有关自然语言处理的深度学习知识有哪些?( 二 )
维向量的输入 , 在向量的开头或结尾处增加一个元素 , 构成一个n + 1维的向量 。 1的位置与网络无关 , 只要在所有样本中保持一致即可 。 另一种表示形式是 , 首先假定存在一个偏置项 , 将其独立于输入之外 , 其对应一个独立的权重 , 将该权重乘以1 , 然后与样本输入值及其相关权重的点积进行加和 。 这两者实际上是一样的 , 只不过分别是两种常见的表示形式而已 。
设置偏置权重的原因是神经元需要对全0的输入具有弹性 。 网络需要学习在输入全为0的情况下输出仍然为0 , 但它可能做不到这一点 。 如果没有偏置项 , 神经元对初始或学习的任意权重都会输出0 × 权重 = 0 。 而有了偏置项之后 , 就不会有这个问题了 。 如果神经元需要学习输出0 , 在这种情况下 , 神经元可以学会减小与偏置相关的权重 , 使点积保持在阈值以下即可 。
图5-3用可视化方法对生物的大脑神经元的信号与深度学习人工神经元的信号进行了类比 , 如果想要做更深入的了解 , 可以思考一下你是如何使用生物神经元来阅读本书并学习有关自然语言处理的深度学习知识的[5] 。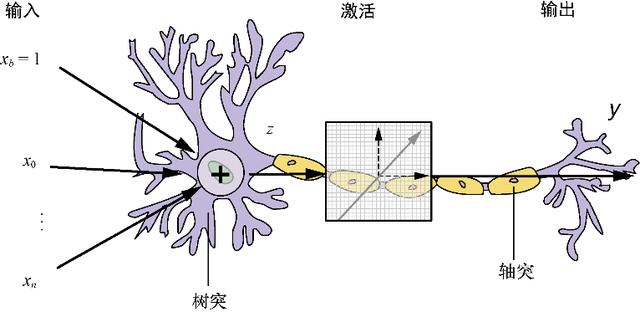 文章插图
文章插图
图5-3 感知机与生物神经元
用数学术语来说 , 感知机的输出表示为f (x) , 如下: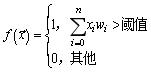 文章插图
文章插图
公式5-1 阈值激活函数
提示
输入向量(X)与权重向量(W)两两相乘后的加和就是这两个向量的点积 。 这是线性代数在神经网络中最基础的应用 , 对神经网络的发展影响巨大 。 另外 , 通过现代计算机GPU对线性代数操作的性能优化来完成感知机的矩阵乘法运算 , 使得实现的神经网络变得极为高效 。
此时的感知机并未学到任何东西 , 不过大家已经获得了非常重要的结果 , 我们已经向模型输入数据并且得到输出 。 当然这个输出可能是错误的 , 因为还没有告诉感知机如何获得权重 , 而这正是最有趣的地方所在 。
提示
所有神经网络的基本单位都是神经元 , 基本感知机是广义神经元的一个特例 , 从现在开始 , 我们将感知机称为一个神经元 。
1.Python版神经元在Python中 , 计算神经元的输出是很简单的 。 大家可以用numpy的dot函数将两个向量相乘:
>>> import numpy as np>>> example_input = [1, .2, .1, .05, .2]>>> example_weights = [.2, .12, .4, .6, .90]>>> input_vector = np.array(example_input)>>> weights = np.array(example_weights)>>> bias_weight = .2>>> activation_level = np.dot(input_vector, weights) +\...(bias_weight * 1)?--- 这里bias_weight * 1只是为了强调bias_weight和其他权重一样:权重与输入值相乘 , 区别只是bias_weight的输入特征值总是1>>> activation_level0.674接下来 , 假设我们选择一个简单的阈值激活函数 , 并选择0.5作为阈值 , 结果如下:
>>> threshold = 0.5>>> if activation_level >= threshold:...perceptron_output = 1... else:...perceptron_output = 0>>> perceptron_output)1对于给定的输入样本example_input和权重 , 这个感知机将会输出1 。 如果有许多example_input向量 , 输出将会是一个标签集合 , 大家可以检查每次感知机的预测是否正确 。
2.课堂时间大家已经构建了一个基于数据进行预测的方法 , 它为机器学习创造了条件 。 到目前为止 , 权重都作为任意值而被我们忽略了 。 实际上 , 它们是整个架构的关键 , 现在我们需要一种算法 , 基于给定样本的预测结果来调整权重值的大小 。
感知机将权重的调整看成是给定输入下预测系统正确性的一个函数 , 从而学习这些权重 。 但是这一切从何开始呢?未经训练的神经元的权重一开始是随机的!通常是从正态分布中选取趋近于零的随机值 。 在前面的例子中 , 大家可以看到从零开始的权重(包括偏置权重)为何会导致输出全部为零 。 但是通过设置微小的变化 , 无须提供给神经元太多的能力 , 神经元便能以此为依据判断结果何时为对何时为错 。
然后就可以开始学习过程了 。 通过向系统输入许多不同的样本 , 并根据神经元的输出是否是我们想要的结果来对权重进行微小的调整 。 当有足够的样本(且在正确的条件下) , 误差应该逐渐趋于零 , 系统就经过了学习 。
其中最关键的一个诀窍是 , 每个权重都是根据它对结果误差的贡献程度来进行调整 。 权重越大(对结果影响越大) , 那么该权重对给定输入的感知机输出的正确性/错误性就负有越大的责任 。
- 新一代|外媒: 高通新一代旗舰处理器或命名为骁龙888
- 将要发布|高通下一代处理器不叫骁龙875,而是叫骁龙888
- 天玑|天玑800U处理器加持的RedmiNote9
- 淘汰|过气旗舰不如狗?骁龙845处理器要被淘汰了
- 热点功能|旧手机别乱处理,分享旧手机6个小妙用,放在家里好值钱
- 款处理器|小米最便宜的大屏智能机,性价比超高,送长辈的不二之选
- 改名|小米首发?曝高通新一代旗舰处理器临时改名,或为骁龙888
- 骁龙875处理|进一步确定!小米11Pro采用2K+/120Hz屏,网友:价格贵也接受
- 创园|中国V谷的云存储之道,马栏山文创园将视频处理效率提升6倍
- 卷轴屏概念机|未量产一律按PPT手机处理!盘点那些华而不实的概念机