正则表达式性能优化的探究
作者:huangrenhui
出处:
正则表达式是计算机科学的一个概念 , 很多语言都实现了它 。 正则表达式使用一些特定的元字符来检索、匹配以及替换符合规定的字符串 。
构造正则表达式语法的元字符 , 由普通字符、标准字符、限定字符(量词)、定位符(边界字符)组成 , 详情如下图: 文章插图
文章插图
二.正则表达式引擎正则表达式是一个用正则符号写出的公式 , 程序对这个公式进行语法分析 , 建立一个语法分析树 , 再根据这个分析树结合正则表达式的引擎生成执行程序(这个执行程序我们把它称作状态机 , 也叫状态自动机) , 用于字符匹配 。
而这里的正则表达式引擎就是一套核心算法 , 用于建立状态机 。
目前实现正则表达式引擎的方式有两种:DFA自动机(Deterministic Final Automata 确定有限状态自动机)和 NFA(Non deterministic Finite Automaton 非确定有限状态自动机) 。
对比来看 , 构造 DFA 自动机的代价远大于 NFA 自动机 , 但 DFA 自动机的执行效率高于 NFA 自动机 。
假设一个字符串的长度是 n , 如果用 DFA 自动机作为正则表达式引擎 , 则匹配的时间复杂度为 O(n);如果用 NFA 自动机作为正则表达式引擎 , 由于 NFA 自动机在匹配过程中存在大量的分支和回溯 , 假设 NFA 的状态数为 s , 则该匹配算法的时间复杂度为 O(ns) 。
NFA 自动机的优势是支持更多功能 。 例如:捕获 group、环视、占有优先量词等高级功能 。 这些功能都是基于子表达式独立进行匹配 , 因此在编程语言里 , 使用的正则表达式库都是基于 NFA 实现的 。
那么 NFA 自动机到底是怎么进行匹配的呢?接下来以下面的例子来进行说明:
text = "aabcab"regex = "bc"NFA 自动机会读取正则表达式的每一个字符 , 拿去和目标字符串匹配 , 匹配成功就换正则表达式的下一个字符 , 反之就继续和目标字符串的下一个字符进行匹配 。
