爱可可AI论文推介(10月17日)
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言
1、[CV]*NeRF++: Analyzing and Improving Neural Radiance Fields
K Zhang, G Riegler, N Snavely, V Koltun
[Cornell Tech & Intel Labs]
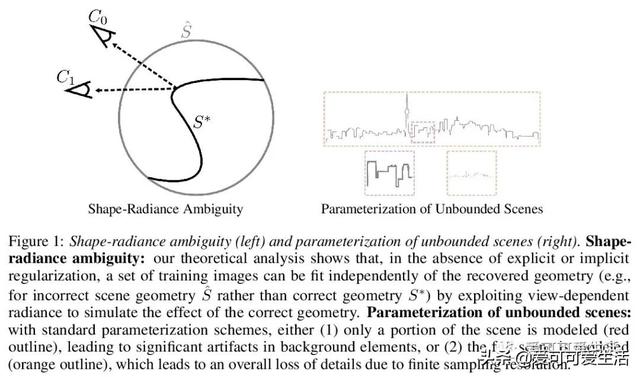
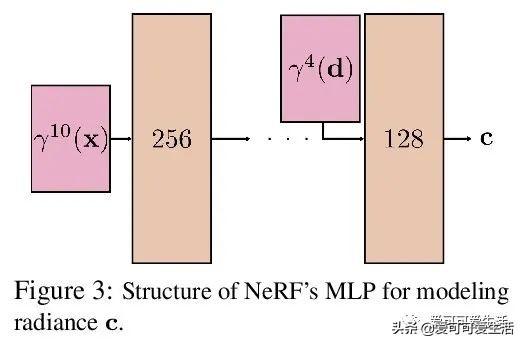
神经辐射场分析与改进(NeRF++) , 讨论了辐射场的潜在歧义 , 即形状-亮度歧义 , 分析了NeRF在避免这种歧义方面取得的成功;解决了将NeRF用于大规模、无边界3D场景360度捕获对象时涉及的参数化问题 , 在这个具有挑战性的场景中提高了视图合成的保真度 。
Neural Radiance Fields (NeRF) achieve impressive view synthesis results for a variety of capture settings, including 360 capture of bounded scenes and forward-facing capture of bounded and unbounded scenes. NeRF fits multi-layer perceptrons (MLPs) representing view-invariant opacity and view-dependent color volumes to a set of training images, and samples novel views based on volume rendering techniques. In this technical report, we first remark on radiance fields and their potential ambiguities, namely the shape-radiance ambiguity, and analyze NeRF's success in avoiding such ambiguities. Second, we address a parametrization issue involved in applying NeRF to 360 captures of objects within large-scale, unbounded 3D scenes. Our method improves view synthesis fidelity in this challenging scenario. Code is available at this https URL.
 文章插图
文章插图
 文章插图
文章插图
 文章插图
文章插图
 文章插图
文章插图
 文章插图
文章插图
2、[CL]*Vokenization: Improving Language Understanding with Contextualized, Visual-Grounded Supervision
H Tan, M Bansal
[UNC Chapel Hill]
视觉监督语言模型vokenization , 通过上下文化映射语言词条到相关图像(称为“vokens”) , 将多模态对齐外推到仅包含语言的数据 。 在相对较小的图像描述数据集上训练“vokenizer” , 再用它生成大语言语料库的vokens 。 在这些生成的vokens的监督下 , 在多语言任务上比单纯自监督语言模型有显著改进 。
Humans learn language by listening, speaking, writing, reading, and also, via interaction with the multimodal real world. Existing language pre-training frameworks show the effectiveness of text-only self-supervision while we explore the idea of a visually-supervised language model in this paper. We find that the main reason hindering this exploration is the large divergence in magnitude and distributions between the visually-grounded language datasets and pure-language corpora. Therefore, we develop a technique named "vokenization" that extrapolates multimodal alignments to language-only data by contextually mapping language tokens to their related images (which we call "vokens"). The "vokenizer" is trained on relatively small image captioning datasets and we then apply it to generate vokens for large language corpora. Trained with these contextually generated vokens, our visually-supervised language models show consistent improvements over self-supervised alternatives on multiple pure-language tasks such as GLUE, SQuAD, and SWAG. Code and pre-trained models publicly available at this https URL
- SOTA论文也未必能被接收,谷歌科学家谈顶会审稿标准
- Transformer竞争对手QRNN论文解读更快的RNN
- 滤波器|刷新滤波器剪枝的SOTA效果,腾讯优图论文入选NeurIPS2020
- 前瞻网|建议换CEO?硕士论文研究董明珠自恋:自恋人格导致格力多元化失败
- |四成SCI论文涉嫌大量图片造假,这个作者的PS技术可能有点厉害!
- 可可爱科技|Note20 Ultra引领万物互联,多项黑科技加持,三星Galaxy
- 宽哥玩数码|帮你保持领先地位,回归根基:5篇必读的数据科学论文
- 科技排头|Ps把AI论文demo打包实现了:照片上色、改年龄、换表情
- 小皇可可|实用又容易操作的磁盘管理工具推荐
- 可可酱|T1 Lite评测:iPhone12不送耳机就买它,FIIL