对话即数据流:智能对话的新方法( 二 )
 文章插图
文章插图
一旦该程序被神经网络预测出来 , 智能助理便可以执行该程序 , 并根据结果对用户进行回复 , 再将结果存储在数据流图中 。
2. 任务型对话是交互式编程
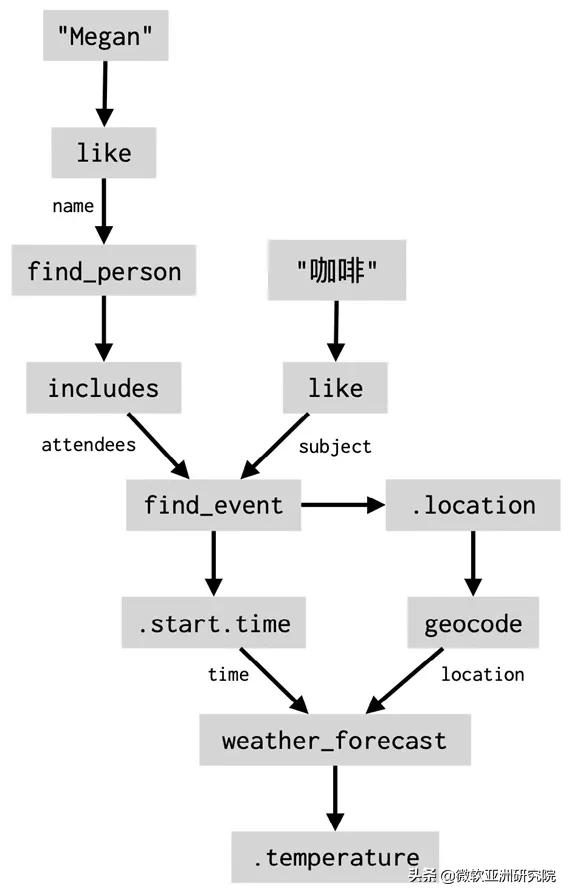
使用数据流的好处之一是 , 它可以自然地表示多轮对话中用户和机器人反复的交互过程 。 如果用户问“约 Megan 喝咖啡是什么时候” , 系统会生成如下的数据流片段: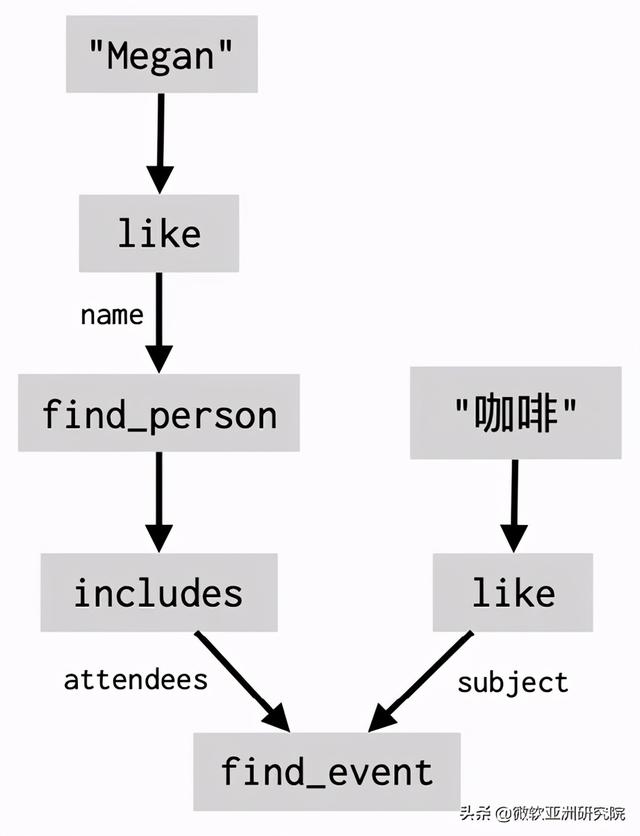 文章插图
文章插图
如果用户在下一轮提出“那里的天气如何” , 那么回答新问题所需的大部分工作实际上已经在第一轮完成 , 系统则可以回溯上一轮的程序片段 , 将其输出反馈到一个新的 API 调用中 , 然后描述其结果: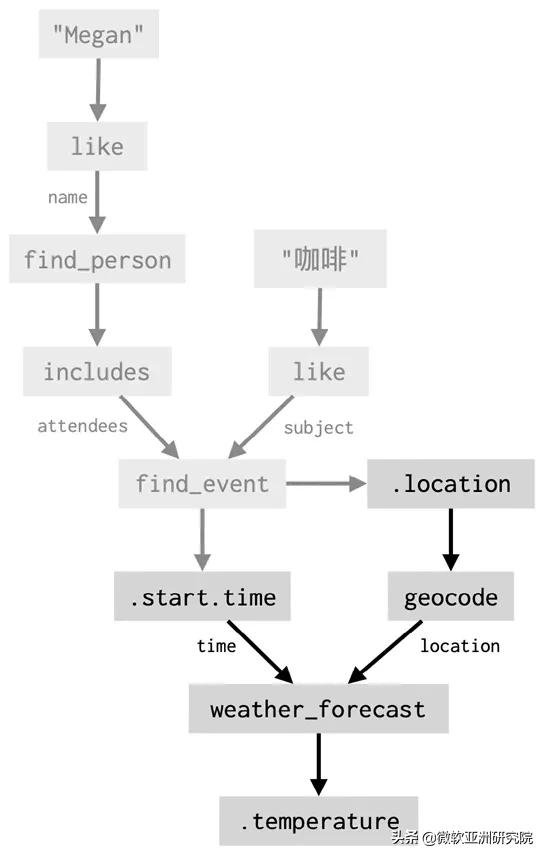 文章插图
文章插图
该过程得到的结果与先前为复合式问题(“约 Megan 喝咖啡的时候气温如何”)生成的程序完全相同 。 这种重用是数据流框架的核心功能——通过对一系列简单的操作进行组合 , 而不是定义大量的顶层操作 , 来实现复杂的目标 。 这种组合可以在第一轮对话中发生 , 也可以逐轮进行 , 形成逐步扩展的数据流 。
3. 语义依赖于上下文
我们可以把逐步扩展的数据流看作整段对话的“对话状态” 。 它记录了智能助理到目前为止为了理解语义、提供服务、回复用户而进行过的所有计算 。 此后的每段语义都将在数据流的基础上(通过深度学习)进行解析 , 它们可以参考和使用现存的所有计算及其结果 。 通过设计对数据流中的节点进行引用和复用的机制 , 可以显著提高对话系统的数据利用效率和机器学习的准确性 。 这也让工程师们可以更容易理解和控制智能助理的行为 。
