探究 | 谁再说Redis慢,我跟谁急
作为一名服务端工程师 , 工作中你肯定和 Redis 打过交道 。 Redis 为什么快 , 这点想必你也知道 , 至少为了面试也做过准备 。 很多人知道 Redis 快仅仅因为它是基于内存实现的 , 对于其他原因倒是模棱两可 。 文章插图
文章插图
图片来自 Pexels
那么今天就和我一起看看: 文章插图
文章插图
思维导图
基于内存实现
这点在一开始就提到过了 , 这里再简单说说 。
Redis 是基于内存的数据库 , 那不可避免的就要与磁盘数据库做对比 。 对于磁盘数据库来说 , 是需要将数据读取到内存里的 , 这个过程会受到磁盘 I/O 的限制 。
而对于内存数据库来说 , 本身数据就存在于内存里 , 也就没有了这方面的开销 。
高效的数据结构
Redis 中有多种数据类型 , 每种数据类型的底层都由一种或多种数据结构来支持 。
正是因为有了这些数据结构 , Redis 在存储与读取上的速度才不受阻碍 。 这些数据结构有什么特别的地方 , 各位看官接着往下看: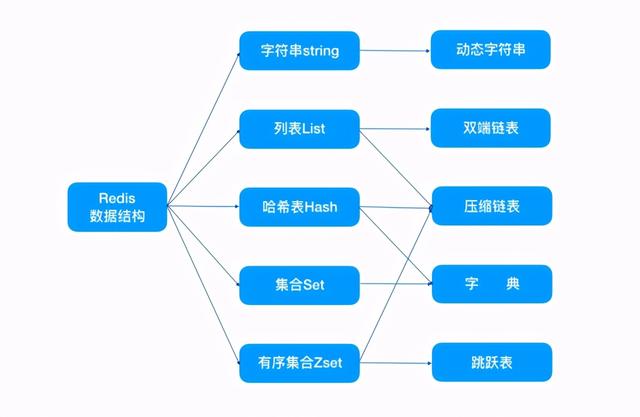 文章插图
文章插图
简单动态字符串
这个名词可能你不熟悉 , 换成 SDS 肯定就知道了 。 这是用来处理字符串的 。 了解 C 语言的都知道 , 它是有处理字符串方法的 。
而 Redis 就是 C 语言实现的 , 那为什么还要重复造轮子?我们从以下几点来看:
①字符串长度处理 文章插图
文章插图
这个图是字符串在 C 语言中的存储方式 , 想要获取 Redis 的长度 , 需要从头开始遍历 , 直到遇到 '\0' 为止 。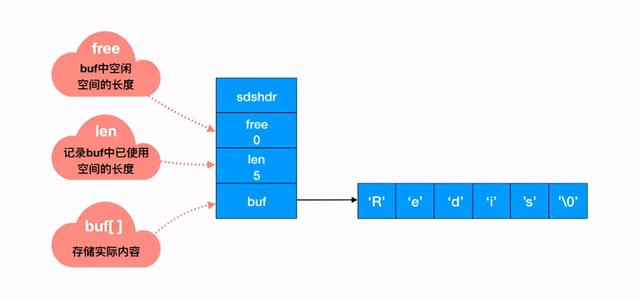 文章插图
文章插图
Redis 中怎么操作呢?用一个 len 字段记录当前字符串的长度 。 想要获取长度只需要获取 len 字段即可 。
你看 , 差距不言自明 。 前者遍历的时间复杂度为 O(n) , Redis 中 O(1) 就能拿到 , 速度明显提升 。
②内存重新分配
C 语言中涉及到修改字符串的时候会重新分配内存 。 修改地越频繁 , 内存分配也就越频繁 。 而内存分配是会消耗性能的 , 那么性能下降在所难免 。
而 Redis 中会涉及到字符串频繁的修改操作 , 这种内存分配方式显然就不适合了 。
于是 SDS 实现了两种优化策略:
空间预分配:对 SDS 修改及空间扩充时 , 除了分配所必须的空间外 , 还会额外分配未使用的空间 。
具体分配规则是这样的:SDS 修改后 , len 长度小于 1M , 那么将会额外分配与 len 相同长度的未使用空间 。 如果修改后长度大于 1M , 那么将分配 1M 的使用空间 。
