flink消费kafka的offset与checkpoint
生产环境有个作业 , 逻辑很简单 , 读取kafka的数据 , 然后使用hive catalog , 实时写入hbase , hive , redis 。 使用的flink版本为1.11.1 。
为了防止写入hive的文件数量过多 , 我设置了checkpoint为30分钟 。
env.enableCheckpointing(1000 * 60 * 30); // 1000 * 60 * 30 => 30 minutes达到的效果就是每30分钟生成一个文件 , 如下:
hive> dfs -ls /opt/user/hive/warehouse/dw.db/ods_analog_zgyp/dt_day=2020-10-18/dt_hour=00/ ;Found 10 items-rw-r--r--3 hdfs hive0 2020-10-18 01:20 /opt/user/hive/warehouse/dw.db/ods_analog_zgyp/dt_day=2020-10-18/dt_hour=00/_SUCCESS-rw-r--r--3 hdfs hive248895 2020-10-18 00:20 /opt/user/hive/warehouse/dw.db/ods_analog_zgyp/dt_day=2020-10-18/dt_hour=00/part-5b7b6d44-993a-4af7-b7ee-1a8ab64d3453-0-10911-rw-r--r--3 hdfs hive306900 2020-10-18 00:50 /opt/user/hive/warehouse/dw.db/ods_analog_zgyp/dt_day=2020-10-18/dt_hour=00/part-5b7b6d44-993a-4af7-b7ee-1a8ab64d3453-0-10912-rw-r--r--3 hdfs hive208227 2020-10-18 01:20 /opt/user/hive/warehouse/dw.db/ods_analog_zgyp/dt_day=2020-10-18/dt_hour=00/part-5b7b6d44-993a-4af7-b7ee-1a8ab64d3453-0-10913-rw-r--r--3 hdfs hive263586 2020-10-18 00:20 /opt/user/hive/warehouse/dw.db/ods_analog_zgyp/dt_day=2020-10-18/dt_hour=00/part-5b7b6d44-993a-4af7-b7ee-1a8ab64d3453-1-10911-rw-r--r--3 hdfs hive307723 2020-10-18 00:50 /opt/user/hive/warehouse/dw.db/ods_analog_zgyp/dt_day=2020-10-18/dt_hour=00/part-5b7b6d44-993a-4af7-b7ee-1a8ab64d3453-1-10912-rw-r--r--3 hdfs hive196777 2020-10-18 01:20 /opt/user/hive/warehouse/dw.db/ods_analog_zgyp/dt_day=2020-10-18/dt_hour=00/part-5b7b6d44-993a-4af7-b7ee-1a8ab64d3453-1-10913-rw-r--r--3 hdfs hive266984 2020-10-18 00:20 /opt/user/hive/warehouse/dw.db/ods_analog_zgyp/dt_day=2020-10-18/dt_hour=00/part-5b7b6d44-993a-4af7-b7ee-1a8ab64d3453-2-10911-rw-r--r--3 hdfs hive338992 2020-10-18 00:50 /opt/user/hive/warehouse/dw.db/ods_analog_zgyp/dt_day=2020-10-18/dt_hour=00/part-5b7b6d44-993a-4af7-b7ee-1a8ab64d3453-2-10912-rw-r--r--3 hdfs hive216655 2020-10-18 01:20 /opt/user/hive/warehouse/dw.db/ods_analog_zgyp/dt_day=2020-10-18/dt_hour=00/part-5b7b6d44-993a-4af7-b7ee-1a8ab64d3453-2-10913hive> 但是 , 同时也观察到归属于这个作业的kafka消费组积压数量 , 每分钟消费数量 , 明显具有周期性消费峰值 。