在前面的示例中 , 用户使用了单词“那里”来指代数据流图中的现存节点 。 诸如此类的语言现象还包括“那个”、“她”、“你提到的第二个会议“等 。 这些都表示用户希望引用对话中提到过的某个值或某个实体 。
这类引用也可能隐式地发生 。 想象一下 , 当你询问智能设备“天气会怎样”时 , 通常你想知道当地近期的天气 。 但是 , 如果你在提到某个未来的事件后问了同样的问题 , 则可能是在询问该事件期间以及对应地点的天气 。 解决这两种情况需要两个不同的计算图 。 如下图所示 , 左边的计算用于获得当地近期的天气 , 右侧的计算则用于获得特定事件的天气: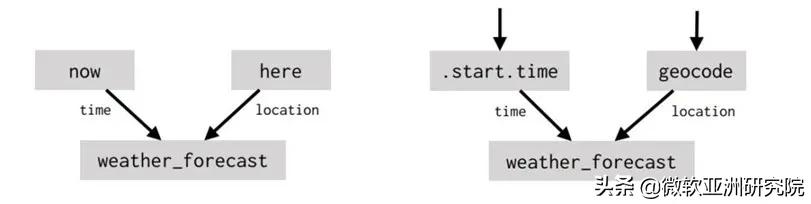 文章插图
文章插图
通过上下文区分这两种情况是一个颇有挑战性的机器学习问题(更不用说还可能有其他情况了) 。 但从直觉上讲 , “天气会怎样”这句话在两种情况下的含义是相同的 , 即用户想知道与对话环境最相关的时间和地点的天气 。
在基于数据流的对话系统中 , 上述推理被显示地表达了出来:在解析用户请求时 , 智能助理会生成显示引用现有计算片段的程序 。 这里 , 这些片段既包括前一轮的计算 , 也包括 here 和 now 这种在对话开始前就默认存在的实体 。 对于上面的两个示例 , 生成的数据流看起来像这样: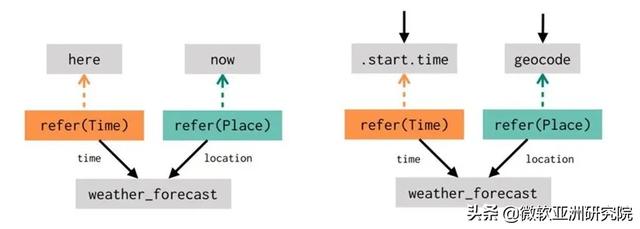 文章插图
文章插图
换句话说 , 在两段对话里 , 系统对“天气会怎样”的解析是相同的 。 它通过调用 refer (Time) 和 refer (Place) 生成了相同的数据流片段 , 但在该程序片段被执行时 , 它的实际解释则会根据上下文而改变 。
