一口气说出Kafka为啥这么快?( 二 )
另一种是发布订阅主题允许点对多点消息通信 , 但这样做的代价是持久性 。 在传统消息队列模型中实现持久化的点对多点消息通信模型需要为每个有状态的使用者维护专用消息队列 。
这将放大读写的消耗 。 消息生产者被迫将消息写入多个消息队列中 。 另外一种选择是使用扇出中继 , 扇出中继可以消费来自一个队列中的记录 , 并将记录写入其他多个队列中 , 但这只会将延迟放大点 。
并且 , 一些消费者正在服务端上生成负载——读和写 I/O 的混合 , 既有顺序的 , 也有随机的 。
Kafka 中的消费者是“便宜的” , 只要他们不改变日志文件(只有生产者或 Kafka 的内部进程被允许这样做) 。
这意味着大量消费者可以并发地从同一主题读取数据 , 而不会使集群崩溃 。 添加一个消费者仍然有一些成本 , 但主要是顺序读取夹杂很少的顺序写入 。
因此 , 在一个多样化的消费者系统中 , 看到一个主题被共享是相当正常的 。
未刷新的缓冲写操作
Kafka 性能的另一个基本原因是 , 一个值得进一步研究的原因:Kafka 在确认写操作之前并没有调用 fsync 。 ACK 的唯一要求是记录已经写入 I/O 缓冲区 。
这是一个鲜为人知的事实 , 但却是一个至关重要的事实 。 实际上 , 这就是 Kafka 的执行方式 , 就好像它是一个内存队列一样——Kafka 实际上是一个由磁盘支持的内存队列(受缓冲区/页面缓存大小的限制) 。
但是 , 这种形式的写入是不安全的 , 因为副本的出错可能导致数据丢失 , 即使记录似乎已经被 ACK 。
换句话说 , 与关系型数据库不同 , 仅写入缓冲区并不意味着持久性 。 保证 Kafka 持久性的是运行几个同步的副本 。
即使其中一个出错了 , 其他的(假设不止一个)将继续运行——假设出错的原因不会导致其他的副本也出错 。
因此 , 无 fsync 的非阻塞 I/O 方法和冗余的同步副本组合为 Kafka 提供了高吞吐、持久性和可用性 。
客户端优化
大多数数据库、队列和其他形式的持久性中间件都是围绕全能服务器(或服务器集群)和瘦客户端的概念设计的 。
客户端的实现通常被认为比服务器端简单得多 。 服务器会处理大部分的负载 , 而客户端仅充当服务端的门面 。
Kafka 采用了不同的客户端设计方法 。 在记录到达服务器之前 , 会在客户端上执行大量的工作 。
这包括对累加器中的记录进行分段、对记录键进行散列以得到正确的分区索引、对记录进行校验以及对记录批处理进行压缩 。
客户端知道集群元数据 , 并定期刷新元数据以跟上服务端拓扑的更改 。 这让客户端更准确的做出转发决策 。
不同于盲目地将记录发送到集群并依靠后者将其转发到适当的节点 , 生产者客户端可以直接将写请求转发到分区主机 。
类似地 , 消费者客户端能够在获取记录时做出更明智的决定 , 比如在发出读查询时 , 可以使用在地理上更接近消费者客户端的副本 。 (该特性是从 Kafka 的 2.4.0 版本开始提供 。 )
零拷贝
一种典型的低效方式是在缓冲之间复制字节数据 。 Kafka 使用由生产者、消费者、服务端三方共享的二进制消息格式 , 这样即使数据块被压缩了 , 也可以不加修改地传递数据 。
虽然消除通信方之间的数据结构差异是重要的一步 , 但它本身并不能避免数据的复制 。
Kafka 使用 Java 的 NIO 框架 , 特别是 java.nio.channels.FileChannel 的 transferTo() 方法 , 在 Linux 和 UNIX 系统上解决了这个问题 。
此方法允许字节从源通道传输到接收通道 , 而不需要将应用程序作为传输中介 。
了解 NIO 的不同之处 , 请思考传统的方法会怎么做 , 将源通道读入字节缓冲区 , 然后作为两个独立的操作写入接收器通道:
File.read(fileDesc, buf, len); Socket.send(socket, buf, len); 可以用下图来表示: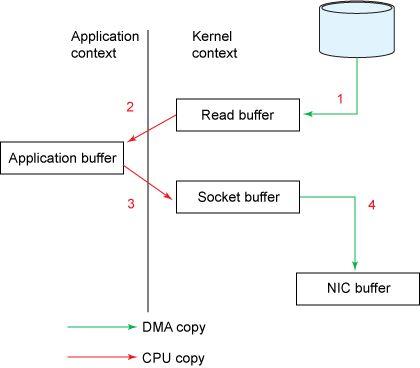 文章插图
文章插图
虽然这副图看起来很简单 , 但是在内部 , 复制操作需要在用户态和内核态之间进行四次上下文切换 , 并且在操作完成之前要复制四次数据 。
下图概述了每次步骤的上下文切换: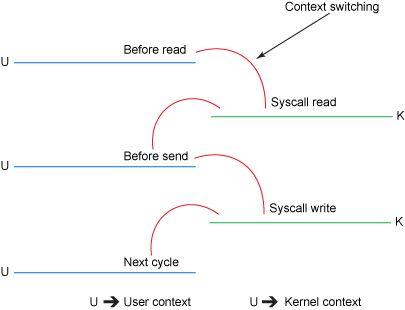 文章插图
文章插图
详细说明:
- 初始的 read() 方法导致上下文从用户态切换到内核态 。 文件被读取 , 它的内容被 DMA(Direct Memory Access 直接存储器访问)引擎复制到内核地址空间中的缓冲区 。 这与代码段中使用的缓冲区是不同的 。
- Logstash整合Kafka
- 卢伟冰要跟风做mini版手机,说出缺点之后网友都不想要了
- 台积|台积电、中芯国际、ASML三家的大股东是谁?说出来你可能不信
- flink消费kafka的offset与checkpoint
- 为什么中国网民更愿意用微信支付?终于有人说出答案,马云沉默了
- 德国|轮到德国头疼了,美媒罕见说出实话:盾构机技术没有中国根本不行
- 台积电、中芯国际、ASML三家的大股东是谁?说出来你可能不信
- 说出|顾客抱怨快递小哥不把快件送上楼,快递小哥说出原因,让人心酸
- 任正非|任正非说出中美最大差距只有两个字,值得所有国人深思
- 行业|为啥快递行业出现“招工难”,月薪8千却没人干离职快递小哥说出真相