?
- 电商快递|包邮不香吗,为什么还有人加49元让小哥穿西装专车送快递?
- 团队|为什么项目管理非常重要?
- 猫腻|为什么拼多多上商品价格那么便宜还包邮?有什么猫腻?看完明白了