为什么微信推荐这么快?( 二 )
 文章插图
文章插图
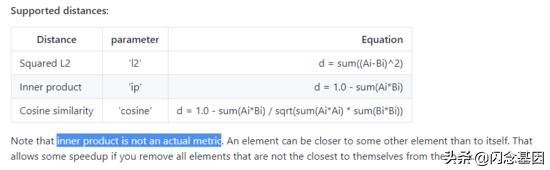
- 而在论文 Non-metric Similarity Graphs forMaximum Inner Product Search 中 , 提到了将 点乘距离转换为余弦距离 计算的方法 , 我们将这种方法简称为 ip2cos;
 文章插图
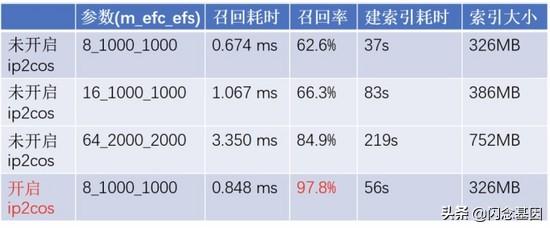
文章插图在 ip2cos 距离转换的理论基础上 , 我们使用看一看视频实时 DSSM 模型进行了实际召回情况的效果对比(64 维、ip 距离、100 万索引数据量 , 进行 1 万次查询取平均耗时) , 并见证了 ip2cos 的神奇效果:
 文章插图
文章插图2.4 如何使用 faiss 省下 2h 的训练时间并提升 30% 的召回率
- 在 faiss 中增加了 batch kmeans 聚类方法 , 在保证较好聚类效果的同时大幅加快训练速度 。 IVF 系类方法训练耗时主要体现在需要从数据中学习 nlist 个聚类中心 , 对于千万级数据 nlist 的大小在 20 万以上 , 在 cpu 上使用传统 kmeans 方法训练会非常耗时 , 下面展示在 128 维、IP 距离、1000 万条数据的情况下 batch kmeans 对训练速度的加速效果:
 文章插图
文章插图从结果中可以看到 , 在相同迭代轮次下 , 不使用 batch kmeans 的方法训练耗时更长 , 且没有很好收敛 , 导致召回率不高 。
3. 总体设计
3.1 数据结构 - 为达成一个小目标 , 需要做出怎样的改变
为了满足单模块多模型的需求 , SimSvr 使用了表的概念进行 多模型的管理 ;另外 , 为 支持亿级以上 HNSW 索引的表, 并且希望能够并发加速构建索引 , 我们根据单表的数据情况 , 将一张表分成了多个 sharding , 使得每个 sharding 承担表数据的其中一部分:
tablei 的索引 , 由 shard0、shard1、…、shardn 构成一份完整的索引数据;而 sect 的数量则决定了表的副本数(可用于伸缩读能力、提供容灾等) 。
在 SimSvr 中 , 我们将一个 shardi_sectj 称之为一个 container , 这是 SimSvr 中最小的数据调度和加载单位 。
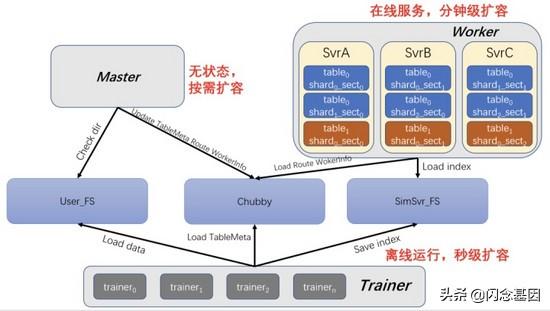
3.2 系统架构 - 如何支撑亿级索引、5毫秒级的检索
 文章插图
文章插图SimSvr 架构
- SimSvr 与 FeatureKV 一样 , 涉及的外部依赖也是三个:
- Chubby:用来保存元数据、路由信息、worker 资源信息等;SimSvr 中的数据协同、分布式任务执行均是依赖于 Chubby;
- USER_FS:业务侧存放原始数据的分布式文件系统 , 可以是 WFS/HDFS , 该文件系统的路径及信息保存在表/任务的元信息中;
- SimSvr_FS:Simsvr 使用的分布式文件系统 , 用于存放生成的索引文件或者原始的增量数据文件 。
- worker
- 负责对外提供检索服务 , 通过对 Chubby 的轮询检查索引的更新 , 进而将索引加载至本机以提供服务;
- 每台 worker 负责的数据 , 由 master 进行调度 , worker 根据 master 保存在 Chubby 上的分配信息进行数据的加载/卸载;
- worker 的数据是根据 master 分配得来的 , 除此之外没有其他状态的差别 , 因此 worker 是易于扩缩容的 。
- master
- 数据调度:通过表的元信息及 worker 状态 , 将未分配的数据或者失效 worker 上的数据调度给其他有效的 worker;
- 生成路由表:根据 worker 的数据加载情况及状态 , 生成集群的路由表;
- 感知数据更新:检查表的自动更新目录 , 若最大数字目录发生了增长 , 则建一个任务以供 trainer 进行索引的构建;
- master 是一个无状态的服务 , 通过 Chubby 提供的分布式锁保证数据调度以及路由生成的唯一执行 。
- trainer
- 负责构建表的索引及资源回收;
- trainer 单次可构建一张表中一个 sharding 的索引 , 因此如果表有多个 sharding 时 , 可通过增加 trainer 的个数实现构建索引的并发加速;
- trainer 是无状态的服务 , 通常部署在微信 Yard 系统上 , 充分了利用微信闲置机器上的资源 。
- 数据自动更新
- 在建表时 , 对其指定了一个 fs 的目录 , 该目录下 , 是一系列数字递增的目录;
- 当业务侧需要更新索引时 , 将最新的数据 dump 到更大的数字目录中;
- master 感知最大数字目录的更新 , 从而更新了元信息;
- trainer 感知元信息的更新并触发建索引;
- worker 加载索引完成索引的更新 。
- 数据任务式更新
- 由业务侧主动通过接口的调用 , 创建一个索引任务;
- 看不上|为什么还有用户看不上华为Mate40系列来看看内行人怎么说
- 正确|新昌消防丨听说,这才是微信新表情的正确打开方式
- 制药领域|为什么AI制药这么火,为什么是现在?
- 手机|原来微信一键就能拼接长图,朋友圈可发送几十张照片,涨知识了
- 试试|手机内存不够用,咋办?试试关闭微信这两步操作,轻松腾出几个G
- 手机壳里头|为什么要在手机壳里面夹钱?10个有9个不懂,我才知道大有讲究
- 微信群|社区团购的前世今生
- 纳闷|英媒纳闷:安道尔这个国家微信用户高达2000万,可只有8.5万人!
- 短视频|全球最火APP?抖音爆火背后离不开这几剂“猛药”为什么抖音能够这么火?
- 电商快递|包邮不香吗,为什么还有人加49元让小哥穿西装专车送快递?