监督|长尾问题太严重?半监督和自监督就可以有效缓解!( 二 )
迁移学习(transfer learning):这类方法的基本思路是对多类样本和少类样本分别建模,将学到的多类样本的信息/表示/知识迁移给少类别使用。代表性文章有[13][14]。
度量学习(metric learning):本质上是希望能够学到更好的embedding,对少类附近的boundary/margin更好的建模。有兴趣的同学可以看看[15][16]。
元学习/域自适应(meta learning/domain adaptation):分别对头部和尾部的数据进行不同处理,可以去自适应的学习如何重加权[17],或是formulate成域自适应问题[18]。
解耦特征和分类器(decoupling representation & classifier):最近的研究发现将特征学习和分类器学习解耦,把不平衡学习分为两个阶段,在特征学习阶段正常采样,在分类器学习阶段平衡采样,可以带来更好的长尾学习结果[5][6]。这也是目前的最优长尾分类算法。
至此大概总结了研究背景和常用方法;然而,即使有如数据重采样或类平衡损失等专门设计的算法,在极端的类别失衡下,深度模型性能的下降仍然广泛存在。因此,理解类别不均衡的数据标签分布所带来的影响是非常重要的。
我们的研究动机和思路
不同于之前对于长尾分布研究方法,我们从“the value of labels”,即这些本身就不平衡的数据标签具有的“价值”这一思路去考虑。与理想情况下平衡的标签不同,这些不平衡的数据标签存在一个非常有趣的dilemma。
一方面,这些标签提供了非常珍贵的监督信息。有监督的学习通常都比无监督的学习在给定任务上具有更高准确性,因此即使不平衡,这些标签也拥有“正面价值”。
但是另一方面,由于标签非常不平衡,训练模型的过程中可以非常自然的强加上label bias,从而使得最后的决策区域很大程度上被major class影响;这样的结果又证明了不平衡标签的“负面价值”。
作为总结,在不平衡的训练集中,这些标签就像一把双刃剑;想要得到更好的结果,一个非常重要的问题就是如何最大程度的利用不平衡标签的“价值”?
于是,我们尝试系统性的分解并且分别分析上述两种不同的角度。我们的结论表明对于正面的和负面的角度,不平衡标签的价值都可被充分利用,从而极大的提高最后分类器的准确性:
从正面价值的角度,我们发现当有更多的无标签数据时,这些不平衡的标签提供了稀缺的监督信息。通过利用这些信息,我们可以结合半监督学习去显著的提高最后的分类结果,即使无标签数据也存在长尾分布。
从负面价值的角度,我们证明了不平衡标签并非在所有情况下都是有用的。标签的不平衡大概率会产生label bias。因此在训练中,我们首先想到“抛弃”标签的信息,通过自监督的学习方式先去学到好的起始表示形式。我们的结果表面通过这样的自监督预训练方式得到的模型也能够有效的提高分类的准确性。
半监督框架下的不均衡学习
我们首先从半监督的不均衡学习说起,通过一个简单的理论模型分析来建立直观的解释(省去了许多细节;可以直接跳到解释部分),之后展示一些有意思的实验结果。
理论分析:我们先从一个简单的toy example入手。考虑一个不同均值,和,但是相同方差的Guassian mixture模型,我们可以很容易验证其贝叶斯最优分类器为:
因此为了更好的分类,我们希望学习到他们的平均均值
假设我们已有一个在不平衡的训练集上得到的基础分类器以及一定量的无标签的数据,我们可以通过这个基础分类器给这些数据做pseudo-label。令和代表pseudo-label为正和为负的数据的数量。
为了估计,最简单的方法我们可以通过pseudo-label给这些对应的没有标签的数据取平均得到。假设代表基础分类器对于两个类的准确度的gap。这样的话我们推出以下定理: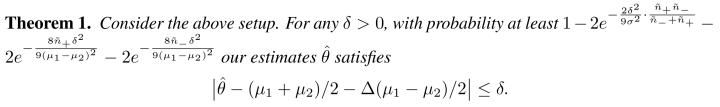
文章插图
那么直观理解,对于这样一个toy example,这个定理告诉了我们以下两点很有意思的结论:
原始数据集的不平衡性会影响我们最后estimator的准确性。越不平衡的数据集我们expect 基础分类器有一个更大的。越大的影响我们的estimator到理想的均值之间的距离。
无标签数据集的不平衡性影响我们能够得到一个好的estimator的概率。对于还不错的基础分类器,可以看做是对于无标签数据集的不平衡性的近似。我们可以看到,当:
,如果无标签数据很不平衡,那么数据少的一项会主导另外一项,从而影响最后的概率。
半监督的不平衡学习框架:我们的理论发现表明,利用pseudo-label伪标签(以及训练数据中的标签信息)可以有助于不平衡学习;而数据的不平衡程度会影响学习的结果。
- 责令|1336款APP被责令整改,三大问题突出
- iPhone12|“果粉”心灰意冷,苹果iPhone12问题频出,老毛病又犯了
- 体验|vivo的OriginOS怎么样?体验报告来袭:虽惊艳但核心问题未解决
- 退费|女子公众号上买菜,出现问题时已充上万元,公司:我们没有退费规矩
- 大叔|大叔买电脑被坑惨了,电脑三天两头出问题,老板:组装电脑容易坏!
- 榜眼|中转/运输延误问题集中 榜眼之争仅“1亿票”之差
- 屏幕|太让人气愤了!关于iPhone12出现的“两大问题”,苹果表明态度!
- 用于|用于半监督学习的图随机神经网络
- 新范式|凭借10亿+农业数据 布瑞克破解“农周期”问题 | 滞销农产品
- 解决问题|新业态应成为劳动权益保护高地