告别CNN?一张图等于16x16个字,计算机视觉也用上Transformer了( 二 )
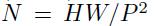 文章插图
文章插图
。 由于Transformer只接受1D序列作为输入 , 因此还需要对每个patch进行embedding , 通过一个线性变换层将二维的patch嵌入表示为长度为D的一维向量 , 得到的输出被称为patch嵌入 。
类似于BERT模型的[class] token机制 , 对每一个patch嵌入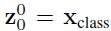 文章插图
文章插图
, 都会额外预测一个可学习的嵌入表示 , 然后将这个嵌入表示在encoder中的最终输出(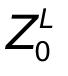 文章插图
文章插图
)作为对应patch的表示 。 在预训练和微调阶段 , 分类头都依赖于 。
此外还加入了位置嵌入信息(图中的0 , 1 , 2 , 3…) , 因为序列化的patch丢失了他们在图片中的位置信息 。 作者尝试了各种不同的2D嵌入方法 , 但是相较于一般的1D嵌入并没有任何显著的性能提升 , 因此最终使用联合嵌入作为输入 。
模型结构与标准的Transformer相同(如上图右侧) , 即由多个交互层多头注意力(MSA)和多层感知器(MLP)构成 。 在每个模块前使用LayerNorm , 在模块后使用残差连接 。 使用GELU作为MLP的激活函数 。 整个模型的更新公式如下: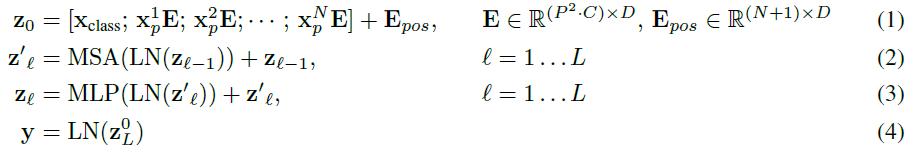 文章插图
文章插图
其中(1)代表了嵌入层的更新 , 公式(2)和(3)则代表了MSA和MLP的前向传播 。
此外本文还提出了一种直接采用ResNet中间层输出作为图片嵌入表示的方法 , 可以作为上述基于patch分割方法的替代 。 文章插图
文章插图
模型训练和分辨率调整
和之前常用的做法一样 , 在针对具体任务时 , 先在大规模数据集上训练 , 然后根据具体的任务需求进行微调 。 这里主要是更换最后的分类头 , 按照分类数来设置分类头的参数形状 。 此外作者还发现在更高的分辨率进行微调往往能取得更好的效果 , 因为在保持patch分辨率不变的情况下 , 原始图像分辨率越高 , 得到的patch数越大 , 因此得到的有效序列也就越长 。 文章插图
文章插图
对比实验
4.1 实验设置
首先作者设计了多个不同大小的ViT变体 , 分别对应不同的复杂度 。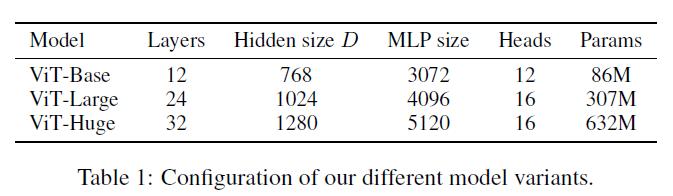 文章插图
文章插图
数据集主要使用ILSVRC-2012 , ImageNet-21K , 以及JFT数据集 。
4.2 与SOTA模型的性能对比
首先是和ResNet以及efficientNet的对比 , 这两个模型都是比较有代表的基于CNN的模型 。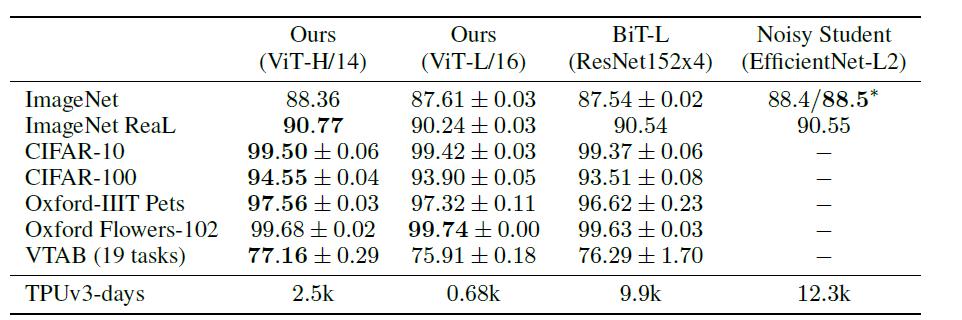 文章插图
