FICCV 2021 | audi

文章插图
作者 | 张晨旭
编辑 | 王晔
本文是对发表于计算机视觉领域的顶级会议 ICCV 2021的论文“FACIAL: Synthesizing Dynamic Talking Face with Implicit Attribute Learning(具有隐式属性学习的动态谈话人脸视频生成)”的解读。
文章插图
作者:张晨旭(德克萨斯大学达拉斯分校);赵一凡(北京航空航天大学);黄毅飞(华东师范大学);曾鸣(厦门大学);倪赛凤(三星美国研究院);Madhukar Budagavi(三星美国研究院);郭小虎(德克萨斯大学达拉斯分校)。
归纳总结上述两种不同类型的属性,我们称第一类属性为显式属性,第二类为隐式属性。
文章插图
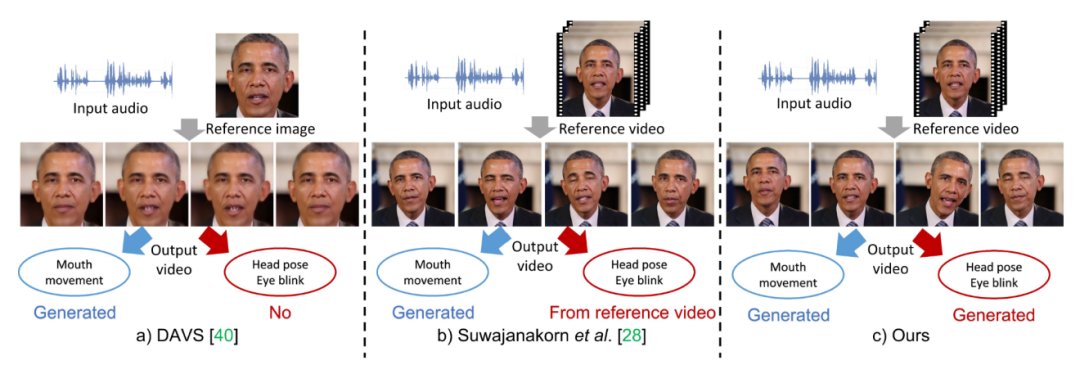
尽管这些工作针对生成属性进行了不同侧面的探究,但是对这些属性的具体研究,仍存在以下问题:(1)显式和隐式属性如何潜在地相互影响?(2) 如何对隐式属性进行建模?例如头部姿势和眨眼等属性不仅取决于语音信号,还取决于语音信号的上下文特征以及与个体相关的风格特征。
文章插图
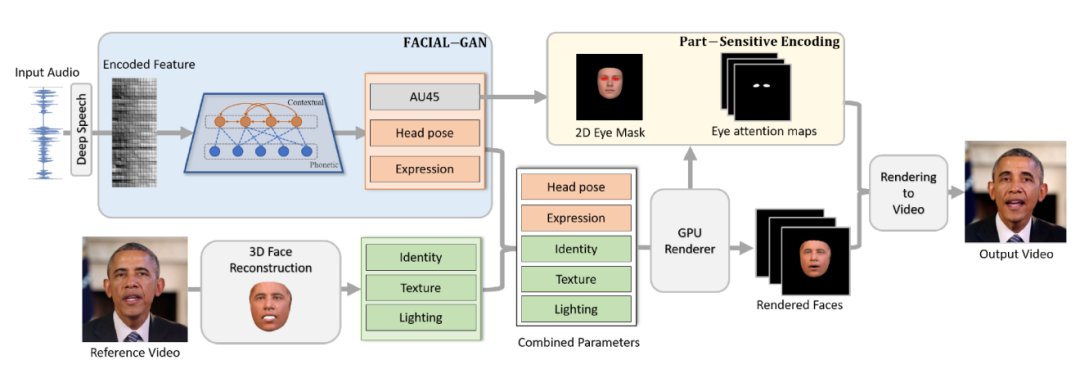
如图2所示,我们提出了一个人脸隐式属性学习(FACIAL)框架来合成动态的谈话人脸视频。
(1)我们的 FACIAL 框架使用对抗学习网络联合学习这一过程中的隐式和显式属性。我们提出以协作的方式嵌入所有属性,包括眨眼信息、头部姿势、表情、个体身份信息、纹理和光照信息,以便可以在同一框架下对它们用于生成说话人脸的潜在交互进行建模。
