图 4 与现有音频驱动的人脸视频生成方法的定性比较结果
如图4,图5,图6所示,我们与现有音频驱动的人脸视频生成方法进行比较。相比之下,通过显式和隐式属性的协同学习,我们的方法生成具有个性化的头部运动,考虑到不同个体的运动特性,同时可以生成更加逼真眨眼信息的人脸视频。(详细的比较结果请参考上述的视频链接)

文章插图
图 5 与 Vougioukas,Chen等方法的定性对比

文章插图
图 6 与 Suwajanakorn,Thies等方法的定性对比
我们同时通过定量化分析实验,如关键点运动偏移,视听同步置信度进行衡量,具体信息如表1所示。本文所提出的联合隐式和显式属性生成框架,超越了大多数现有方法,在各项属性生成任务中,均具有较优的解析质量。

文章插图
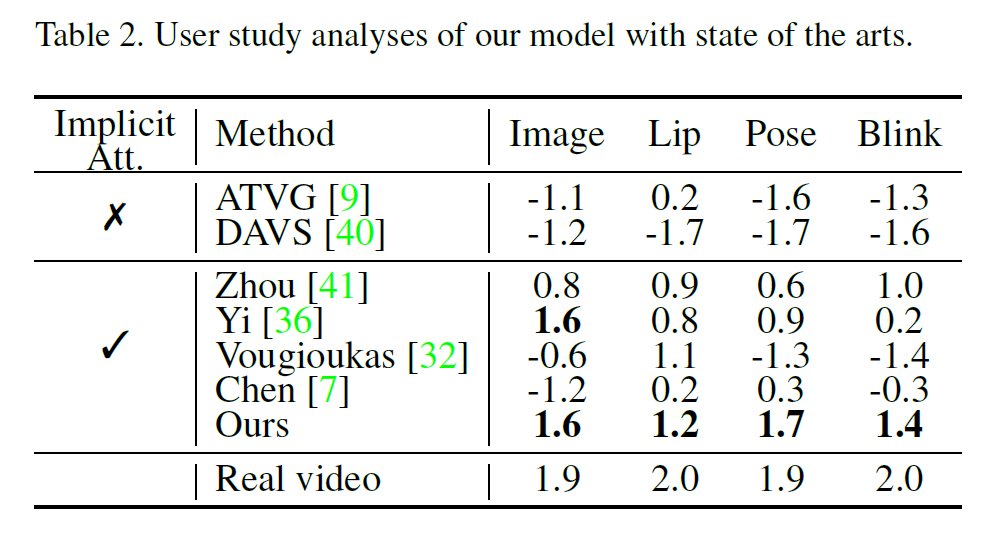
如表2所示,我们通过进行主观的用户研究(User Study),即从人类观察的角度比较生成的结果,其中更大的数值代表更优的生成质量和用户认可度。
文章插图
在这项工作中,除传统的唇部运动等显式属性之外,我们以自然头部姿势和眨眼信息等隐式属性作为学习目标,优化谈话人脸视频的生成质量和真实度。但需要注意的是,人脸谈话视频仍然具有其他更细节的隐式属性,例如,眼球运动、身体和手势、微表情等等。这些属性可能受其他更深层次维度信息的引导,可能需要其他网络组件的特定设计,仍有待于未来进一步探究。我们希望本文提出的FACIAL 框架可以为未来探索隐式属性学习提供一种新颖的研究思路和启发。
[1] Lele Chen, Ross K Maddox, Zhiyao Duan, and Chenliang Xu. Hierarchical cross-modal talking face generation with dynamic pixel-wise loss. CVPR, 2019.[2] Hang Zhou, Yu Liu, Ziwei Liu, Ping Luo, and Xiaogang Wang. Talking face generation by adversarially disentangled audio-visual representation. AAAI, 2019.[3] Supasorn Suwajanakorn, Steven M Seitz, and Ira Kemelmacher-Shlizerman. Synthesizing obama: learning lip sync from audio. TOG, 2017.[4] Justus Thies, Mohamed Elgharib, Ayush Tewari, Christian Theobalt, and Matthias Nie?ner. Neural voice puppetry: Audio-driven facial reenactment. ECCV, 2020.[5] Ran Yi, Zipeng Ye, Juyong Zhang, Hujun Bao, and Yong-Jin Liu. Audio-driven talking face video generation with natural head pose. arXiv preprint arXiv:2002.10137, 2020.[6] Yang Zhou, Xintong Han, Eli Shechtman, Jose Echevarria, Evangelos Kalogerakis, and Dingzeyu Li. Makelttalk: speaker-aware talking-head animation. TOG, 2020.雷锋网雷锋网雷锋网