为什么微信推荐这么快?( 三 )
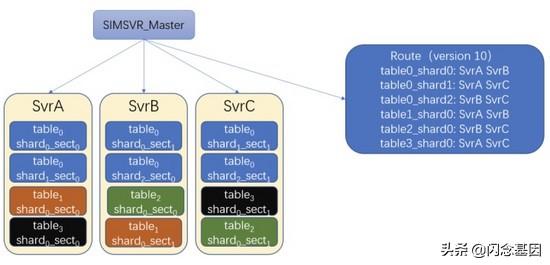
- SimSvr 在每张表创建时就指定了 sharding 数 n 及 sect 数 m , 因此这张表拥有了 n * m 个 Conatiner 以供 master 调度;
- master 会根据 worker 的健康情况及资源使用情况进行数据的调度及路由表的生成;
- 路由表带有递增的版本号 , 可根据版本号感知路由的变化 。
 文章插图
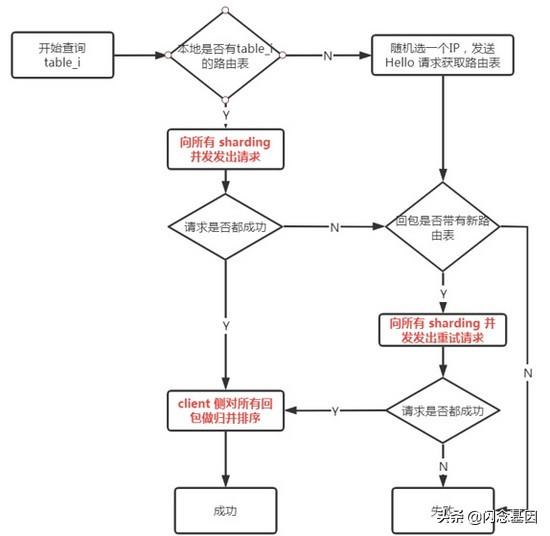
文章插图- worker 定期轮询 Chubby 获取数据的调度情况及最新的路由表信息;
- client 首次请求时 , 将随机请求一台 worker 获取最新的路由表信息并将其缓存在本地;
- client 在本地有路由表的情况下 , 将根据表的数据分布情况 , 带上版本号并发地向目标 worker 发起请求 , 最终合并所有 sharding 的结果 , 将其返回给业务端 。
 文章插图
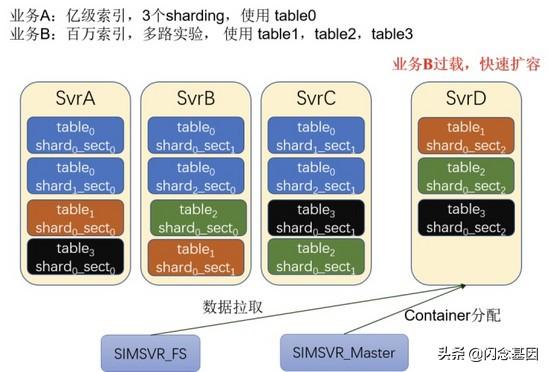
文章插图3.4 系统拓展 - 篮子装满了该怎么办
- SimSvr 将表拆分成了更小粒度的数据调度单位 , 且不要求每台机器上的数据一样 , 因此可以用拓展机器的方式 , 将集群的存储容量扩大;
- 对于单表而言 , 当读能力达到瓶颈时 , 可以单独扩展此表的读副本数;
 文章插图
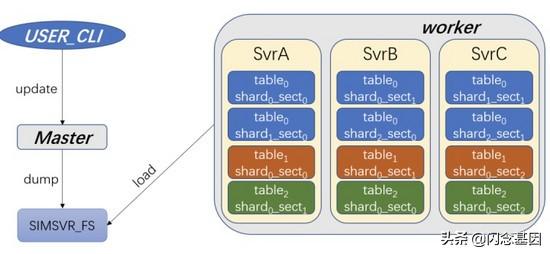
文章插图4. 近实时增量更新的挑战 - 十秒内完成索引的更新
- 数据一致性与持久化
- 对于大多数的分布式存储组件来说 , 都是使用 raft 或者 paxos 等一致性协议保证数据一致性并持久化至本机上;
- 对于 SimSvr 来说 , 每张表会被分为多个 sharding , 且 sharding 数不保证为奇数;
- 在 worker 中加入一致性组件及额外的存储引擎 , 会使得整体的结构变得复杂;
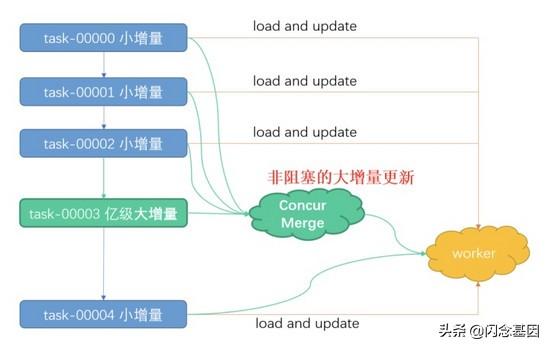
- 最终在考量后 , 结合业务的批量增量更新的特点 , 选择了先将数据落地 fs , 再由 worker 拉取数据加载的方案;在这种方案下 , 1000 以内数量的 key 插入 , 能够在 10s 内完成 , 达到了业务的要求 。
 文章插图
文章插图增量持久化
- 增量更新的性能保障
- 由于在线建索引是非常消耗 cpu 资源的过程 , 因此为了不影响现网的读服务 , worker 仅提供少量的 cpu 资源用于增量数据的更新;