(2) 我们在这个框架中设计了一个特殊的 FACIAL-GAN网络来共同学习语音、上下文和个性化信息。这一网络将一系列连续帧作为分组输入并生成上下文隐空间向量,该向量与每个帧的语音信息一起由单独的基于帧的生成器进一步编码。因此,我们的 FACIAL-GAN 可以很好地捕获隐式属性(例如头部姿势等)、上下文和个性化信息。
(3) 我们的 FACIAL-GAN 还可以预测眨眼信息,这些信息被进一步嵌入到最终渲染模块的眼部相关的注意力图中,用于在输出视频合成逼真的眼部运动信息。实验结果和用户研究表明,我们的方法可以生成逼真的谈话人脸视频,该生成视频不仅具有同步的唇部运动,而且具有自然的头部运动和眨眼信息。并且其视频质量明显优于现有先进方法。
文章插图
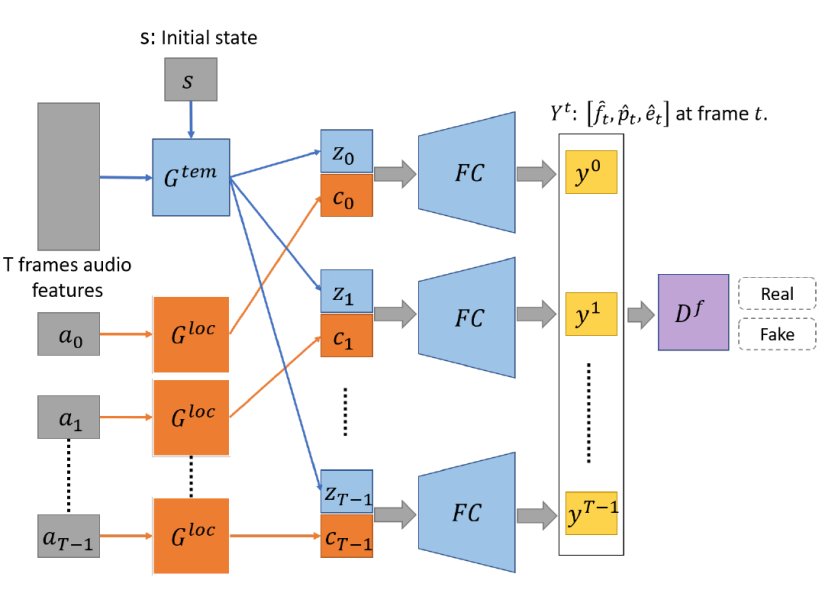
如图3所示,FACIAL-GAN 由三个基本部分组成:时间相关生成器用于构建上下文关系和局部语音生成器用于提取每一帧特征。此外,使用判别器网络来判断生成的属性的真假。(具体的网络细节请参考原文内容)
- 华为鸿蒙系统|都2021年底了,为何Mate40Pro还是目前公认最好用的“安卓”手机
- 杜比|2021年度排名TOP5的网络机顶盒,买哪个最靠谱?
- 荣耀|建议收藏!2021年底盘点:这三款旗舰可以让你安逸地使用两三年
- 电池|2021年年底买千元机,这四款用三五年没问题,十二月购机必看
- 裁员|2021互联网公司裁员汇总:裁员的时候,没有一片雪花是无辜的
- realme|盘点2021年最受好评的四款智能手表,双十二这样买不会出错
- OPPO|2021骁龙技术峰会上OPPO高管爆猛料 Find X系列新品明年一季度见
- 国企网|全力冲刺12月,中广欧特斯空气能实力收官2021
- 荣耀|荣耀60系列详细评测:2021手机颜值天花板实锤了
- 社交网络|2021年手机颜值天花板,就这?