Canal探究( 二 )
一份 instance bean 定义 , 需要包含 eventParser , evnetSink , evnetStore , metaManager , alarmHandler 的5个模块定义 , ( alarmHandler 主要是一些报警机制处理 , 因为简单没展开 , 可扩展)
instance.xml设计初衷:
允许进行自定义扩展 , 比如实现了基于数据库的位点管理后 , 可以自定义一份自己的instance.xml , 整个canal设计中最大的灵活性在于此
HA模式配置canal的ha分为两部分:
- canal server: 不同server上的instance要求同一时间只能有一个处于running , 其他的处于standby状态 , 不然就是对mysql dump的重复请求 。 这里是instance/destination级别的负载均衡 , 而不是server
- canal client: 为了保证有序性 , 一份instance同一时间只能由一个canal client进行get/ack/rollback操作 , 否则客户端接收无法保证有序 。
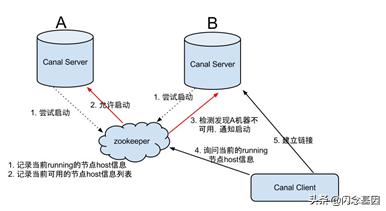
Canal Server:
 文章插图
文章插图- canal server要启动某个canal instance时都先向zookeeper进行一次尝试启动判断 (实现:创建EPHEMERAL节点 , 谁创建成功就允许谁启动)
- 创建zookeeper节点成功后 , 对应的canal server就启动对应的canal instance , 没有创建成功的canal instance就会处于standby状态
- 一旦zookeeper发现canal server A创建的节点消失后 , 立即通知其他的canal server再次进行步骤1的操作 , 重新选出一个canal server启动instance.
- canal client每次进行connect时 , 会首先向zookeeper询问当前是谁启动了canal instance , 然后和其建立链接 , 一旦链接不可用 , 会重新尝试connect.
canal丢失数据的情况:正常情况下 , 在canal server/client挂掉或切换的情况下不会丢失数据 , 因为zk会持久化server解析binlog及clinet消费数据的位置 , 重启时会重新读取 。 以下情况可能会丢失数据:
- zk保存的元数据被人为修改 , 如server解析binlog及clinet消费数据的位置
- client使用get方法而非getWithoutAck , 如果client消费数据时挂掉 , server会认为这部分数据已经被消费而丢失
- MySQL binlog非正常运维 , 比如binglog迁移、重命名、丢失等
- 切换MySQL源 , 比如原来基于M1实例 , 后来M1因为某种原因失效 , 那么Canal将数据源切换为M2 , 而且M1和M2可能binlog数据存在不一致
- canal处理数据流程为master-parse-sink-store-comsume , 整个流程中都是单线程、串行、阻塞式的 。 如果批量insert、update、delete , 都可能导致大量的binlog产生 , 也会加剧Master与slave之间数据同步的延迟 。 (写入频繁) 。
- 如果client消费的效能较低 , 比如每条event执行耗时很长 。 这会导致数据变更的消息ACK较慢 , 那么对于Canal而言也将阻塞sotre , 没有有足够的空间存储新消息进而堵塞parse解析binlog 。
- Canal本身非常轻量级 , 主要性能开支就是在binlog解析 , 其转发、存储、提供消费者服务等都很简单 。 它本身不负责数据存储 。 原则上 , canal解析效率几乎没有负载 , canal的本身的延迟 , 取决于其与slave之间的网络IO 。
- Canal instance初始化时 , 根据“消费者的Cursor”来确定binlog的起始位置 , 但是Cursor在ZK中的保存是滞后的(间歇性刷新) , 所以Canal instance获得的起始position一定不会大于消费者真实已见的position 。
- Consumer端 , 因为某种原因的rollback , 也可能导致一个batch内的所有消息重发 , 此时可能导致重复消费 。
- iOS虚拟定位技术探究
- 博览会|数字版权产业“蛋糕”有多大?明天成都这场博览会上一探究竟!
- 究竟|超市食品背后的标签上到底隐藏着些什么?广元市场监管带您一探究竟!
- 未来|探究丨滴滴x比亚迪=D1∞也许是计算未来出行的公式之一
- K30S至尊纪念版手机|探究K30S至尊版动态刷新率调整机制时,我发现了一个秘密
- 正则表达式性能优化的探究
- 这也太吊了吧,大神详解Redis——持久化原理探究
- 探究 | 谁再说Redis慢,我跟谁急
- Canalys公布Q3国内手机出货量 小米逆势增长排名第四
- 小米新品木星黎明积木 六足泰坦,AR黑科技,开箱来一探究竟