Transformer竞争对手QRNN论文解读更快的RNN
使用递归神经网络(RNN)序列建模业务已有很长时间了 。但是RNN很慢因为他们一次处理一个令牌无法并行化处理 。此外 , 循环体系结构增加了完整序列的固定长度编码向量的限制 。为了克服这些问题 , 诸如CNN-LSTM , Transformer , QRNNs之类的架构蓬勃发展 。
在本文中 , 我们将讨论论文"拟递归神经网络"(arxiv/1611.01576)中提出的QRNN模型 。从本质上讲 , 这是一种将卷积添加到递归和将递归添加到卷积的方法 。
LSTM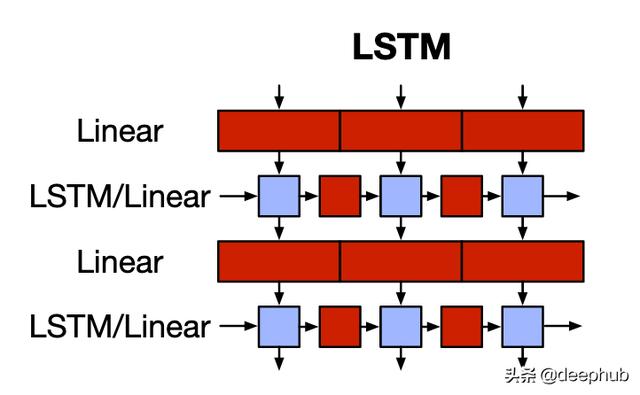 文章插图
文章插图
LSTM是RNN最著名的变体 。红色块是线性函数或矩阵乘法 , 蓝色块是无参数元素级块 。LSTM单元应用门控功能(输入 , 遗忘 , 输出)以获得输出和称为隐藏状态的存储元素 。此隐藏状态包含整个序列的上下文信息 。由于单个向量编码完整序列 , 因此LSTM无法记住长期依赖性 。而且 , 每个时间步长的计算取决于前一个时间步长的隐藏状态 , 即LSTM一次计算一个时间步长 。因此 , 计算不能并行进行 。
CNN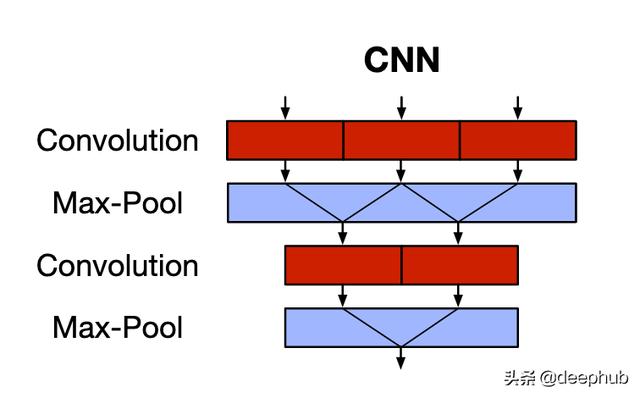 文章插图
文章插图
CNN可以捕获空间特征(主要用于图像) 。红色块是卷积运算 , 蓝色块是无参数池化运算 。CNN使用内核(或过滤器)通过滑动窗口捕获要素之间的对应关系 。这克服了固定长度的隐藏表示形式(以及由此带来的长期依赖问题)以及RNN缺乏并行性限制的问题 。但是 , CNN不显示序列的时间性质 , 即时间不变性 。池化层只是在不考虑序列顺序信息的情况下降低了通道的维数 。
Quasi-Recurrent Neural Networks (QRNN)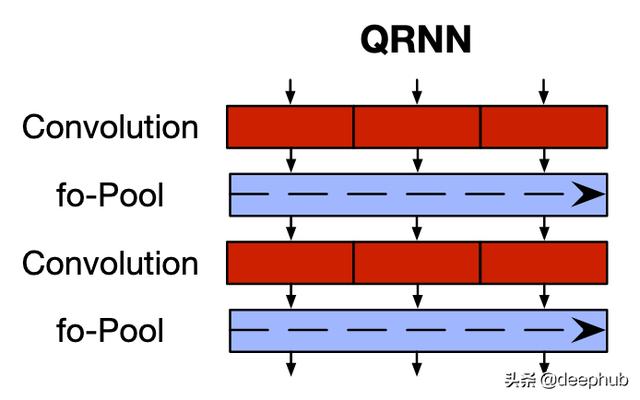 文章插图
文章插图
QRNN解决了两种标准架构的缺点 。它允许并行处理并捕获长期依赖性 , 例如CNN , 还允许输出依赖序列中令牌的顺序 , 例如RNN 。
因此 , 首先 , QRNN体系结构具有2个组件 , 分别对应于CNN中的卷积(红色)和池化(蓝色)组件 。
卷积分量
卷积组件的操作如下:
· 形状的输入序列:(batchsize , sequencelength , embed_dim)
· 每个" bank"的形状为" hiddendim"的内核:(batchsize , kernelsize , embeddim) 。
· 输出是一个形状序列:(batchsize , sequencelength , hidden_dim) 。这些是序列的隐藏状态 。
卷积运算在序列以及小批量上并行应用 。
为了保留模型的因果关系(即 , 只有过去的标记才可以预测未来) , 使用了一种称为遮罩卷积(masked-convolutions)的概念 。也就是说 , 输入序列的左边是" kernelsize-1"零 。因此 , 只有'sequencelength-kernel_size + 1'过去的标记可以预测给定的标记 。为了获得更好的直觉 , 请参考下图:
 文章插图
文章插图
接下来 , 我们基于池化功能(将在下一节中讨论)使用额外的内核库 , 以获取类似于LSTM的门控向量:
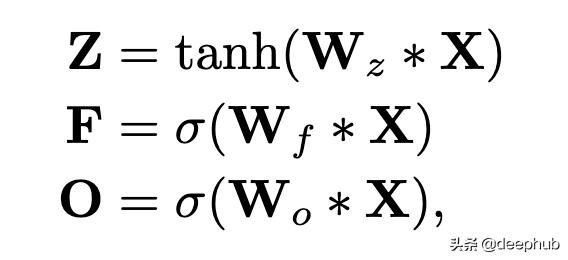 文章插图
文章插图
这里 , *是卷积运算; Z是上面讨论的输出(称为"输入门"输出); F是使用额外的内核库Wf获得的"忘记门"输出; O是使用额外的内核库Wo获得的"输出门"输出 。
如上所述 , 这些卷积仅应用于过去的" sequencelength-kernelsize + 1"令牌 。因此 , 如果我们使用kernel_size = 2 , 我们将得到类似LSTM的方程式:
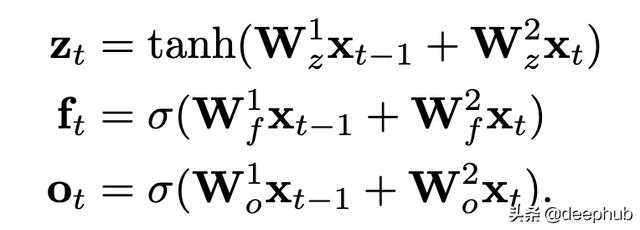 文章插图
文章插图
- 在线教育竞争加剧 一家公司何以一个月融资两轮
- 向蚂蚁学习“跳一跳”战略,持续打磨公文写作核心竞争力
- 联合利华的长期竞争力,依赖于背后这只看不见的“手”
- Ark Invest:特斯拉(TSLA.US)Model 3能效高出竞争对手2倍
- 颠覆你对手表的读数方式——CASIO AQ440
- 外国主持人问马云:你眼中的竞争对手是谁?马云回答太霸气
- 有道竞争在线教育的王牌:左手在线课程 右手智能硬件
- 中国音乐行业洗牌,昔日巨头曲终人散,网易云成腾讯唯一对手
- 高通骁龙888对手来了!三星Exynos 2100即将登场
- 物联网芯片市场高速增长 国内企业竞争实力逐步显现