下面是一个与上下文互动更紧密的例子 。 假设用户问:“公司聚会的时候呢” 。 这里 , 用户希望智能助理在修改一些细节(把事件修改为“公司聚会”)后提供先前问题(查询天气预报)的新答案 。 这种需求被称为修改(revision) 。 像引用一样 , 基于数据流的对话系统引入了一种名为“修改”(revision)的机制来应对上述需求 , 使简单的用户语句可以对应复杂的数据流变换 。 以下是系统在处理“约 Megan 喝咖啡的时候气温如何”以及 “公司聚会的时候呢”之后 , 大致的数据流图: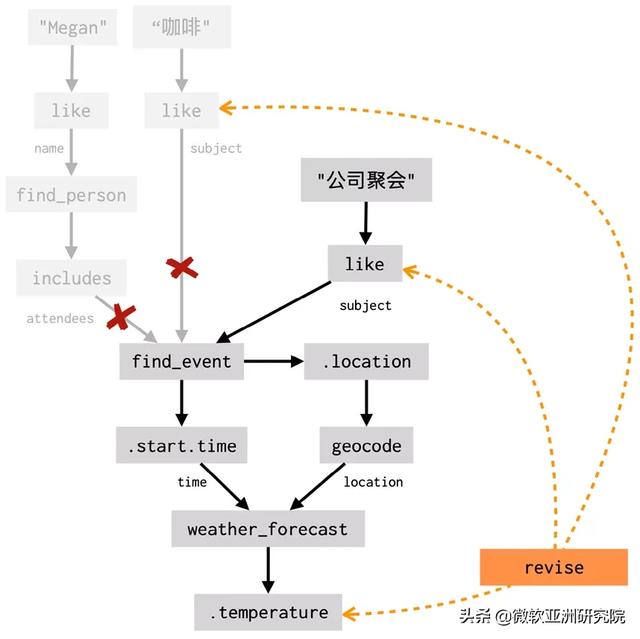 文章插图
文章插图
在这里 , 第一轮搜索所使用的约束(参与者包含“Megan” , 标题匹配“咖啡”)被新的约束(标题匹配“公司聚会”)替换 。 (有关“修改”机制的更多详细信息 , 可点击阅读原文 , 从论文中了解更多)
4. 事情可能会出错
- 手机|新鲜评测:让手机变身电脑的显示器见过没?只用4步即可完成!
- 三星|高通骁龙875即将登场,三星Exynos 1080成其唯一对手
- 系列|联想碰瓷Redmi后正式复活乐檬手机!乐檬K12系列即将到来
- 骁龙|realme新系列产品即将发布 或将搭载旗舰芯片骁龙875
- 即将|vivo V20 Pro即将发布:骁龙765G处理器加持!
- 曹斌|对话东软睿驰曹斌:软件定义汽车时代,未来最赚钱的还是主机厂
- 用户|马化腾的2020感悟:我相信又一场大洗牌即将开始
- 开售|定好闹铃!Redmi Note 9 Pro即将开售,手慢无货
- 系列|realme 副总裁:骁龙新旗舰即将登场,realme 新系列即将到来
- 电视|3分钟即告售罄 OPPO电视能走出“围城”?