分解一下过程:
1)读取正则表达式的第一个匹配符和字符串的第一个字符进行比较 , b 对 a , 不匹配;继续换字符串的下一个字符 , 也就是 a , 不匹配;继续换下一个 , 是 b , 匹配;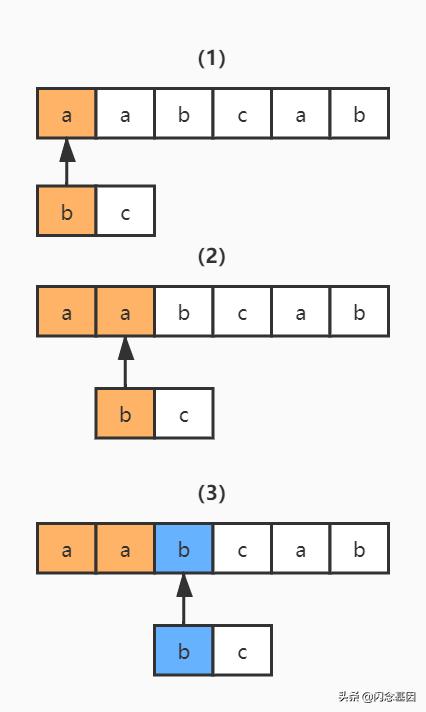 文章插图
文章插图
2)同理 , 读取正则表达式的第二个匹配符和字符串的第四个字符进行比较 , c 对 c , 匹配;继续读取正则表达式的下一个字符 , 然而后面已经没有可匹配的字符了 , 结束 。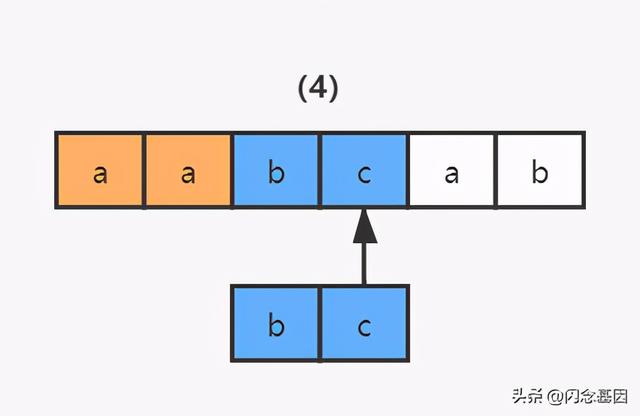 文章插图
文章插图
这就是 NFA 自动机的匹配过程 , 虽然在实际应用中 , 碰到的正则表达式都要比这复杂 , 但匹配方法是一样的 。
三.NFA自动机的回溯用 NFA 自动机实现的比较复杂的正则表达式 , 在匹配过程中经常会引起回溯问题 。 大量的回溯会长时间地占用 CPU , 从而带来系统性能开销 。 如下面例子:
text = "abbc"regex = "ab{1,3}c"上面例子 , 匹配目的比较简单 。 匹配以 a 开头 , 以 c 结尾 , 中间有 1-3 个 b 字符的字符串 。 NFA 自动机对其解析的过程是这样的:
1)读取正则表达式第一个匹配符 a 和字符串第一个字符 a 进行比较 , a 对 a , 匹配;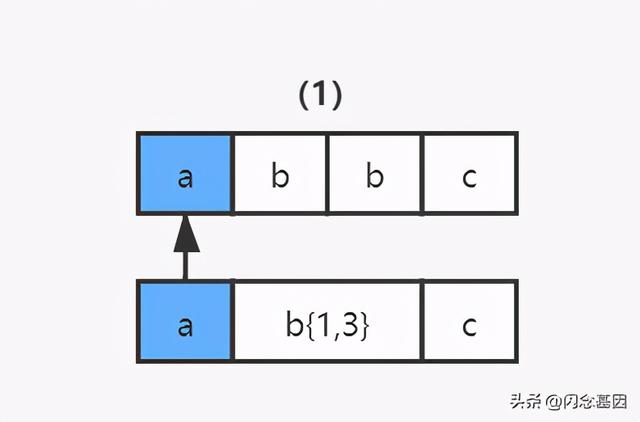 文章插图
文章插图
【正则表达式性能优化的探究】2)读取正则表达式第一个匹配符 b{1,3} 和字符串的第二个字符 b 进行比较 , 匹配 。 但因为 b{1,3} 表示 1-3 个 b 字符串 , NFA 自动机又具有贪婪特性 , 所以此时不会继续读取正则表达式的下一个匹配符 , 而是依旧使用 b{1,3} 和字符串的第三个字符 b 进行比较 , 结果还是匹配 。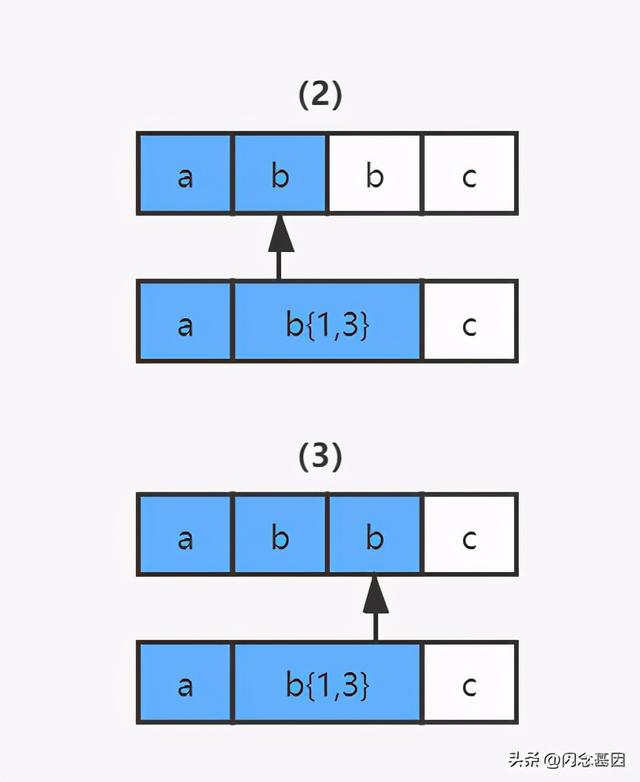 文章插图
