为什么微信推荐这么快?
作者:sauronzhang、flashlin、fengshanliu , 微信后台开发工程师
出处:
1. 背景
在一些推荐系统、图片检索、文章去重等场景中 , 对基于特征数据进行 k 近邻检索有着广泛的需求:
- 支持亿级索引的检索 , 同时要求非常高的检索性能;
- 支持索引的批量实时更新;
- 支持多模型、多版本以灵活开展 ABTest 实验;
- 支持过滤器、过期删除以排除不符合特定条件的数据 。
- 在学术界中 , 已经存在有成熟并开源的 ANN 搜索库 , 然而这些搜索库仅仅是作为单机引擎存在 , 而不能作为 高性能、可依赖、可拓展的分布式组件为推荐系统提供服务 ;
- 在业界中 , 大多数的组件都是基于 ANN 搜索库做一层简单的封装 , 在可拓展、高可用上的表现达不到在线系统的要求;而对于少数在实现上已经较为成熟的分布式检索系统 , 在 功能上却难以做到紧跟业务发展 ;
- 而在更新机制上 , 很多组件都是要么只支持离线更新、要么只支持在线接口更新 , 无法满足在微信侧 小至秒级千数量、大至小时级亿数量的索引更新需求, 因此需要可以兼顾近实时更新及离线大批量更新的分布式系统 。
- 分布式可伸缩的架构 , 支持亿级以上的索引量 , 以及索引的并发加速查询 , 实现了 10ms 以内检索数亿 的索引;
- 高性能召回引擎 , 使用了召回性能极佳的 hnswlib 作为首选召回引擎 , 大部分请求可在 2ms 内 完成检索;
- 集群化管理 , 集成了完善的数据调度及动态路由功能;
- 多样的更新机制 , 支持任务式更新及自动更新 , 同时也支持全量更新与增量更新 , 跨越 秒级千数量 到 小时级亿数量 的索引更新;
- 读写分离的机制 , 在离线利用庞大的计算资源加速构建索引的同时 , 不影响在线服务的高性能读;
- 丰富的功能特性 , 支持轻量 embedding kv 库、单表多索引、多版本索引、过滤器、过期删除等特性 。
2. 检索引擎
2.1 引擎的选择
ANN 问题在学术界已被长期研究 , 并且已有成熟的开源 ANN 搜索库存在 , 如 nmslib、hnswlib、faiss 等 。 在 SimSvr 中 ,性能及集群的存储容量 是最主要考量的两个指标 , 因此选择了以下两个检索引擎:
- 在 ann-benchmarks 中检索性能最好的 hnswlib , 能够满足在线服务对召回率及检索耗时的高要求( 大于 90% 召回率的情况下 , 能在 1ms 内完成召回 );
- faiss 的 IVFx_HNSWy + PQz 算法 , 支持将向量压缩 10 ~ 30 倍 , 能够满足资源有限情况下的高维大数据量的索引要求(亿级索引数据 , 容纳在内存 64G 的机器上) 。
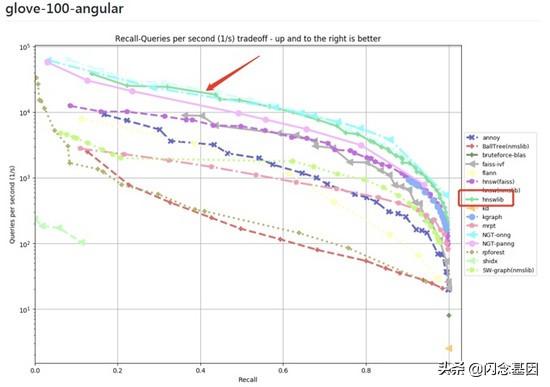 文章插图
文章插图ANN检索引擎效果对比
2.2 巧妙利用资源 , 提升 50% 的数据容纳量
- hnswlib 是单机检索引擎 , 在资源使用方面仅考虑了单模型的情况;而 SimSvr 是提供在线服务的组件 , 一般容纳了多个模型;
- SimSvr 在大部分场景下 , 拥有读写分离的特点;基于以上特点 , 我们在引入 hnswlib 之后 , 进行了资源整合 , 使得 SimSvr 单机情况下可以容纳更多的模型索引:
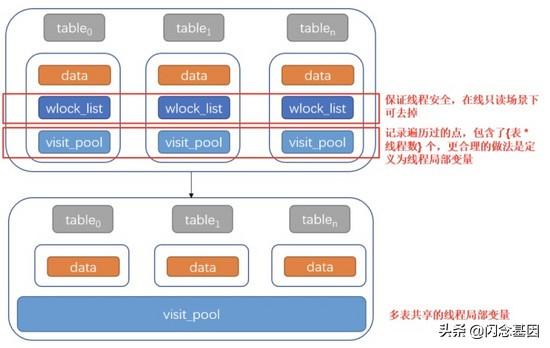 文章插图
文章插图- 极限情况下(以 worker 线程数 80、部署 10 张 2kw 索引量的表为例):
 文章插图
文章插图- 现网运营中(以某现网模块(11台实例机器 , worker 线程 240)为例):
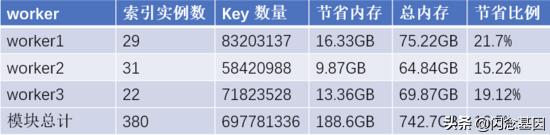 文章插图
文章插图2.3 点积距离召回率从 62.6% 到 97.8% 的蜕变心路历程
- HNSW 算法在 余弦距离 表现优秀 , 但在 点乘距离 的数据集上存在效果差的情况;
- 点乘距离非度量空间(metric space) ,不满足三角不等式, 距离比较没有传递性;
- 维基百科中关于度量空间的定义:
 文章插图
文章插图- hnswlib 中说明点积属于非度量空间:
- 看不上|为什么还有用户看不上华为Mate40系列来看看内行人怎么说
- 正确|新昌消防丨听说,这才是微信新表情的正确打开方式
- 制药领域|为什么AI制药这么火,为什么是现在?
- 手机|原来微信一键就能拼接长图,朋友圈可发送几十张照片,涨知识了
- 试试|手机内存不够用,咋办?试试关闭微信这两步操作,轻松腾出几个G
- 手机壳里头|为什么要在手机壳里面夹钱?10个有9个不懂,我才知道大有讲究
- 微信群|社区团购的前世今生
- 纳闷|英媒纳闷:安道尔这个国家微信用户高达2000万,可只有8.5万人!
- 短视频|全球最火APP?抖音爆火背后离不开这几剂“猛药”为什么抖音能够这么火?
- 电商快递|包邮不香吗,为什么还有人加49元让小哥穿西装专车送快递?