小鱼|可用性测试你不知道的Buff( 六 )
(6)可量化
对于问题的答复最好进行量化处理,而不是单纯的是或否,目的在于可使用高效的统计学方法来理解结果,或进行对比,亦或是数据可视化体现更加精密的差异。
所以说开发或调整一套标准可用的度量问卷也是一门富有学问的技术活,并非简单问几个问题这么简单。
2. 任务后评估问卷(ASQ)也叫场景后问卷,一般在可用性测试完毕后进行,它可以直观的在任务难度、完成效率和帮助信息上获取到测试者的直接反馈,主要就固定三道题目,答案采用5分制或7分制,所得分除以总分即可得到一个均分,该分值至少要大于0.6才能合格,要获得大部分人满意或认可,则要高于0.7。

文章插图
3. 系统可用性问卷(SUS)SUS总共10题,奇数项是正面描述题,偶数项是反面描述题,答题采用奇数的5分制。SUS益于它正反向问题结合,以及具有泛应用的可用性与易用性题型,在业内具有大量应用数据为基础,不论是客观性、灵敏度、可量化还是信度都具有较高的水准,这也是SUS能够成为可用性测试后问卷最主流的原因。

文章插图
(1)SUS量化分数计算
在SUS的相关创建者经过对大批数据的研究,其中可用性部分量表信度为0.91,易学性部分可行度为0.7,为使得整体量表得分兼容在0~100的范围,最终需要对可用性量表总分乘以3.125,易学性量表总分乘以12.5。而经过长期的应用迭代,最终分数的计算方式进行了定格:
- 步骤一:所有奇数编号题目得分减一后相加;
- 步骤二:所有偶数编号题目得分由五减去后相加;
- 步骤三:将奇数项最终得分+偶数项最终得分后 乘以2.5 即最终SUS得分。
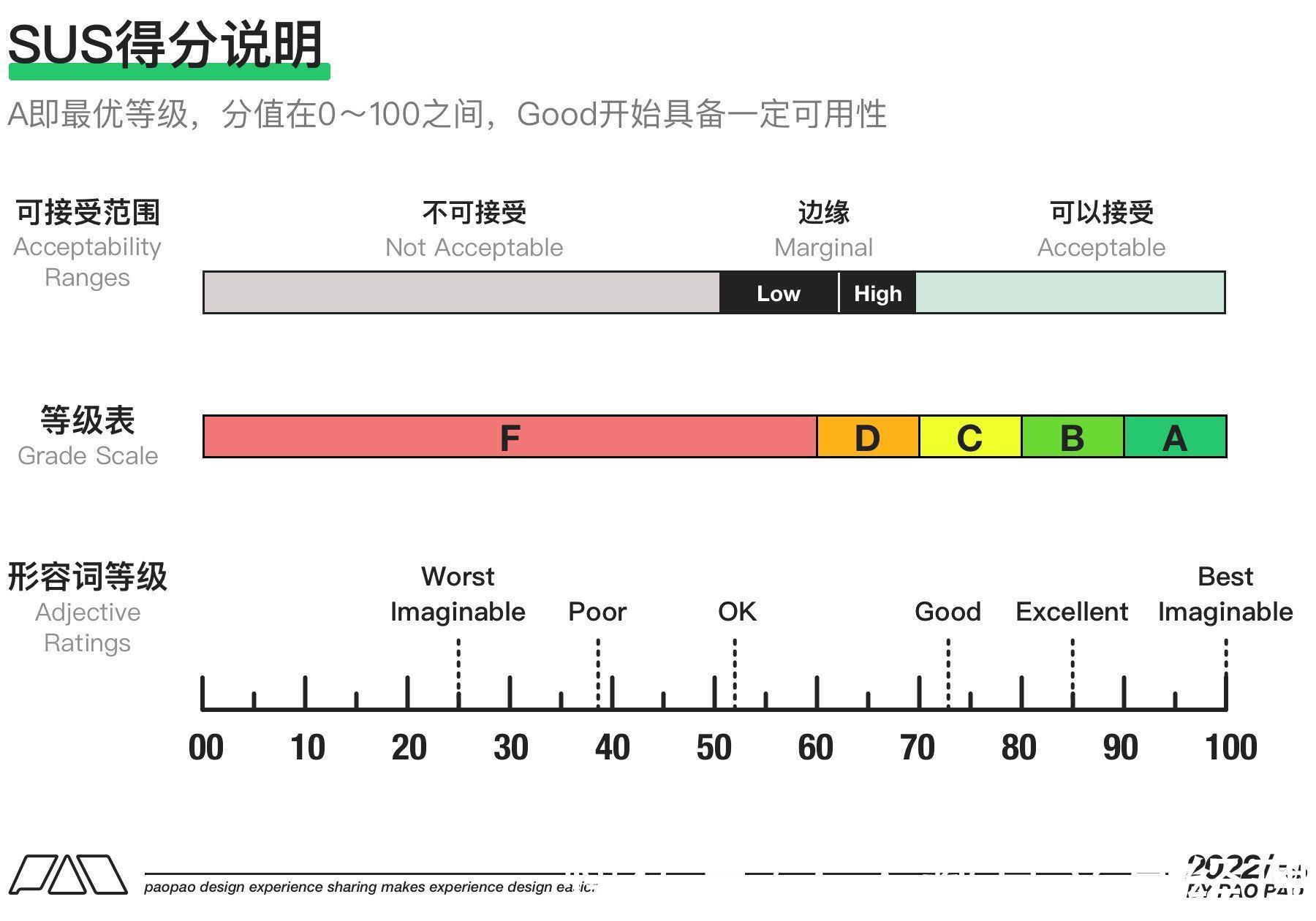
在经过创建者的研究与沉淀,最终构成了5层不同级别的评级,A即最优评价,并且对应0~100分,有趣的是5个评级并非是将100分平分,为了解释评级与得分的强关联性,创建者新增了第11题进行整体而言的数据收集与分析,最终得到了以下图中所对应的关系。
如果说结果是“Good(C)”,那么对应的平均分值则是“71.4”,如果说你的得分高于85.5分,那你的评级则处于“Excellent(B)”,这可能已经意味着你的产品优于绝大部分产品了。
文章插图
4. 网站分析和测量表(WAMMI)WAMMI的建立是为了专门量化网站产品的,该问卷一共20道问题,采用5分制回答,整体信度高于0.9,但是吸引力、可控性、效率、帮助性、易学性多个因子测试信度只在0.63~0.74,因此该问卷对测试样本要求不少于30个。