文章插图
其中ViT模型都是在JFT-300M数据集上进行了预训练 。 从上表可以看出 , 复杂度较低 , 规模较小的ViT-L在各个数据集上都超过了ResNet , 并且其所需的算力也要少十多倍 。 ViT-H规模更大 , 但性能也有进一步提升 , 在ImageNet, CIFAR,Oxford-IIIT, VTAB等数据集上超过了SOTA , 且有大幅提升 。
作者进一步将VTAB的任务分为多组 , 并对比了ViT和其他几个SOTA模型的性能: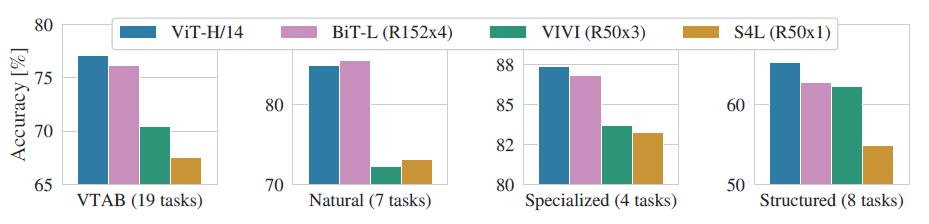 文章插图
文章插图
可以看到除了在Natrual任务中ViT略低于BiT外 , 在其他三个任务中都达到了SOTA , 这再次证明了ViT的性能强大 。
4.3 不同预训练数据集对性能的影响
预训练对于该模型而言是一个非常重要的环节 , 预训练所用数据集的规模将影响模型的归纳偏置能力 , 因此作者进一步探究了不同规模的预训练数据集对性能的影响: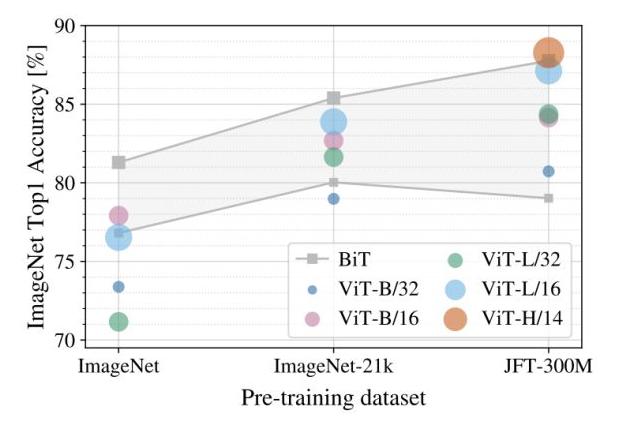 文章插图
文章插图
上图展示了不同规模的预训练数据集(横轴)对不同大小的模型的性能影响 , 注意微调时的数据集固定为ImageNet 。 可以看到对大部分模型而言 , 预训练数据集规模越大 , 最终的性能越好 。 并且随着数据集的增大 , 较大的ViT模型(ViT-H/14)要由于较小的ViT模型(ViT-L) 。
此外 , 作者还在不同大小的JFT数据集的子集上进行了模型训练: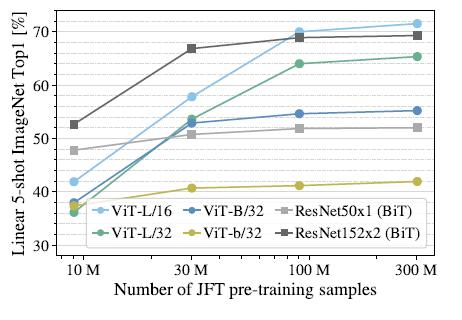 文章插图
文章插图
可以发现ViT-L对应的两个模型在数据集规模增大时有非常明显的提升 , 而ResNet则几乎没有变化 。 这里可以得出两个结论 , 一是ViT模型本身的性能上限要优于ResNet,这可以理解为注意力机制的上限高于CNN 。 二是在数据集非常大的情况下 , ViT模型性能大幅超越ResNet, 这说明在数据足够的情况下 , 注意力机制完全可以代替CNN , 而在数据集较小的情况下(10M) , 卷积则更为有效 。
- 风波|杀貂风波致商户疯抢进口貂皮:一张皮涨200元,一件大衣成本增千元
- 主题|GNN、RL崛起,CNN初现疲态?ICLR 2021最全论文主题分析
- 海淀区|海淀城市大脑“时空一张图”上线
- 塑料颗粒|别不信!你每天吃的塑料量,一周后可能等于一张信用卡!
- 纸条|女子网购买了一双鞋,收货后发现一张纸条,看完她怒了
- 告诉|阿里大佬告诉你如何一分钟利用Python在家告别会员看电影
- 互联网巨头们打出一张张牌,都直击卖菜小贩,线下实体该何去何从
- 告别卡顿,一份手机清理指南
- 图解3种常见的深度学习网络结构:FC、CNN、RNN
- 服务|听说我上热搜了?