惰性空间释放:当然 , 有空间分配对应的就有空间释放 。
SDS 缩短时 , 并不会回收多余的内存空间 , 而是使用 free 字段将多出来的空间记录下来 。 如果后续有变更操作 , 直接使用 free 中记录的空间 , 减少了内存的分配 。
③二进制安全
你已经知道了 Redis 可以存储各种数据类型 , 那么二进制数据肯定也不例外 。 但二进制数据并不是规则的字符串格式 , 可能会包含一些特殊的字符 , 比如 '\0' 等 。
前面我们提到过 , C 中字符串遇到 '\0' 会结束 , 那 '\0' 之后的数据就读取不上了 。 但在 SDS 中 , 是根据 len 长度来判断字符串结束的 。
看 , 二进制安全的问题就解决了 。
双端链表
列表 List 更多是被当作队列或栈来使用的 。 队列和栈的特性一个先进先出 , 一个先进后出 。 双端链表很好的支持了这些特性 。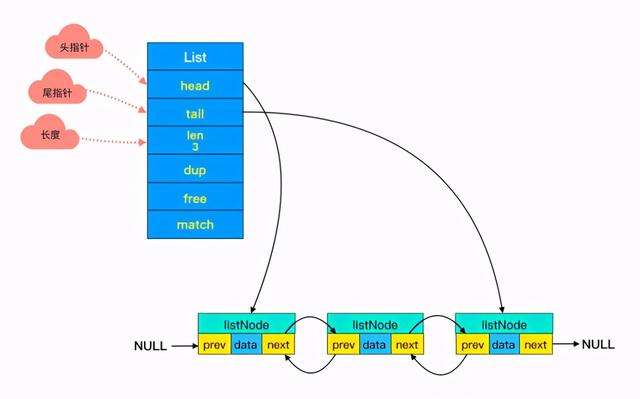 文章插图
文章插图
双端链表
①前后节点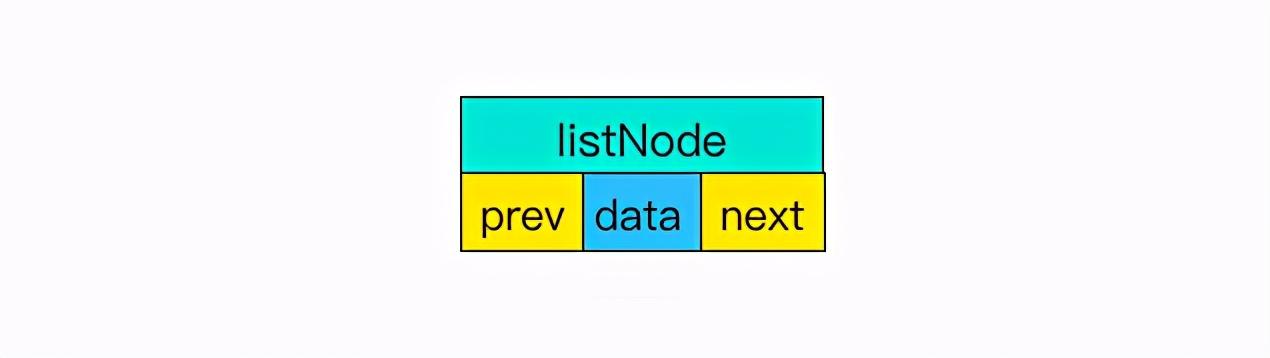 文章插图
文章插图
链表里每个节点都带有两个指针 , prev 指向前节点 , next 指向后节点 。 这样在时间复杂度为 O(1) 内就能获取到前后节点 。
②头尾节点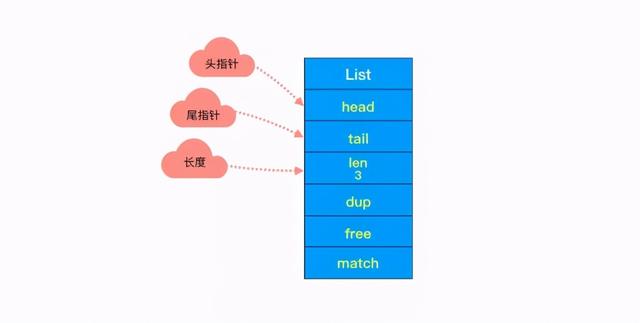 文章插图
文章插图
你可能注意到了 , 头节点里有 head 和 tail 两个参数 , 分别指向头节点和尾节点 。
这样的设计能够对双端节点的处理时间复杂度降至 O(1), 对于队列和栈来说再适合不过 。 同时链表迭代时从两端都可以进行 。
③链表长度
头节点里同时还有一个参数 len , 和上边提到的 SDS 里类似 , 这里是用来记录链表长度的 。
- 直播|150余名主播带货,你pick谁?“2020川货电商节”正式启动
- 任正非|任正非:“谁再建言造车,直接调离岗位!”华为为何这么做?
- 骁龙875|小米11和一加9pro哪个好 一加9pro对比小米11谁更强
- 谁给了|3年价格翻5倍,快“用不起”的共享充电宝,谁给了它涨价的底气
- 纪念版|「同价选机」K30至尊纪念版 vs Note9 Pro,选谁
- 车机|未来汽车,先从未来的"车机"开始
- 付费|谁在定义未来三十年?音频内容付费,60后人数同比增154%,00后增94%
- 红米|都是千元机的标杆!realme真我Q2和红米10X,谁才是水桶机?
- 团购|互联网社区团购,与菜市场商贩,谁更会做生意?
- 舆论|谁在补刀?