监督|长尾问题太严重?半监督和自监督就可以有效缓解!( 三 )
受此启发,我们系统地探索了无标记数据的有效性。我们采用最简单的自训练(self-training)的半监督学习方法,即对无标记数据生成伪标签(pseudo-labeling)进而一起训练。
准确来讲,我们首先在原始的不平衡数据集上正常训练获得一个中间步骤分类器,并将其应用于生成未标记数据的伪标签;通过结合两部分数据,我们最小化损失函数以学习最终模型。
值得注意的是,除了self-training之外,其他的半监督算法也可以通过仅修改损失函数轻松地并入我们的框架中;同时,由于我们未指定和的学习策略,因此半监督框架也能很轻易的和现有类别不平衡的算法相结合。
实验:到了激动人心的实验部分了 :)! 首先说一下实验的setting --- 我们选择了人工生成的长尾版本的CIFAR-10和SVHN数据集,因为他们均有天然对应、且数据分布相似的无标记数据:CIFAR-10属于Tiny-Images数据集,而SVHN本身就有一个extra dataset可用来模拟多余的无标记数据。
这部分更加细节的setting请详见我们的文章;我们也开源了相应的数据供大家使用测试。对于无标记数据,我们也考虑到了其可能的不平衡/长尾分布,并显式的比较了不同分布的无标记数据的影响(和的典型分布如下):
文章插图
典型的原始数据分布,以及可能的无标记数据分布
而具体的实验结果如下表所示。我们可以清楚看到,利用无标记数据,半监督学习能够显著提高最后的分类结果,并且在不同的 (1) 数据集,(2) base学习方法,(3) 标记数据的不平衡比率,(4) 无标记数据的不平衡比率下,都能带来一致的提升。此外,我们在附录里还提供了 (5) 不同半监督学习方法的比较,以及不同data amount的ablation study。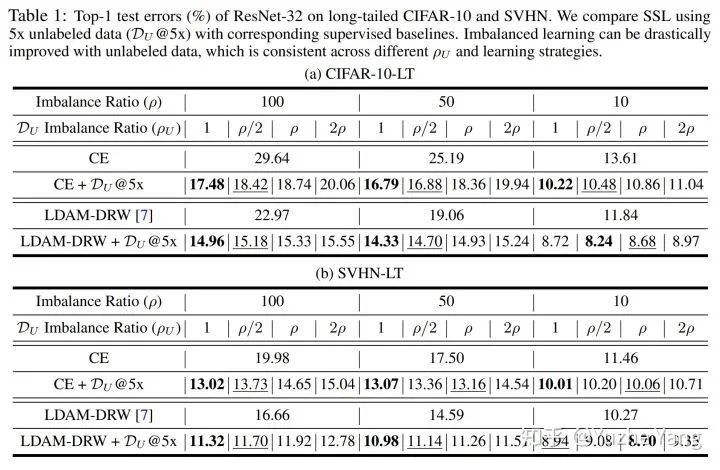
文章插图
最后展示一下定性的实验结果。我们分别画出了不使用/使用无标签数据,在训练集和测试集上的t-SNE可视化图。从图中可以直观看出,使用未标记数据有助于建模更清晰的类边界,并促成更好的类间分离,尤其是对于尾类的样本。
这样的结果也符合我们的直观理解,对于尾类样本,其所处区域的数据密度低,模型在学习过程中不能对这些low-density区域很好建模边界,从而造成模糊性(ambiguity)导致较差的泛化;而无标记数据则能有效提高低密度区域样本量,加上了更强的regularization使得模型重新更好地建模边界。
文章插图
关于半监督不均衡学习的进一步思考
虽然通过半监督学习,模型在不平衡数据上的表现能够得到显著的提升,但是半监督学习本身也存在一些实际应用的问题,而这些问题在不平衡学习中可能会被进一步放大。
接下来我们通过设计相应实验来系统地阐述和分析这些情况,并motivate接下来对于不平衡标签“负面价值”的思考和研究。
首先,无标签数据与原始数据的相关性对于半监督学习的结果有很大的影响。举个栗子,对于CIFAR-10(10类分类)来说,获得的无标签数据可能并不属于原本10类中的任何一类(比如高山兀鹫...),这时多余的信息则可能对训练和结果造成不小影响。
为了验证这一观点,我们固定无标签数据和原始训练数据有相同的不平衡比率,但是通过改变无标签数据和原始训练数据的相关性去构造不同的无标签数据集。从Figure 2中我们可以看出,无标签数据的相关性需要达到将近60%以上才能过对不平衡学习有正面的帮助。
既然原始训练数据是不平衡的,能够采集到的无标签数据也大概率是极度不平衡的。譬如医疗数据中,你构建了自动诊断某类疾病的数据集,其中正例(患病)很少,只占总体1%,但因为此病得病率就在1%左右,即使大量搜集无标签数据,其中真正患病数据大概率还是很少。
【 监督|长尾问题太严重?半监督和自监督就可以有效缓解!】那么,在同时考虑相关性的前提下,如Figure 3所示,我们首先让无标签数据集有足够的相关性(60%),但改变无标签数据的不平衡比率。这个实验中,我们固定原始训练数据的不平衡比率为50。可以看到对于无标签数据,当无标签数据过于不平衡(本例中不平衡比率高于50)时,利用无标签数据反而可能让结果变得更差。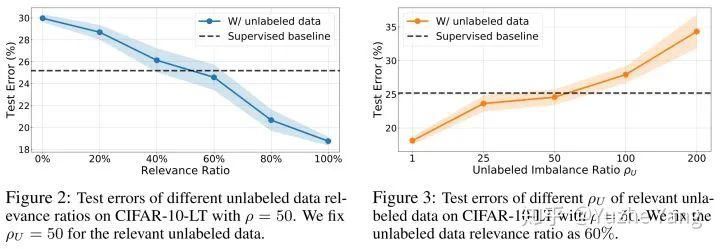
文章插图
上述问题在某些特定的实际不平衡学习任务中,可能是非常普遍的。比如医疗/疾病诊断的应用,对于可能获得的无标记数据,其绝大多数大概率也都是从正常样本上采集的,这首先造成了数据的不平衡;其次,即使是患病的样本,也很可能由很多其他混杂因素(confounding factors)导致,而这会降低与本身研究病症的相关性。
- 责令|1336款APP被责令整改,三大问题突出
- iPhone12|“果粉”心灰意冷,苹果iPhone12问题频出,老毛病又犯了
- 体验|vivo的OriginOS怎么样?体验报告来袭:虽惊艳但核心问题未解决
- 退费|女子公众号上买菜,出现问题时已充上万元,公司:我们没有退费规矩
- 大叔|大叔买电脑被坑惨了,电脑三天两头出问题,老板:组装电脑容易坏!
- 榜眼|中转/运输延误问题集中 榜眼之争仅“1亿票”之差
- 屏幕|太让人气愤了!关于iPhone12出现的“两大问题”,苹果表明态度!
- 用于|用于半监督学习的图随机神经网络
- 新范式|凭借10亿+农业数据 布瑞克破解“农周期”问题 | 滞销农产品
- 解决问题|新业态应成为劳动权益保护高地