一口气说出Kafka为啥这么快?( 三 )
它可以充当预读缓存 , 异步预读取 , 从而提前运行来自应用程序的请求 。 但是 , 当请求的数据量远远大于内核缓冲区的大小时 , 内核缓冲区就成为了性能瓶颈 。
不同于直接复制数据 , 而是迫使系统在用户态和内核态之间频繁切换 , 直到所有数据都被传输 。
相比之下 , 零拷贝方法是在单个操作中处理的 。 前面例子中的代码可以改写为一行代码:
fileDesc.transferTo(offset, len, socket); 下面详细解释说明是零拷贝: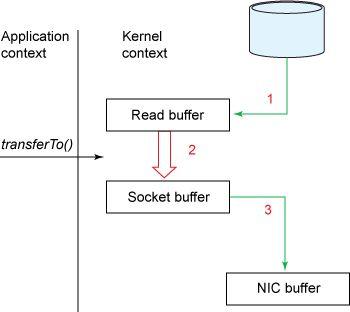 文章插图
文章插图在这个模型中 , 上下文切换的数量减少到一个 。 具体来说 , transferTo() 方法指示块设备通过 DMA 引擎将数据读入读缓冲区 。
然后 , 将数据从读缓冲区复制到套接字缓冲区 。 最后 , 通过 DMA 将数据从套接字缓冲区复制到 NIC 缓冲区 。
 文章插图
文章插图因此 , 我们将复制的数量从 4 个减少到 3 个 , 并且其中只有一个复制操作涉及到 CPU 。 我们还将上下文切换的数量从 4 个减少到 2 个 。
这是一个巨大的改进 , 但还不是查询零拷贝 。 在运行 Linux 内核 2.4 或更高版本时 , 以及在支持 gather 操作的网卡上 , 可以进一步优化 。
如下图所示:
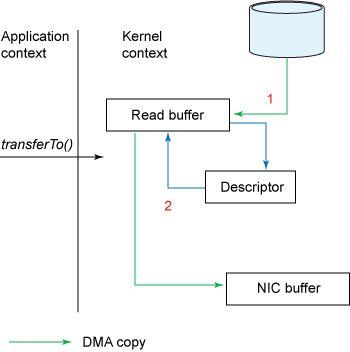 文章插图
文章插图按照前面的示例 , 调用 transferTo() 方法会导致设备通过 DMA 引擎将数据读入内核缓冲区 。
但是 , 对于 gather 操作 , 读缓冲区和套接字缓冲区之间不存在复制 。 相反 , NIC被赋予一个指向读缓冲区的指针 , 连同偏移量和长度 。 在任何情况下 , CPU 都不涉及复制缓冲区 。
文件大小从几 MB 到 1GB 的范围内 , 传统拷贝和零拷贝相比 , 结果显示零拷贝的性能提高了两到三倍 。
但更令人印象深刻的是 , Kafka 使用纯 JVM 实现了这一点 , 没有本地库或 JNI 代码 。
避免垃圾回收
大量使用通道、缓冲区和页面缓存还有一个额外的好处——减少垃圾收集器的工作负载 。
例如 , 在 32 GB RAM 的机器上运行 Kafka 将产生 28-30 GB 的页面缓存可用空间 , 完全超出了垃圾收集器的范围 。
吞吐量的差异非常小(大约几个百分点) , 但是经过正确调优的垃圾收集器的吞吐量可能非常高 , 特别是在处理短生存期对象时 。 真正的收益在于减少抖动 。
通过避免垃圾回收 , 服务端不太可能遇到因垃圾回收引起的程序暂停 , 从而影响客户端 , 加大记录的通信延迟 。
与初期的 Kafka 相比 , 现在避免垃圾回收已经不是什么问题了 。 像 Shenandoah 和 ZGC 这样的现代垃圾收集器可以扩展到巨大的、多 TB 级的堆 , 在最坏的情况下 , 并且可以自动调整垃圾收集的暂停时间 , 降到几毫秒 。
现在 , 可以看见大量的基于 Java 虚拟机的应用程序使用堆缓存 , 而不是堆外缓存 。
流处理的并行性
日志的 I/O 效率是性能的一个重要方面 , 主要的性能影响在于写 。 Kafka 对主题结构和消费生态系统中的并行性处理是其读性能的基础 。
这种组合产生了整体非常高的端到端消息吞吐量 。 将并发性深入到分区方案和使用者组的操作中 , 这实际上是 Kafka 中的一种负载均衡机制——将分区平均地分配到各个消费者中 。
将此与传统的消息队列进行比较:在 RabbitMQ 的设置中 , 多个并发的消费者可以以轮询的方式从队列中读取数据 , 但这样做会丧失消息的有序性 。
分区机制有利于 Kafka 服务端的水平扩展 。 每个分区都有一个专门的领导者 。 因此 , 任何重要的多分区的主题都可以利用整个服务端集群进行写操作 。
这是 Kafka 和传统消息队列的另一个区别 。 当后者利用集群来提高可用性时 , Kafka 通过负载均衡来提高可用性、持久性和吞吐量 。
- Logstash整合Kafka
- 卢伟冰要跟风做mini版手机,说出缺点之后网友都不想要了
- 台积|台积电、中芯国际、ASML三家的大股东是谁?说出来你可能不信
- flink消费kafka的offset与checkpoint
- 为什么中国网民更愿意用微信支付?终于有人说出答案,马云沉默了
- 德国|轮到德国头疼了,美媒罕见说出实话:盾构机技术没有中国根本不行
- 台积电、中芯国际、ASML三家的大股东是谁?说出来你可能不信
- 说出|顾客抱怨快递小哥不把快件送上楼,快递小哥说出原因,让人心酸
- 任正非|任正非说出中美最大差距只有两个字,值得所有国人深思
- 行业|为啥快递行业出现“招工难”,月薪8千却没人干离职快递小哥说出真相