若该产品属于学术或专业性较强类型,则样本量不少于100个,平均分值为50分,总分100分,但是也受样本量影响,WAMMI很难在可用性测试场景后使用,不过它的问题可以在小型可用性测试中进行应用或自检。
WAMMI官网:http://www.wammi.com/index.html

文章插图
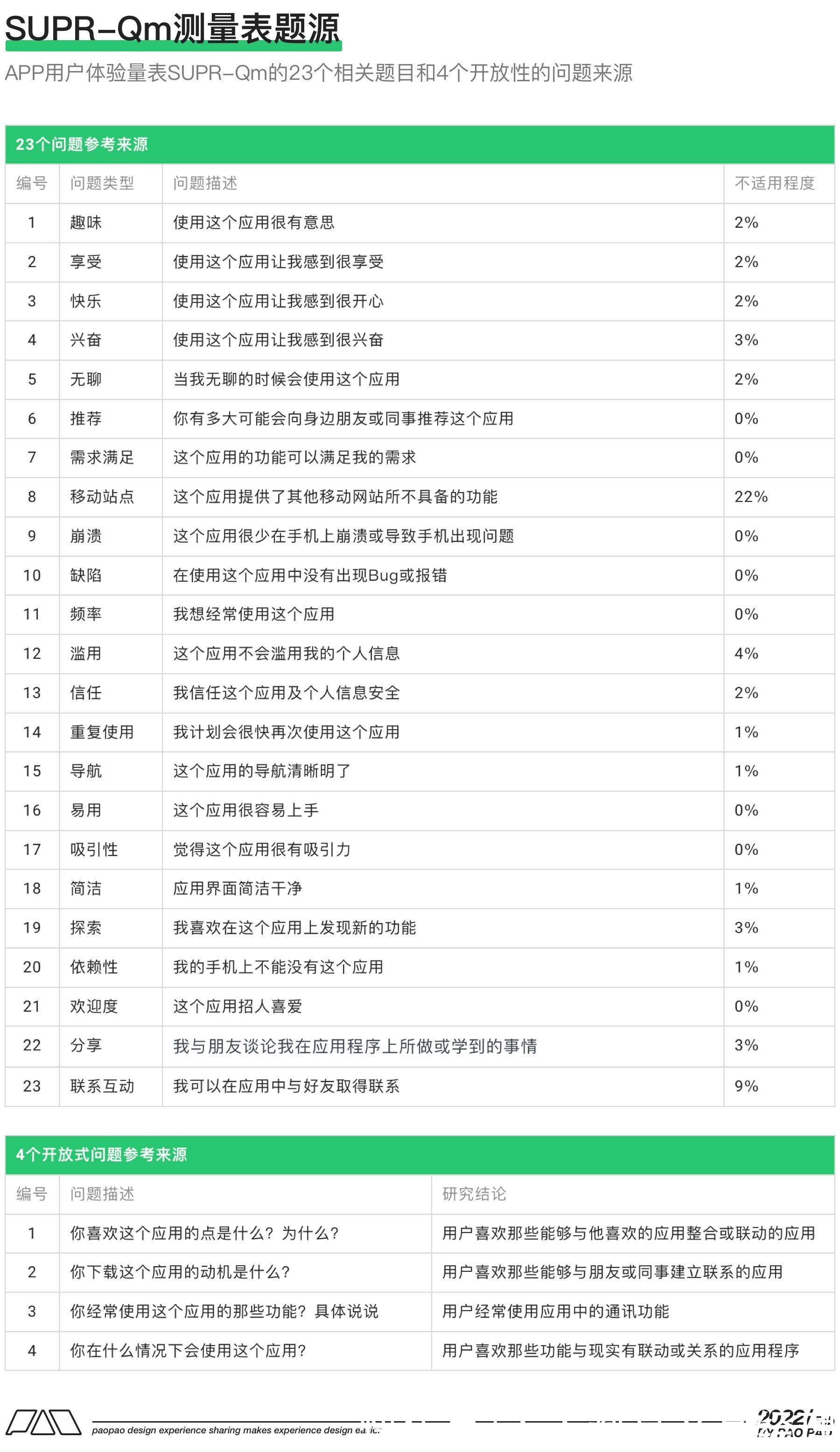
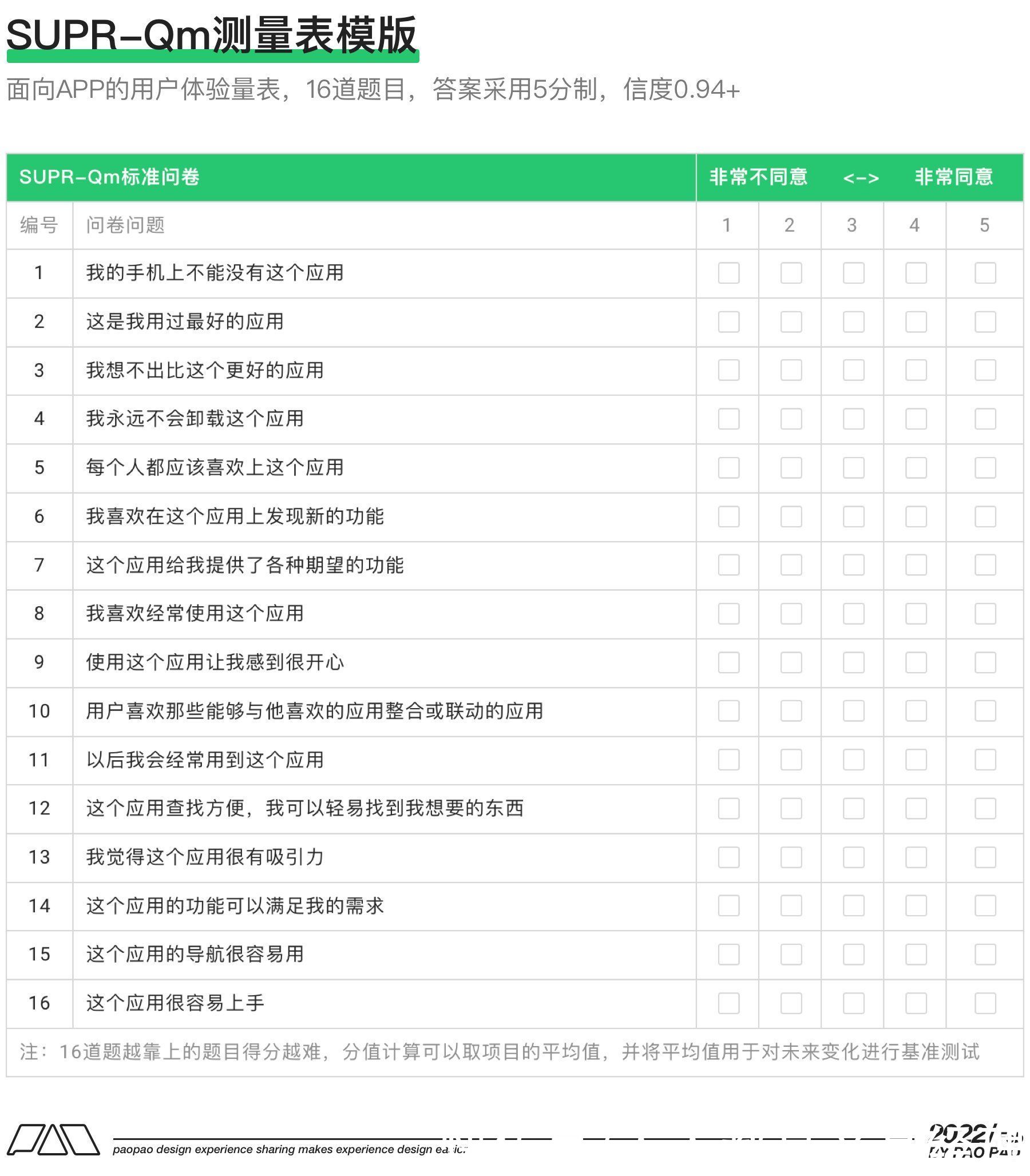
5. APP用户体验量表(SUPR-Qm)作为一个APP用户体验量表,涵盖了更多的体验度量面,而不仅仅是衡量了可用性(比如SUS),并且可以在可用性测试期间或可用性测试之外进行,也可以与其他问题混合使用以便于测量某些特殊产品(如游戏)的用户体验,同时它的信度也高达0.94,SUPR-Qm一共16道问题,采用传统的5分制李克特反应选项。
SUPR-Qm的16道题原本来至23个其他相关文献中的题目和4个开放性的问题,经过不断测试验证和减少冗余后,留下的16个具有单维的、可靠的、有效的、兼容强的问题。
SUPR-Qm原博客说明:https://uxpajournal.org/supr-qm-measure-mobile-ux/
文章插图
文章插图
