小鱼|可用性测试你不知道的Buff( 五 )
文章插图
相信说到这里,怎么做好一轮小型可用性测试已经了解了,当你完成了这些测试任务,一定记得不要忘了后续的反思与优化迭代,甚至制定后续的研究计划。
七、多版本方案如何可用性测试有时候设计产生多个版本也是在所难免的,那么对于多方案是应该将内部推荐的拿出来测试,还是应该直接两个版本一起拿出来,两个一起会不会因为采集量过少不准确呢?
这里我们再说说有多个版本怎么做好测试计划与分配,当有多个版本准备可用性测试时,如何制定测试计划还要看版本数量、版本差异化这两大维度,力争做好有效且不费力。
如果说在设计过程中产生的多个版本差异不大,那么都进行测试的必要性我认为不大,通过在商业价值与用户体验间做衡量,选择一个更加符合产品阶段的方案进行可用性测试即可。
但是如果多个版本差异较大,难以决策且不确定性较大,那么第一件事就是经过一轮决策将版本减少到两个左右,然后再进行可用性测试,对于此类情况基本上有两种方法进行分配测试;
1. 将版本分为两组进行测试如果说直接分成两组进行可用性测试,那么需要数据样本会更大,数据采集量过少确实会有不准确的可能,因此直接分成俩组进行测试的话,会需要招募更多测试者和测试准备,但同时可能会有意外的惊喜。
往往我们以为的,可能会在测试者那里收获意料之外的反馈,这将允许我们以真实用户的视角去挖掘价值或决策,避免内部短视而埋没了好的设计。
2. 一组人员测试两个版本相比分多组测试,一组人员测试两个版本在成本上会更有优势,但同时会面临两个版本测试的前后顺序影响,要知道第一个版本会对用户形成更多印象,甚至产生一些偏好,所以为减小测试结果的偏差,我们会将测试者分为数量相同的两组,并安排两组不同的先后顺序进行测试来打破僵局。
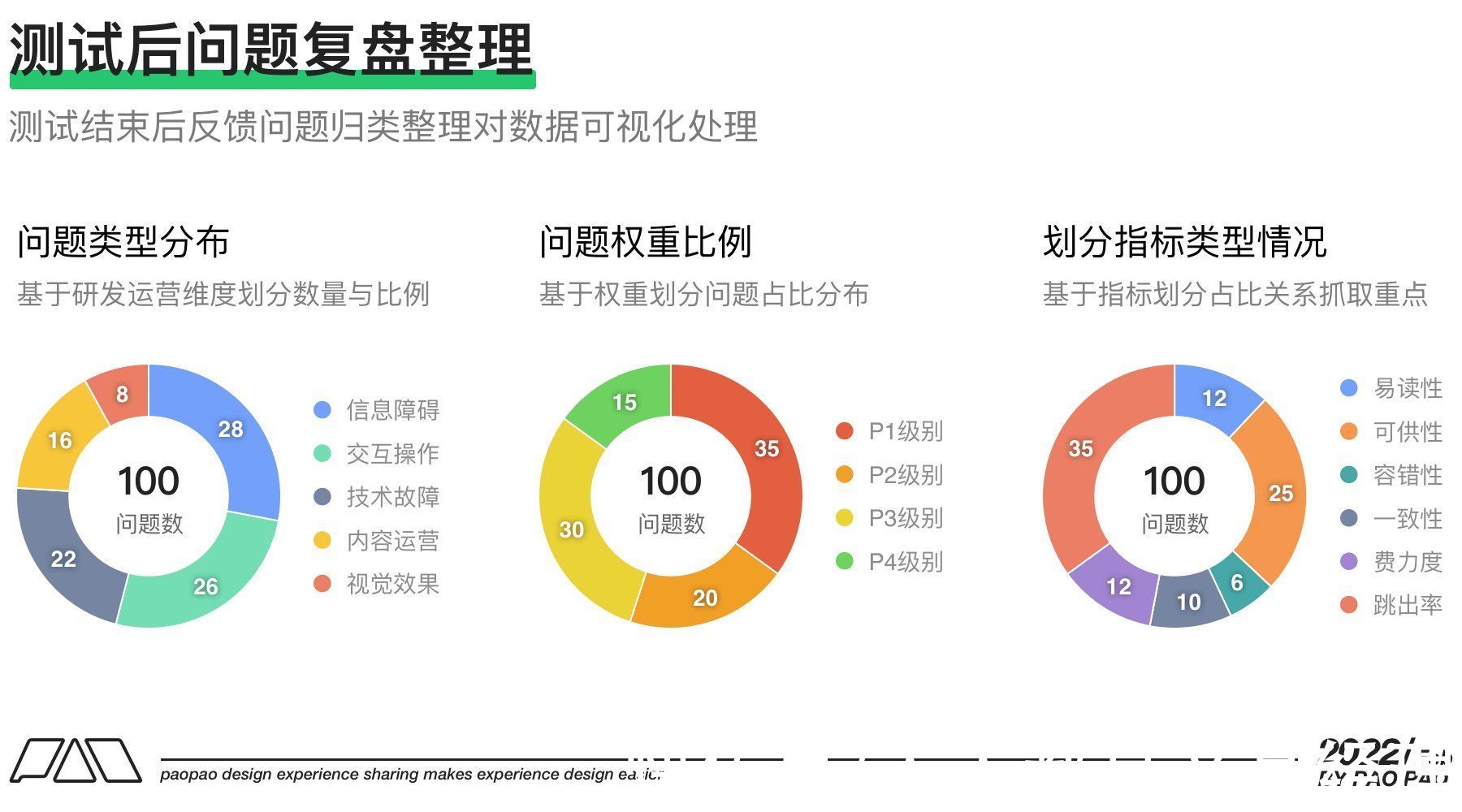
八、测试结果的量化或汇报技巧测试结果量化的目的在于更好的衡量可用性在怎样的一个水准线上,同时便于整理复盘整个测试过程,并将结果更加直观的展现出来,便于同事们了解。对于测试结果量化有两个方面;
一方面是将整个测试过程中收集到的各种问题反馈进行分类整理,并用数据图表现出来,这样能够很直观的展现问题缺陷与突破口,同时能够快速体现测试价值,或者说你进行可用性测试为业务带来的价值。
文章插图
另一方面则是通过面向用户的问卷调查获取可用性测试量表,最常见的标配问卷即ASQ(任务后评估问卷)与SUS(系统可用性问卷)。
