按关键词阅读:
inputFields = argOIs.getAllStructFieldRefs();// 当前UDTF只处理一个参数 , 在此判断传入的是不是一个参数if (1 != inputFields.size()) {throw new UDFArgumentLengthException("ExplodeMap takes only one argument");}// 此UDTF只处理字符串类型if(!Category.PRIMITIVE.equals(inputFields.get(0).getFieldObjectInspector().getCategory())) {throw new UDFArgumentException("ExplodeMap takes string as a parameter");}stringOI = (PrimitiveObjectInspector)inputFields.get(0).getFieldObjectInspector();//列名集合ArrayList fieldNames = new ArrayList();//列对应的value值ArrayList
验证UDTF接下来将WordSplitSingleRow.java部署成临时函数并验证;
add jar /home/hadoop/udf/hiveudf-1.0-SNAPSHOT.jar;create temporary function udf_wordsplitsinglerow as 'com.bolingcavalry.hiveudf.udtf.WordSplitSingleRow';select udf_wordsplitsinglerow(string_field) from t16;hive> select udf_wordsplitsinglerow(string_field) from t16;OKid key value1 province guangdong2 city shenzhen3 can not split to valid array -Time taken: 0.066 seconds, Fetched: 3 row(s)关键点要注意select person_name,udf_wordsplitsinglerow(string_field) from t16;hive> select person_name,udf_wordsplitsinglerow(string_field) from t16;FAILED: SemanticException [Error 10081]: UDTF's are not supported outside the SELECT clause, nor nested in expressionsselect t.person_name, udtf_id, udtf_key, udtf_valuefrom (select person_name, string_fieldfromt16) t LATERAL VIEW udf_wordsplitsinglerow(t.string_field) v asudtf_id, udtf_key, udtf_value;hive> select t.person_name, udtf_id, udtf_key, udtf_value> from (>select person_name, string_field>fromt16> ) t LATERAL VIEW udf_wordsplitsinglerow(t.string_field) v asudtf_id, udtf_key, udtf_value;OKt.person_name udtf_id udtf_key udtf_valuetom 1 province guangdongjerry 2 city shenzhenjohn 3 can not split to valid array -Time taken: 0.122 seconds, Fetched: 3 row(s)一列拆成多行(每行多列)tom|1:province:guangdong,4:city:yangjiangjerry|2:city:shenzhenjohn|3load data local inpath '/home/hadoop/temp/202010/25/016_multi.txt' overwrite into table t16;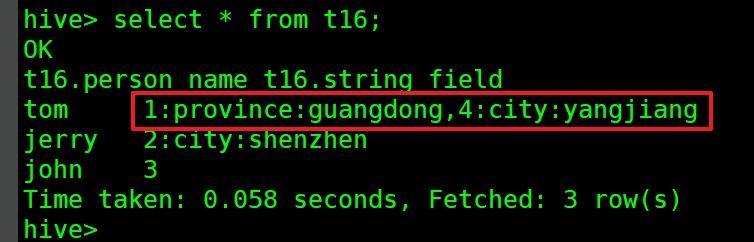 文章插图
文章插图
![]()
稿源:(未知)
【傻大方】网址:http://www.shadafang.com/c/111J2D952020.html
标题:hive学习笔记之十一:UDTF( 二 )