按关键词阅读:
欢迎访问我的GitHub
内容:所有原创文章分类和汇总 , 及配套源码 , 涉及Java、Docker、Kubernetes、DevOPS等;
本篇概览
- 本文是《hive学习笔记》系列的第十一篇 , 截至目前 , 一进一出的UDF、多进一出的UDAF咱们都学习过了 , 最后还有一进多出的UDTF留在本篇了 , 这也是本篇的主要内容;
- 一进多出的UDTF , 名为用户自定义表生成函数(User-Defined Table-Generating Functions ,UDTF);
- 前面的文章中 , 咱们曾经体验过explode就是hive内置的UDTF:
hive> select explode(address) from t3;OKprovince guangdongcity shenzhenprovince jiangsucity nanjingTime taken: 0.081 seconds, Fetched: 4 row(s)- 本篇的UDTF一共有两个实例:把一列拆成多列、把一列拆成多行(每行多列);
- 接下来开始实战;
- 如果您不想编码 , 可以在GitHub下载所有源码 , 地址和链接信息如下表所示:
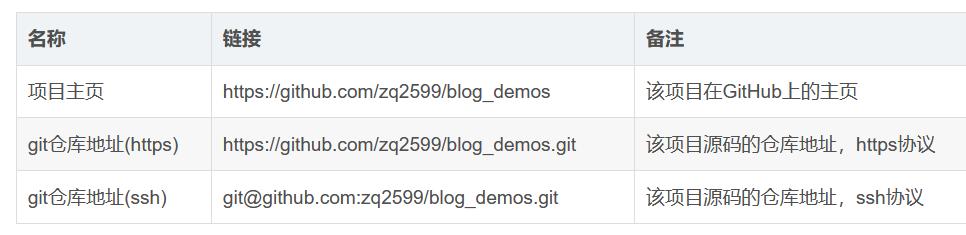 文章插图
文章插图- 这个git项目中有多个文件夹 , 本章的应用在hiveudf文件夹下 , 如下图红框所示:
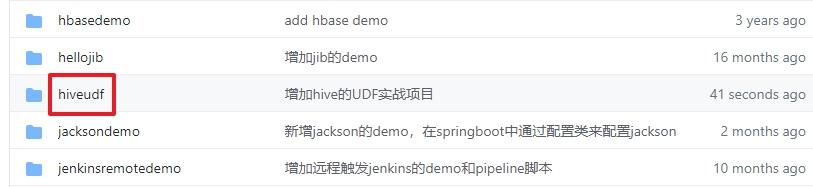 文章插图
文章插图准备工作为了验证UDTF的功能 , 咱们要先把表和数据都准备好:
- 新建名为t16的表:
create table t16(person_namestring,string_field string)row format delimited fields terminated by '|'stored as textfile;- 本地新建文本文件016.txt , 内容如下:
tom|1:province:guangdongjerry|2:city:shenzhenjohn|3- 导入数据:
load data local inpath '/home/hadoop/temp/202010/25/016.txt' overwrite into table t16;- 数据准备完毕 , 开始编码;
- 需要继承GenericUDTF类;
- 重写initialize方法 , 该方法的入参只有一个 , 类型是StructObjectInspector , 从这里可以取得UDTF作用了几个字段 , 以及字段类型;
- initialize的返回值是StructObjectInspector类型 , UDTF生成的每个列的名称和类型都设置到返回值中;
- 重写process方法 , 该方法中是一进多出的逻辑代码 , 把每个列的数据准备好放在数组中 , 执行一次forward方法 , 就是一行记录;
- close方法不是必须的 , 如果业务逻辑执行完毕 , 可以将释放资源的代码放在这里执行;
- 接下来 , 就按照上述关键点开发UDTF;
- 接下来要开发的UDTF , 名为udf_wordsplitsinglerow , 作用是将入参拆分成多个列;
- 下图红框中是t16表的一条原始记录的string_field字段 , 会被udf_wordsplitsinglerow处理:
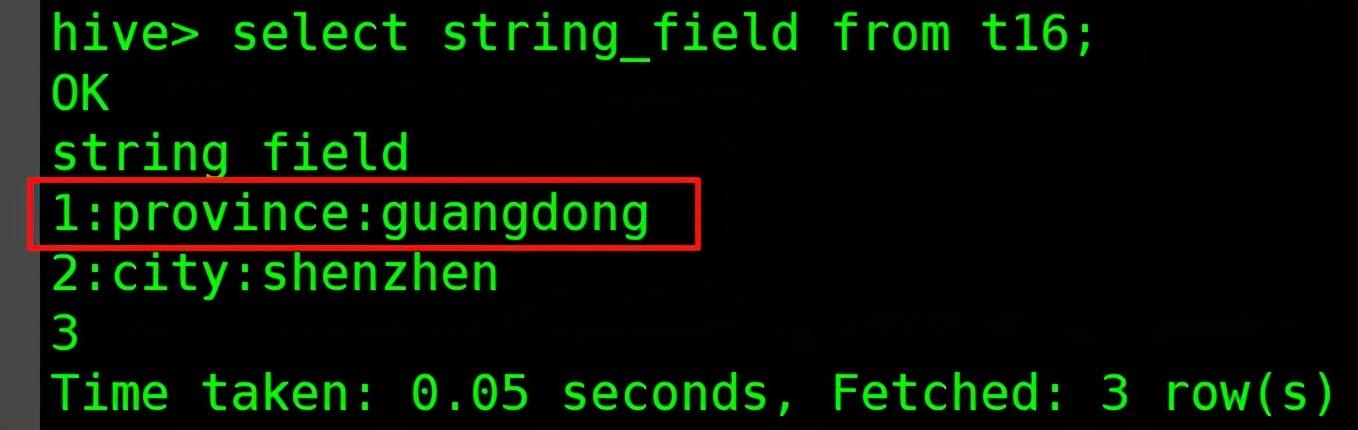 文章插图
文章插图- 上面红框中的字段被UDTF处理处理后 , 一列变成了三列 , 每一列的名称如下图黄框所示 , 每一列的值如红框所示:
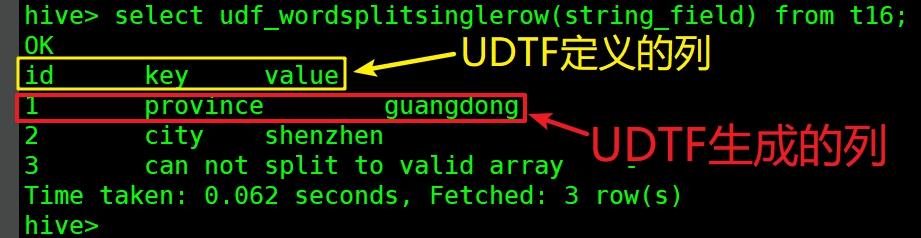 文章插图
文章插图- 以上就是咱们马上就要开发的功能;
