「观察」云原生数仓,破茧而出( 二 )
我们再从数据的常见载体—数据库做下分析 。 根据我们常见的两类数据应用操作型、分析型及数据结构特征关系型和非关系型 , 我们将数据库产品可按照这两个因素做个分类 。 下面我们重点讨论的是关系型的面对分析场景的产品 , 也就是图中的右上角象限 。 在这一象限内的产品 , 根据其发展特点可以简单分为两类:传统数据仓库和云(原生)数据仓库 。
- 在传统数据仓库领域 , 从右上角图中可见 , 主要是以国外大厂为主 。 这里面包括了IBM、Oracle、HP、SAP、EMC、TeraData等 。 在技术特点上 , 普遍采用了MPP、列存技术;输出形态上有纯软和一体机的方案 。 发展时间上主要集中在2005~2010年前后 。
- 在云(原生)数据仓库领域 , 从右下角可见 , 主要是以新兴云厂商为主 。 这里包括了AWS、Google、Microsoft等公司产品 。 其技术特点上 , 普遍在原有数仓的技术积累之上 , 与云端基础环境结合 , 输出形态为云端产品 。 发展时间上主要集中在2015~年后 。
 文章插图
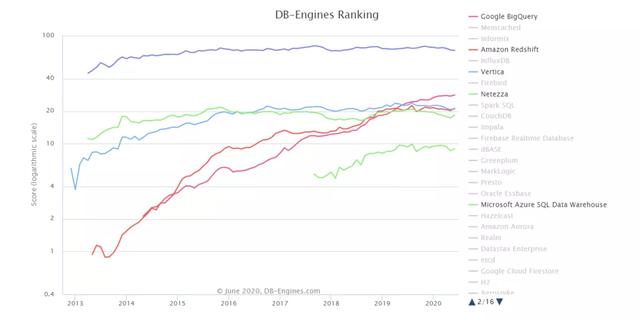
文章插图针对上述两类产品 , 我们做个发展对比 。 下图是根据db-engines网站数据所得 。 这一网站的数据库排名 , 是按照搜索引擎搜索量+主流论坛访问量+相关职位招聘量维度 , 反映数据库的受关注程度 。 下图中列出了常见的数据分析产品 , 包括了传统数仓产品Teradata、Vertica(HP)、Netezza(IBM)为代表 , 云数仓产品Redshift(AWS)、BigQuery(Google)、ADW(Microsoft)为代表 。 这两类产品的发展趋势有明显的差异 。 前者的发展比较平稳 , 后者发展更为迅速 。 两者在2020年左右 , 在局部产品上已经出现的交叉 。 也就是说 , 在这一年上 , 对新兴数仓产品的关注程度 , 已高于某些传统数仓产品 。
03 用户场景及需求变化
 文章插图
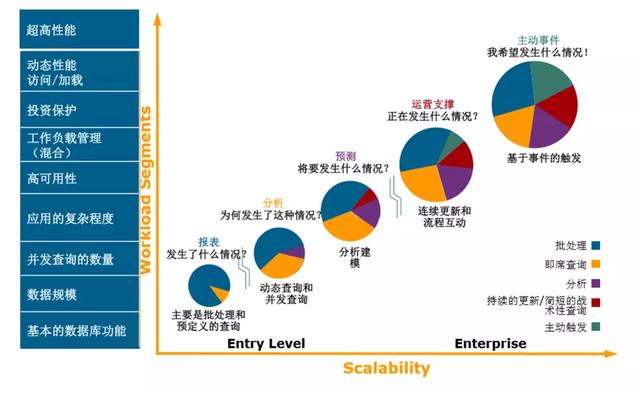
文章插图【「观察」云原生数仓,破茧而出】从客户的使用场景来看 , 也如上图经过了阶段 。
- “报表”阶段
- “分析”阶段
- “预测”阶段
- “运营支撑”阶段
- 「精选」网易严选质量数仓建设(二)—质量数仓项目建设及管理
- 品牌手机内置原生正版壁纸,高清可取
- 从 Storm 迁移到 Flink,美团外卖实时数仓建设实践
- Fluid 0.3 正式发布:实现云原生场景通用化数据加速
- 海哥商业观察|苏宁直播带货为何没有翻车?,店播+直播+服务
- 互联科技观察员|雷军在亚布力企业论坛表示:小米想解决国货被看不起的问题,近日
- 笪屹超人|原生支持5G通信和智能AI交互,欧瑞博发新品全景屏智能中控面板
- 经济观察网|内部数据流程打通带来考验,揭开美的工业互联网2.0面纱:平台架构包含四层能力
- 新互联观察|mini降价500,是小屏不行,还是苹果不行?,iPhone12
- 新互联观察|Pro下架了,小米11要来?除了首发骁龙875,还有啥?,小米10