Fluid 0.3 正式发布:实现云原生场景通用化数据加速
简介为了解决大数据、AI 等数据密集型应用在云原生计算存储分离场景下 , 存在的数据访问延时高、联合分析难、多维管理杂等痛点问题 , 南京大学 PASALab、阿里巴巴、Alluxio 在 2020 年 9 月份联合发起了开源项目 Fluid。
Fluid 是一款开源的云原生基础架构项目 。 在计算和存储分离的大背景驱动下 , Fluid 的目标是为 AI 与大数据云原生应用提供一层高效便捷的数据抽象 , 将数据从存储抽象出来 , 以便达到:
- 通过数据亲和性调度和分布式缓存引擎加速 , 实现数据和计算之间的融合 , 从而加速计算对数据的访问;
- 将数据独立于存储进行管理 , 并且通过Kubernetes的命名空间进行资源隔离 , 实现数据的安全隔离;
- 将来自不同存储的数据联合起来进行运算 , 从而有机会打破不同存储的差异性带来的数据孤岛效应 。
- 实现通用数据存储加速 , 提供 Kubernetes 数据卷访问加速功能
- 加强数据访问安全保护 , 提供面向数据集的细粒度权限控制功能
- 简化用户复杂参数配置 , 提供原生化系统内部参数配置优化功能
一、支持 Kubernetes 数据卷访问加速
尽管之前版本的 Fluid 已经支持诸多底层存储系统(如 HDFS、OSS 等) , 但在实际生产环境中 , 企业内部的存储系统往往更加多样 , 因存储系统不兼容而无法对接 Fluid 的情况仍然存在 。 例如用户使用 Lustre 分布式文件系统 , 由于之前的 Fluid 所使用的分布式缓存引擎尚不兼容 Lustre 系统 , 因此该用户将无法正常使用 Fluid 。
为了提升 Fluid 在云原生数据访问加速场景的通用性 , Fluid v0.3. 增加了对数据卷 Persistent Volume Claim (PVC) 和主机目录(Host Path)挂载的加速支持 , 从而为各类存储系统与 Fluid 的对接提供了一种通用化加速方案:无论使用哪一种底层存储系统 , 只要该存储系统可被映射为 Kubernetes 原生的数据卷 PVC 资源对象或者集群节点上的主机目录 , 那么它就可以通过 Fluid 享受到如分布式数据缓存、数据亲和性调度等功能特性带来的优势 。 其基本概念如下图所示:
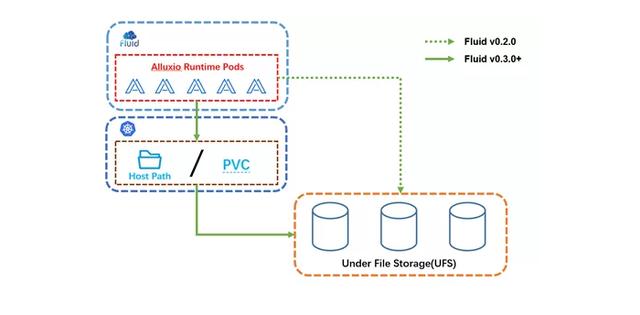 文章插图
文章插图具体使用方法非常简单 , 用户只需在 mountPoint 中指定 pvc://nfs-imagenet , 其中 nfs-imagenet 是 Kubernetes 集群中已有数据卷 。
apiVersion: data.fluid.io/v1alpha1kind: Datasetmetadata:name: fluid-imagenetspec:mounts:- mountPoint: pvc://nfs-imagenetname: nfs-imagenet我们通过 TensorFlow Benchmark 训练 ResNet-50 模型为测试场景 , 验证了 PVC 访问加速能力 , 以下是速度提升结果: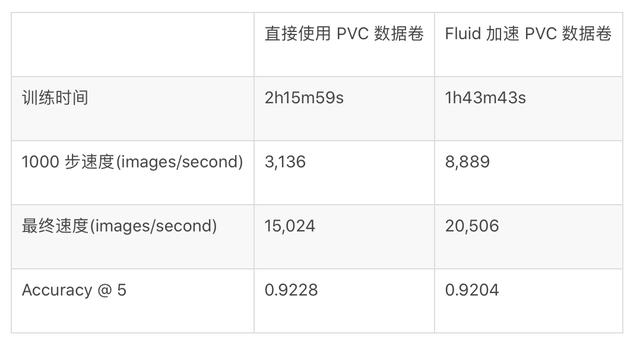 文章插图
文章插图从评估结果来看 , Fluid 所提供的分布式缓存能力都能够提升整个训练任务的速度 , 缩短整体训练时间超过 20% 。
二、数据集的访问权限控制
很多提供机器学习平台服务的企业存在多用户共享存储系统情况和场景 。 出于安全性考虑 , 机器学习平台服务提供商需要进行严格的访问权限控制以保障用户之间的数据隔离性 , 即任何未经授权的用户不得随意访问他人数据集 。
Fluid 在 v0.3 中提供了对上述场景的支持:多用户共享的底层存储系统挂载到 Fluid 后 , Fluid 暴露出的文件权限信息(如所属用户、文件模式等)将与底层存储系统保持一致 , 即实现了文件从底层存储系统到部署 Fluid 的节点的透传 。 这也就意味着底层存储系统中的访问权限控制同样将在部署 Fluid 的各个节点上生效 , 以此保证用户之间的数据隔离性不被破坏 。
- 三星Note10系列One UI Beta版计划正式推送
- 华为正式宣布!鸿蒙系统确认名单,部分机型无法升级或被淘汰
- Python 3.9 正式发布!一图秒懂新特性
- 百度地图导航路口放大图功能正式登陆特斯拉车机地图 精准导航更进一步
- 中兴通讯正式官宣,系统、芯片一个都不少,150亿没有白花
- 四大银行正式宣布!微信支付宝或将被淘汰,马云也无可奈何?
- vivo昨日放大招了!正式发布OriginOS,国产机的崛起
- “Leonardo”正式发布,美巨头自信满满,任正非说的没错
- 正式确认!“女性机器人”虽然功能性强大,但却不能代替真人
- 6G!苹果正式官宣新决定,有人要慌了