通过视频着色进行自监督跟踪
方法的实现可以访问链接了解:
目标跟踪概述简单地说 , 它可以理解为在整个视频序列中识别唯一的对象 。 要跟踪的对象通常称为目标对象 , 跟踪可以通过边界框或实例分割来完成 , 有两种类型的公共对象跟踪挑战 。
1. 单目标跟踪:在整个视频序列中跟踪感兴趣的目标 , 例如VOT挑战
2. 多目标跟踪:在整个视频序列中跟踪多个感兴趣的目标 。 例如:MOT挑战
研究趋势一些著名的经典的用于解决目标跟踪CV算法的是:
1. Mean shift
2. Optical flow
3. Kalman filters
其中最著名的一种多目标跟踪算法是SORT , 是以卡尔曼滤波器为核心 , 并且非常成功的一种算法 。
随着深度学习时代的到来 , 社会上出现了非常有创新性的研究并且深度学习方法成功地胜过了传统的CV方法来应对公共跟踪挑战 。 尽管在公共挑战方面取得了巨大成功但深度学习仍在努力为现实世界中的问题陈述提供通用的解决方案 。
深度模型的挑战在训练深度CNN模型时 , 我们面临的主要挑战之一是训练数据 。
训练数据:深度学习方法需要大量的数据 , 这几乎每次都会成为一个瓶颈 。 此外 , 像多目标跟踪这样的任务很难注释 , 而且这个过程变得不切实际而且成本高昂 。
 文章插图
文章插图
深度模型数据永远不嫌多
用自监督学习来拯救我们都知道有监督和非监督学习技术 。 这是一种被称为自监督学习的新型学习方式 。 在这些类型的学习中 , 我们试着利用数据中已经存在的信息 , 而不是任何外部标签 , 或者有时我们说模型是自己学习的 。 实际上 , 我们所做的就是训练CNN模型去完成一些其他的任务 , 间接地帮助我们实现我们的目标 , 这个模型自我监督 。 这些任务被称为“代理任务”或“借口任务” 。
代理任务的示例如下:
- 颜色化
 文章插图
文章插图CNN模型学习从灰度图像预测颜色 。 (来源:)
- 将图像补丁放在正确的位置
 文章插图
文章插图从图像中提取补丁并将其打乱 。 模型学习如何解开拼图并按照正确 的顺序排列 , 如图3所示 。 (来源:)
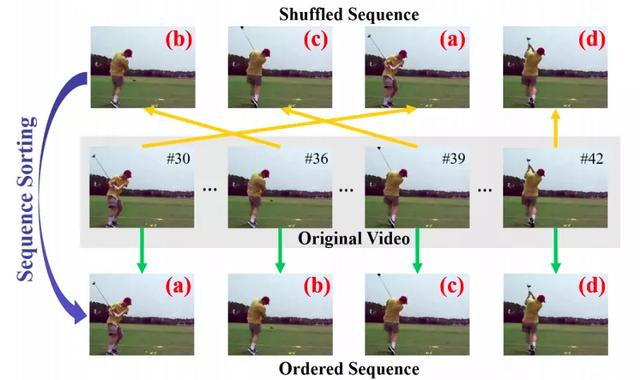
- 按正确的顺序放置视频帧
 文章插图
文章插图该模型学习在视频序列中对打乱的帧进行排序 。 [来源:]
许多这样的任务可以用作计算机视觉问题的代理任务 。 这种训练的一个主要好处是训练不需要手动注释数据 , 并且适合解决生活中实际的用例 。
通过视频着色进行自监督跟踪我们已经看到了并了解了什么是自监督模型 , 您一定猜到了我们将使用着色作为我们的代理任务的名称 。
通过给视频着色来实现跟踪
我们使用大量未标记视频学习模型的视觉跟踪无需人工监督 。
arxiv.org()
简介
着色是代理任务或借口任务 , 目标跟踪是主要任务或下游任务 。 采用大规模的无标记视频对模型进行训练 , 不需要人工进行任何单一像素的标注 。 该模型利用视频的时间相干性对灰度视频进行着色 。 这看起来可能有点混乱 , 但我会慢慢给大家讲明白 。
模型将如何学习跟踪
我们将取两个帧 , 一个目标帧(时刻t) , 一个参考帧(时刻t-1) , 并通过模型 。 该模型期望通过对参考帧颜色的先验知识来预测目标帧的颜色 。 通过这种方式 , 模型内部学会了指向正确的区域 , 以便从参考框架复制颜色 , 如图所示 。 这种指向机制可以用作推理期间的跟踪机制 , 我们将很快看到如何做到这一点 。
- Dubai视频通话
- 对微前端的11个错误认识
- 看了PS5的拆机视频,下世代主机最重要的配件可能是空调
- 国务院通过最新规划,新能源汽车新风口定了
- 全球首个交互式全息视频显示器问世 有望嵌入智能手机
- MakerBot宣布通过尼龙12碳纤维扩大其材料供应范围
- 今天才知道,原来手机就能给视频添加字幕,手把手教会你
- 今天才发现,原来用微信拍视频还能添加字幕,既简单又好玩
- 高通骁龙888登场,雷军录祝贺视频并抢下全球首发,华为不能用
- BBC:为了应对气候变化,看视频时不要选“高清模式”