对话即数据流:智能对话的新方法( 三 )
【对话即数据流:智能对话的新方法】任何复杂的对话都包含多种可能的意外事件 。 比如“预订与 Megan 开会”的请求可能会失败 , 因为用户的联系人列表中没有一个叫 Megan 的人 , 或者有多个人叫 Megan , 又或者因为没有可预约的时间 , 甚至还有可能因为互联网断开而导致智能助理无法与服务器取得联系 。 这些情况中的每一种都需要不同的响应 。 传统的对话系统通常使用复杂的硬编码逻辑来从这些错误中恢复 。
基于数据流的对话系统通过从数据流图的某个节点抛出“异常”来处理所有这些意外 。 智能助理处理它们的方式是:通过描述“异常”的内容为用户生成适当的警告语句或问询语句 。 而用户在看到这些描述后 , 可以自由地进行回复 , 比如澄清误解 , 或者修改之前的请求 。 举例来说 , 如果有多个叫 Megan 的人 , 那么系统会把这个搜索结果用告知用户 , 而用户或许会通过 “我指的是 Megan Bowen”来澄清 。 系统会将这句话解释为基于上下文的“修改”(revision)请求 , 并生成新的程序 。 这种机制使系统和用户可以在出现错误时灵活地、联系语境地、协作式地对错误进行处理 。
5. 回复的生成也依赖上下文
作为有效的伙伴 , 对话式 AI 系统不仅要学会解释语言 , 而且要能够生成语言 。 传统的对话系统要么采用手写的生成规则(导致 AI 的回复无法根据上下文而变化) , 要么采用非结构化的神经网络语言模型(导致 AI 的回复无法保证真实性) 。 在基于数据流的方法中 , 语言生成是一种被神经网络所引导的数据流操作 。 在语言生成中 , 系统会主动地对数据流进行解析和扩展 。 它可以描述数据流中出现过的任何内容 , 而不只是最后的计算结果 。 它甚至还可以将语言生成过程中新产生的计算和结果添加到数据流中 , 而用户则可以在随后的对话中引用它们: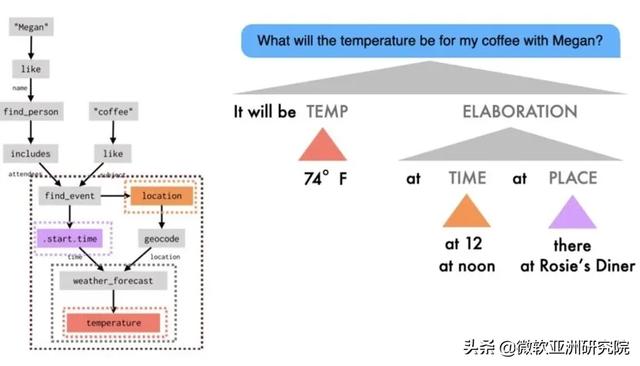 文章插图
文章插图
研究资源:代码 , 数据集和公共排行榜
本文所描述的方法将成为迈向新一代智能对话技术的第一步 。 微软 Semantic Machines 团队的目标是赋予 AI 和人类同等的交流能力 , 但这个问题的最终解决离不开整个社区的参与和努力 。 为了促进对基于数据流的对话系统的研究 , 微软 Semantic Machines 的研究团队还发布了迄今为止最大、最复杂的面向任务的对话数据集:SMCalFlow() 。 该数据集包含了41,517段对话以及对应的数据流程序标注 。 该数据集收集自日历、天气、通信录、地点等交叉领域 , 均为人类间的真实对话 。 对话集合不受限于任何预先指定的剧本 , 即参与者在对话目标以及完成任务的方式上完全不受限制 。 因此 , SMCalFlow 与现存的对话数据集有着本质区别 。 例如 , 某些对话可能包含非常复杂的目标 , 或包含用户和智能助理共同从某个错误中恢复的过程 , 甚至还包含二者关于智能助理能力范围的讨论 。
欢迎大家在 GitHub 的页面上点击数据集、代码和公共排行榜的连接 。 对本论文更加详细的解读 , 请访问知乎专栏 。 非常期待未来自然语言处理社区利用这些资源做出新的发现和创造 。
GitHub:
知乎专栏:
微软 Semantic Machines 团队将继续推动对话式 AI 的发展 。 欢迎加入我们!
()
- 手机|新鲜评测:让手机变身电脑的显示器见过没?只用4步即可完成!
- 三星|高通骁龙875即将登场,三星Exynos 1080成其唯一对手
- 系列|联想碰瓷Redmi后正式复活乐檬手机!乐檬K12系列即将到来
- 骁龙|realme新系列产品即将发布 或将搭载旗舰芯片骁龙875
- 即将|vivo V20 Pro即将发布:骁龙765G处理器加持!
- 曹斌|对话东软睿驰曹斌:软件定义汽车时代,未来最赚钱的还是主机厂
- 用户|马化腾的2020感悟:我相信又一场大洗牌即将开始
- 开售|定好闹铃!Redmi Note 9 Pro即将开售,手慢无货
- 系列|realme 副总裁:骁龙新旗舰即将登场,realme 新系列即将到来
- 电视|3分钟即告售罄 OPPO电视能走出“围城”?