除此之外还有专门面向网站产品的WAMMI(网站分析和测量表)、SUPR-Q(标准通用的百分等级量表,但是获取有效的百分比数据需要购买服务,所以不额外介绍了,有兴趣的自己百度下),以及面向APP使用体验的SUPR-Qm(APP用户体验量表),在说明这些量化表怎么使用和定义前,我需要额外说明一些量化表的概念,这很重要!
1. 可用性测试量表标准作为一个合格的标准化量表至少需要保障以下几点:
(1)可信度
对同一对象测量得到的结果是否一致,这将直接决定问卷获取的结果是否能可靠,可以通过重复测量信度和分半信度测量, 测量出的信度会在0~1之间,越是接近1的可信度越高,因为量化结果会被直接引用,所以信度至少高于0.7才比较有意义,不然一个半信半疑的结果真的充满风险。
同时以上我提到ASQ、SUS、WAMMI、SUPR-Qm这四个量化问卷也都是经过业内长期试验与验证后信度较高的靠谱问卷模式。
(2)有效度
主要理念在于是否密切关注到了你所在意的问题点,以及问卷问题是否与验证系统有关联性,对于效度也有效标效度(皮尔逊相关系数)和内容效度(因子分析)两种评估方法,不过并不一定要有很高的系数来证明很有效。
(3)灵敏度
指达到统计显著性所需的最小样本量,例如一个水果偏好二选一问卷,你问两个人可能是答案A,但是你问完10个人后却是B,当采量过小没能达到统计显著性所需最小样本量时,可能会获得不够准确的答案。
(4)客观性
一份问卷应该保持客观性,不能携带编辑者的个人偏好或主观意愿影响,这会让问卷有失统一性。
(5)重复性
尽可能的使问卷框架结构能够复用,一方面便于更多人可以研究验证,另一方面可以使得问卷本身价值最大化。
- 微软|微软 Win11 桌面贴纸功能上手体验:可自定义图案、调整大小
- 维信诺|Windows 11新预览版大幅改进蓝牙易用性
- 4k|游戏玩家不可错过的几款电竞显示器,画面更真实更好看
- 单词|不拆分单词也可以做NLP,哈工大最新模型在多项任务中打败BERT
- 资本围猎虚拟人:腰缠万贯,无家可归|36氪新风向 | 虚拟偶像
- 爱好者|颠覆短途旅行新玩法,「样可露营」提供精致露营一站式体验
- 新作|致敬《神奇宝贝》初代!宝可梦新作来了
- 中国经济导报|小黄狗环保科技:做可持续公益的倡导者和践行者
- OPPO|不足2200元,可以买到高刷屏平板电脑,荣耀OPPO该选谁?
- 滴滴出行|柳青、程维可能也没料到,新规定正式出炉,滴滴不想看到这个结果