6. 关于测试结果汇报有些同学一直不清楚可用性测试报告要写些什么,有无固定格式,其实报告没有什么特别的地方,简言之就是将测试的目的、测试过程、测试结果进行整理汇报并反馈优化意见而已。
其中大部分内容没有硬性的格式要求,看起清晰易懂是重点,你可以是文档汇报也可以是PPT汇报,另外记得测试汇报讲究真实性,可以把测试过程中的照片或截图等放进去用于佐证。
另外就是测试结果的归档,我们通常会借助表格的形式来呈现,这样能够更好的将信息整合。
- 微软|微软 Win11 桌面贴纸功能上手体验:可自定义图案、调整大小
- 维信诺|Windows 11新预览版大幅改进蓝牙易用性
- 4k|游戏玩家不可错过的几款电竞显示器,画面更真实更好看
- 单词|不拆分单词也可以做NLP,哈工大最新模型在多项任务中打败BERT
- 资本围猎虚拟人:腰缠万贯,无家可归|36氪新风向 | 虚拟偶像
- 爱好者|颠覆短途旅行新玩法,「样可露营」提供精致露营一站式体验
- 新作|致敬《神奇宝贝》初代!宝可梦新作来了
- 中国经济导报|小黄狗环保科技:做可持续公益的倡导者和践行者
- OPPO|不足2200元,可以买到高刷屏平板电脑,荣耀OPPO该选谁?
- 滴滴出行|柳青、程维可能也没料到,新规定正式出炉,滴滴不想看到这个结果