- 打开前文创建的hiveudf工程 , 新建WordSplitSingleRow.java:
package com.bolingcavalry.hiveudf.udtf;import org.apache.commons.lang.StringUtils;import org.apache.hadoop.hive.ql.exec.UDFArgumentException;import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;import org.apache.hadoop.hive.ql.metadata.HiveException;import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;import org.apache.hadoop.hive.serde2.objectinspector.*;import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector.Category;import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;import java.util.ArrayList;import java.util.List;/** * @Description: 把指定字段拆成多列 * @author: willzhao E-mail: zq2599@gmail.com * @date: 2020/11/5 14:43 */public class WordSplitSingleRow extends GenericUDTF {private PrimitiveObjectInspector stringOI = null;private final static String[] EMPTY_ARRAY = {"NULL", "NULL", "NULL"};/*** 一列拆成多列的逻辑在此* @param args* @throws HiveException*/@Overridepublic void process(Object[] args) throws HiveException {String input = stringOI.getPrimitiveJavaObject(args[0]).toString();// 无效字符串if(StringUtils.isBlank(input)) {forward(EMPTY_ARRAY);} else {// 分割字符串String[] array = input.split(":");// 如果字符串数组不合法 , 就返回原始字符串和错误提示if(null==array || array.length<3) {String[] errRlt = new String[3];errRlt[0] = input;errRlt[1] = "can not split to valid array";errRlt[2] = "-";forward(errRlt);} else {forward(array);}}}/*** 释放资源在此执行 , 本例没有资源需要释放* @throws HiveException*/@Overridepublic void close() throws HiveException {}@Overridepublic StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {List
稿源:(未知)
【傻大方】网址:http://www.shadafang.com/c/111J2D952020.html
标题:hive学习笔记之十一:UDTF