文章插图
3)继续使用 b{1,3} 和字符串的第四个字符 c 进行比较 , 发现不匹配了 , 此时就会发生回溯 , 已经读取的字符串第四个字符 c 将被吐出去 , 指针回到第三个字符 b 的位置 。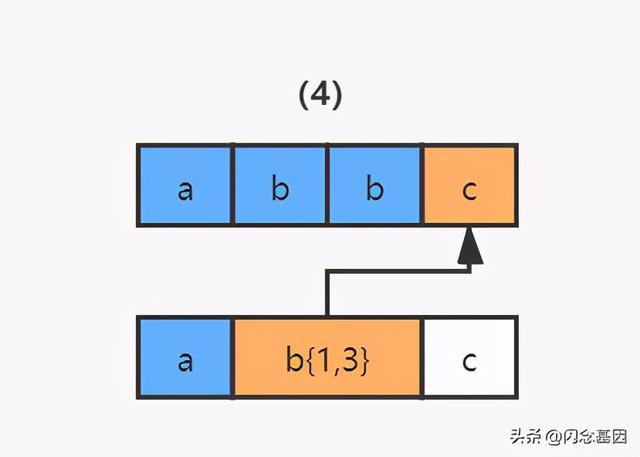 文章插图
文章插图
4)那么发生回溯以后 , 匹配过程怎么继续呢?程序会读取正则表达式的下一个匹配符 c , 和字符串中的第四个字符 c 进行比较 , 结果匹配 , 结束 。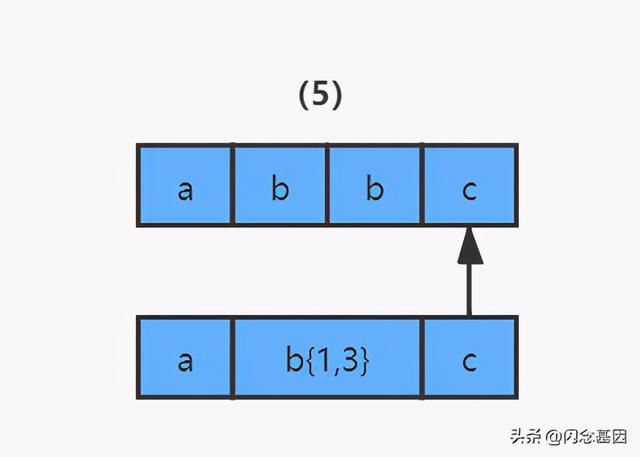 文章插图
文章插图
四.如何避免回溯问题?既然回溯会给系统带来性能开销 , 那我们如何应对呢?如果你有仔细看上面那个案例的话 , 你会发现 NFA 自动机的贪婪特性就是导火索 , 这和正则表达式的匹配模式息息相关 。
- 巅峰|realme巅峰之作:120Hz+陶瓷机身+5000mAh 做到了颜值与性能并存
- 华为|骁龙870和骁龙855区别都是7nm芯片吗 性能对比评测
- 器件|苏州纳米所等在高性能柔性储能器件研究中取得进展
- 超强|RedmiNote9系列发布!天玑800U赋予超强5G性能
- iPhoneX|iPhone12和iPhoneX性能对决:差距比想象的大太多
- Redmi|Redmi Note 9系列发布,搭载天玑800U具备超强5G性能
- 首发|华为或首发联发科6纳米+A78新U:性能超强不输麒麟9000
- 华为|安兔兔10月安卓性能榜:华为Mate40 Pro第一 麒麟9000碾压骁龙865
- 骁龙865|5G手机中的性能怪兽,256+120W闪充,比iPhone12值得买
- 网间|新外观专利陆续曝光 徐起和网间透露realme极致性能新机将至