- 对于小批量的增量数据 , worker 可以直接加载存放在 fs 上的数据并直接进行索引的在线插入;
- 对于大批量的增量数据 , 为了避免影响读服务及大增量更新慢的问题 , SimSvr 将大批量数据在 trainer 进行合并且并发重建索引 , 最后再由 worker 直接加载建好的索引 。
 文章插图
文章插图增量更新
【为什么微信推荐这么快?】5. 丰富的功能特性
5.1 支持额外的特征存储库
- 在推荐系统中 , 同一个模型 , 产生的数据除了用于检索的索引库 , 常常还有视频特征/用户画像的特征数据;
- 这类数据 , 仅仅只需要查询的功能 , 并且与同个模型同个版本产出的索引库相互作用 , 产生正确的召回效果;
- 基于这种原子性更新的特性 , SimSvr 支持了额外的特征存储库 , 用于存储与模型一同更新且仅用于查询的特征数据 , 帮助业务省去了数据同步与对齐的烦恼 。
- 在推荐系统中 , ABTest 是非常常见的 , 多个模型的实验往往也是需要同时进行的;
- 另外 , 在某些场景下 , 同一个模型会产生不同的索引数据 , 在线上使用时要求同模型的索引要同时生效;
- 对于以上两种情况 , 如果使用多表支持多模型 , 在索引更新上存在生效时间的差异从而无法支持;
- SimSvr 对于这种情况 , 支持了同一张表多份索引的原子性更新 , 保证了索引能够同时生效 。
- 在 ABTest 场景下 , 除了有多模型间的实验 , 还有相同模型不同版本数据的实验;
- 在相同模型中 , 版本迭代/不同版本进行实验的场景是广泛存在的;
- 如果使用多表支持这样的多版本索引 , 不管在业务方的使用上 , 还是在 SimSvr 的管理上 , 都显得不是那么地优雅;
- 对此 , SimSvr 支持了同一张表的多版本管理 , 并且多版本支持在现网下同时进行服务 , 业务可以按需请求目标版本 , 进行灵活的实验 。
- 看不上|为什么还有用户看不上华为Mate40系列来看看内行人怎么说
- 正确|新昌消防丨听说,这才是微信新表情的正确打开方式
- 制药领域|为什么AI制药这么火,为什么是现在?
- 手机|原来微信一键就能拼接长图,朋友圈可发送几十张照片,涨知识了
- 试试|手机内存不够用,咋办?试试关闭微信这两步操作,轻松腾出几个G
- 手机壳里头|为什么要在手机壳里面夹钱?10个有9个不懂,我才知道大有讲究
- 微信群|社区团购的前世今生
- 纳闷|英媒纳闷:安道尔这个国家微信用户高达2000万,可只有8.5万人!
- 短视频|全球最火APP?抖音爆火背后离不开这几剂“猛药”为什么抖音能够这么火?
- 电商快递|包邮不香吗,为什么还有人加49元让小哥穿西装专车送快递?