比如 , 对于每30分钟时间间隔度的一个观察 , 前面25分钟的“每分钟消费数量”都是为0 , 然后 , 后面5分钟的“每分钟消费数量”为300k 。 同理 , “消费组积压数量”也出现同样情况 , 积压数量一直递增 , 但是到了30分钟的间隔 , 就下降到数值0 。 如图 。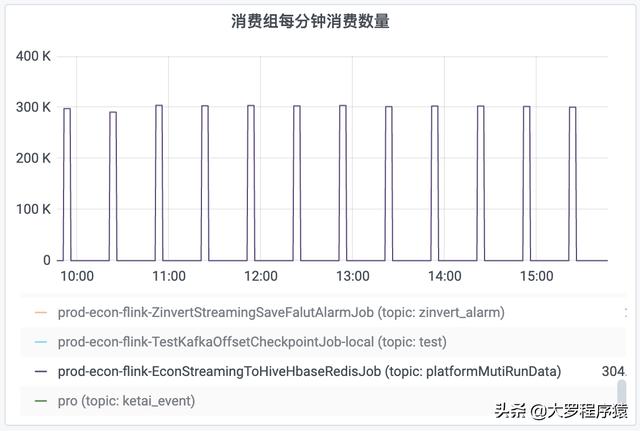 文章插图
文章插图
消费组每分钟消费数量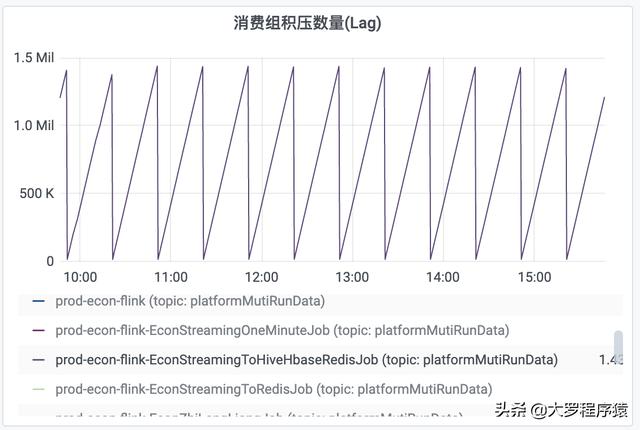 文章插图
文章插图
消费组积压数量
但其实 , 通过对hbase , hive , redis的观察 , 数据是实时写入的 , 并不存在前面25分钟没有消费数据的情况 。
查阅资料得知 , flink会自己维护一份kafka的offset , 然后checkpoint时间点到了 , 再把offset更新回kafka 。
为了验证这个观点 , “flink在checkpoint的时候 , 才把消费kafka的offset更新回kafka” , 同时 , 观察 , savepoint机制是否会重复消费kafka , 我尝试写一个程序 , 逻辑很简单 , 就是从topic "test"读取数据 , 然后写入topic "test2" 。 特别说明 , 这个作业的checkpoint是1分钟 。
package com.econ.powercloud.jobsTest;import org.apache.flink.api.common.serialization.SimpleStringSchema;import org.apache.flink.api.java.utils.ParameterTool;import org.apache.flink.kafka.shaded.org.apache.kafka.clients.producer.ProducerRecord;import org.apache.flink.streaming.api.CheckpointingMode;import org.apache.flink.streaming.api.datastream.DataStreamSource;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;import org.apache.flink.streaming.connectors.kafka.KafkaSerializationSchema;import javax.annotation.Nullable;import java.util.Properties;public class TestKafkaOffsetCheckpointJob {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.enableCheckpointing(1000 * 60);ParameterTool parameterTool = ParameterTool.fromArgs(args);String bootstrapServers = parameterTool.get("bootstrap.servers") == null ? "localhost:9092" : parameterTool.get("bootstrap.servers");Properties properties = new Properties();properties.setProperty("bootstrap.servers", bootstrapServers);properties.setProperty("group.id", "prod-econ-flink-TestKafkaOffsetCheckpointJob-local");properties.setProperty("transaction.timeout.ms", String.valueOf(1000 * 60 * 5));String topic = "test";FlinkKafkaConsumer stringFlinkKafkaConsumer = new FlinkKafkaConsumer
- 会员|美容院使用会员管理软件给顾客更好的消费体验!
- 死亡|这届年轻人不讲武德,旧消费主义社会性死亡
- 好消息|好消息!双十二实体店消费券已经开领
- 借贷消费|花呗该为网贷背锅吗
- 消费|在日活6亿+的抖音上,新消费品牌如何玩好流量生意?
- 市场|高明市场监管部门发布重要消费警示!
- 外卖|美团将增加一个“新功能”,外卖员迎来新时代,消费者会面临什么
- 上涨|美团营收全面上涨
- 消费|宿言:早看早应用~提升零售产品销售额的9个手段!
- 投诉|巴西“黑五”活动投诉增多 消费者最不满误导性广告