监督|长尾问题太严重?半监督和自监督就可以有效缓解!

文章插图
新智元报道
来源:夕小瑶的卖萌屋
作者:Yuzhe Yang
【新智元导读】论文研究了一个经典而又非常实际的问题:数据类别不平衡下的分类问题。通过理论推导和大量实验发现,半监督和自监督均能显著提升不平衡数据下的学习表现。目前论文已被NeurIPS2020接收,代码已开源。
来给大家介绍一篇最新的工作,目前已被NeurIPS 2020接收:Rethinking the Value of Labels for Improving Class-Imbalanced Learning。
这项工作主要研究一个经典而又非常实际且常见的问题:数据类别不平衡(也泛称数据长尾分布)下的分类问题。我们通过理论推导和大量实验发现,半监督和自监督均能显著提升不平衡数据下的学习表现。
目前代码(以及相应数据,30多个预训练好的模型)已开源,Github链接如下:
https://github.com/YyzHarry/imbalanced-semi-self
那么开篇首先用一句话概括本文的主要贡献:我们分别从理论和实验上验证了,对于类别不均衡的学习问题,利用:
半监督学习 --- 也即利用更多的无标签数据;
自监督学习 --- 不利用任何其他数据,仅通过在现有的不平衡数据上先做一步不带标签信息的自监督预训练(self-supervised pre-training)
都可以大大提升模型的表现,并且对于不同的平衡/不平衡的训练方法,从最基本的交叉熵损失,到进阶的类平衡损失[1][2],重采样[3],重加权[4][5],以及之前的state-of-the-art最优的decouple算法[6]等,都能带来一致的&较大的提升。相信我们从和现有方法正交的角度的分析,可以作为解决不平衡长尾问题的新的思路,其简单和通用性也使得能够很容易和不同方法相结合,进一步提升学习结果。
接下来我们进入正文,我会先抛开文章本身,大体梳理一下imbalance这个问题以及一部分研究现状,在此基础上尽量详细的介绍我们的思路和方法,省去不必要的细节。
研究背景
数据不平衡问题在现实世界中非常普遍。对于真实数据,不同类别的数据量一般不会是理想的uniform分布,而往往会是不平衡的;如果按照不同类别数据出现的频率从高到低排序,就会发现数据分布出现一个“长尾巴”,也即我们所称的长尾效应。大型数据集经常表现出这样的长尾标签分布: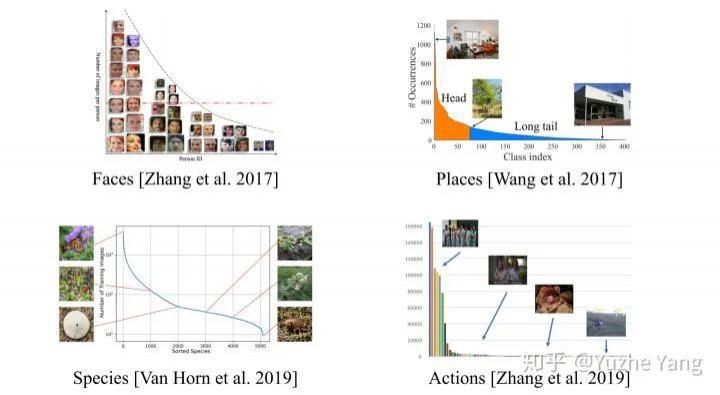
文章插图
不同数据集的标签呈长尾分布。图片来源:
https://liuziwei7.github.io/projects/LongTail.html
当然,不仅仅是对于分类任务,其他任务比如object detection或instance segmentation,常用数据集也存在类别的不均衡。此外,除了视觉领域中的数据,对于涉及安全或健康的关键应用,例如自动驾驶和医疗/疾病诊断,数据本质上也是严重失衡的。
为什么会存在不平衡的现象?其实很好理解,一个通用的解释就是特定类别的数据是很难收集的。拿Species分类来说(参考大型数据集iNaturalist[7]),特定种类(如猫,狗等)非常常见,但是有的种类(如高山兀鹫,随便举的例子...)就非常稀有。
再比如对自动驾驶,正常行驶的数据会占大多数,而真正发生异常情况/存在车祸危险的数据却极少。再比如对医疗诊断,患有特定疾病的人群数相比正常人群也是极度不平衡的。对于healthcare data来说另一个可能原因是和privacy issue有关,特定病人可能都很难采集数据。
那么,不平衡或长尾数据会有什么问题?简单来说,如果直接把类别不平衡的样本丢给模型用ERM学习,显然模型会在major classes的样本上的学习效果更好,而在minor classes上泛化效果差,因为其看到的major classes的样本远远多于minor classes。
那么,对于不平衡学习问题有哪些解决方法?我自己总结的目前主流方法大致分为以下几种:
重采样(re-sampling):更具体可分为对少样本的过采样[3],或是对多样本的欠采样[8]。但因过采样容易overfit到minor class,无法学到更鲁棒易泛化的特征,往往在非常不平衡数据上表现会更差;而欠采样则会造成major class严重的信息损失,导致欠拟合发生。
数据合成(synthetic samples):即生成和少样本相似的“新”数据。经典方法SMOTE[9],思路简单来讲是对任意选取的少类样本,用K近邻选取其相似样本,通过对样本线性插值得到新样本。这里会想到和mixup[10]很相似,于是也有imbalance的mixup版本出现[11]。
重加权(re-weighting):对不同类别(甚至不同样本)分配不同权重。注意这里的权重可以是自适应的。此类方法的变种有很多,有最简单的按照类别数目的倒数来做加权[12],按照“有效”样本数加权[1],根据样本数优化分类间距的loss加权[4],等等。
- 责令|1336款APP被责令整改,三大问题突出
- iPhone12|“果粉”心灰意冷,苹果iPhone12问题频出,老毛病又犯了
- 体验|vivo的OriginOS怎么样?体验报告来袭:虽惊艳但核心问题未解决
- 退费|女子公众号上买菜,出现问题时已充上万元,公司:我们没有退费规矩
- 大叔|大叔买电脑被坑惨了,电脑三天两头出问题,老板:组装电脑容易坏!
- 榜眼|中转/运输延误问题集中 榜眼之争仅“1亿票”之差
- 屏幕|太让人气愤了!关于iPhone12出现的“两大问题”,苹果表明态度!
- 用于|用于半监督学习的图随机神经网络
- 新范式|凭借10亿+农业数据 布瑞克破解“农周期”问题 | 滞销农产品
- 解决问题|新业态应成为劳动权益保护高地