「观察」云原生数仓,破茧而出
近期参加墨天轮社区活动 , 介绍数据分析(仓库)领域的一些变化趋势及新一代(基于云原生架构)数仓的出现如何解决现有数仓痛点 。 就在前两天 , 相信很多数据圈的朋友都被一条消息刷屏 。 云原生数仓的代表性企业-snowflake上市 , 市值高达700亿美金 , 惊爆眼球 。 其市值甚至达到老牌数仓领导性企业-Teradata的近30倍 。 缘何“云原生”概念如此火爆?正是人们看到这种新形态的巨大前景 。 下文根据分享内容整理而成 , 仅代表个人观点 。
01 数据趋势变化分析
 文章插图
文章插图
新时期下 , 数据的存储计算上正悄然发生一些变化 。 从近期IDC、Gartner披露的数据来看 , 整体呈现出下列几个特点:
- 数据规模爆炸性增长
- 数据处理实时性增强
- 非结构化数据被更广泛运用
- 数据正呈现加速上云的趋势
总结一下 , 新时期下数据的存储、计算正在朝着海量、实时、智能、云化的方向发展 。
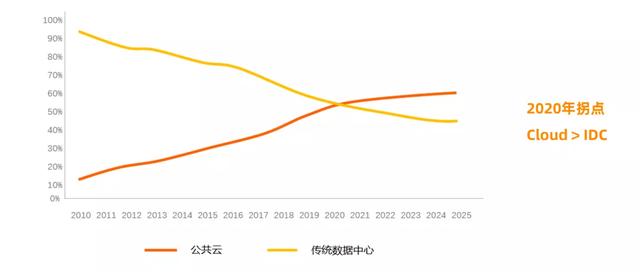 文章插图
文章插图从另一角度 , 也可以印证上面第4个观点 。 此图是同样来自第三方机构 , 数据的存储位置在公有云 , 还是传统的数据中心方式的占比分析 。 从图中可见 , 数据存储在IDC的占比不断下降 , 存储在公有云端的比例不断提升 , 两者在2020年达到一个拐点 , 并预测在此之后会差距会不断增大 。 也就是说 , 未来数据存储在云端是一种常见的方式 。
02 数据仓库产品发展对比
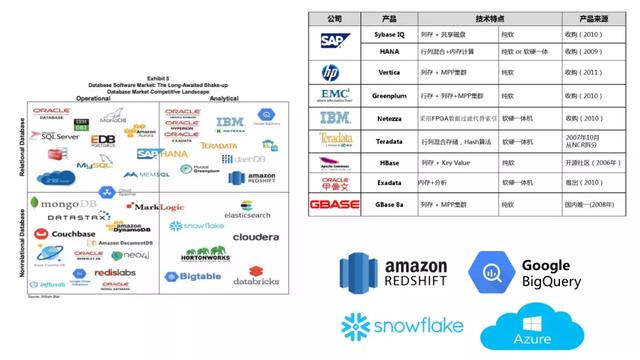 文章插图
文章插图
- 「精选」网易严选质量数仓建设(二)—质量数仓项目建设及管理
- 品牌手机内置原生正版壁纸,高清可取
- 从 Storm 迁移到 Flink,美团外卖实时数仓建设实践
- Fluid 0.3 正式发布:实现云原生场景通用化数据加速
- 海哥商业观察|苏宁直播带货为何没有翻车?,店播+直播+服务
- 互联科技观察员|雷军在亚布力企业论坛表示:小米想解决国货被看不起的问题,近日
- 笪屹超人|原生支持5G通信和智能AI交互,欧瑞博发新品全景屏智能中控面板
- 经济观察网|内部数据流程打通带来考验,揭开美的工业互联网2.0面纱:平台架构包含四层能力
- 新互联观察|mini降价500,是小屏不行,还是苹果不行?,iPhone12
- 新互联观察|Pro下架了,小米11要来?除了首发骁龙875,还有啥?,小米10