为什么不管大厂还是小厂,面试总是要提到 HashMap?( 二 )
扩容过程 , 我们就需要涉及以下几个核心参数:
- 扩展因子:loadFactor
- 实际元素数量:size
- 数组长度:capacity
- 扩容的阈值大小:threshold=capacity*loadFactor
JDK1.7 扩容的时候 , HashMap 每个元素将会重新计算 Hash 值 , 然后使用寻址算法 , 查找新的位置 。
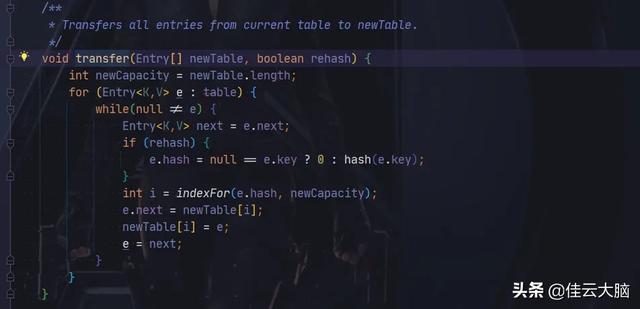 文章插图
文章插图在 JDk1.8 中 , 采用了一种更精妙的算法:
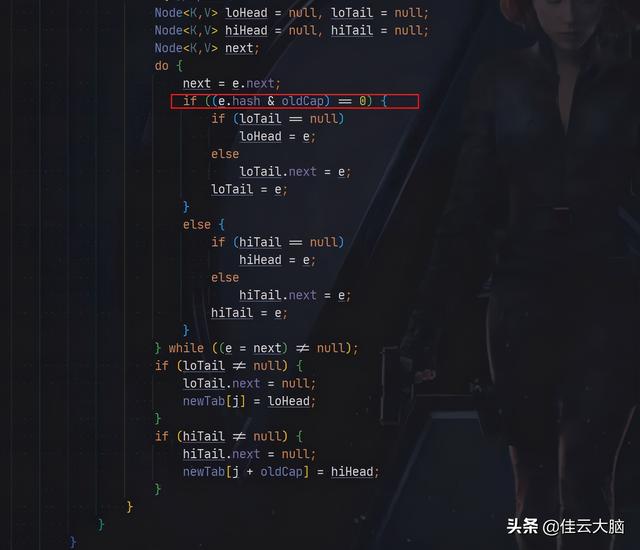 文章插图
文章插图其使用 e.hash--tt-darkmode-color: #9B9B9B;">这里解释起来比较复杂 , 这里阿粉就不再详细展开 , 感兴趣同学可以自行查找一下相关文章 。
面试题问:加载因子为什么 0.75 , 而不是其他值?
答:可以说是一个经过考量的经验值 。 加载因子涉及扩容 , 下次扩容的阈值=数组桶的大小*加载因子 , 如果加载因子太小 , 这就会导致阈值太小 , 这就会导致比较容易发生扩容 。
如果加载因子太大 , 那就会导致阈值太大 , 可能冲突会很多 , 导致查找效率下降 。
多线程并发好了 , 终于到到了最后一个知识点 , 多线程并发 。
HashMap 在多线程并发情况下会怎么样?
这里我们需要分 JDK1.7 与 JDK1.8 来讲 。
在 JDK1.7 中 , 由于扩容迁移时采用了头插法 , 从而将会导致产生死链 。
void transfer(Entry[] newTable, boolean rehash) {int newCapacity = newTable.length;for (Entry e : table) {while(null != e) {Entry next = e.next;if (rehash) {e.hash = null == e.key ? 0 : hash(e.key);}int i = indexFor(e.hash, newCapacity);// 以下代码导致死链的产生e.next = newTable[i];// 插入到链表头结点 ,newTable[i] = e;e = next;}}} 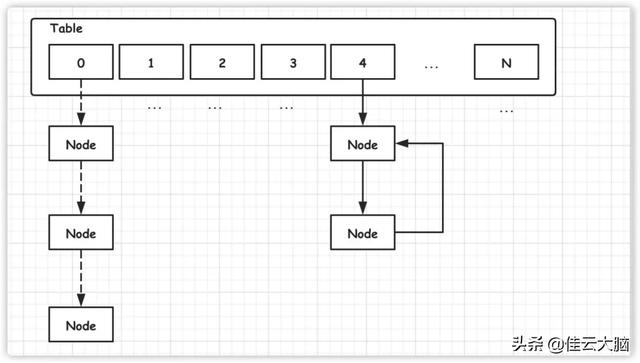 文章插图
文章插图而一旦产生死链 , 极有可能导致程序陷入死循环 , 从而导致 CPU 使用率上升 。
JDK1.8 中使用尾插法 , 从而解决这个问题 , 但是依然还会存在相关问题 。
比如:
并发赋值时被覆盖
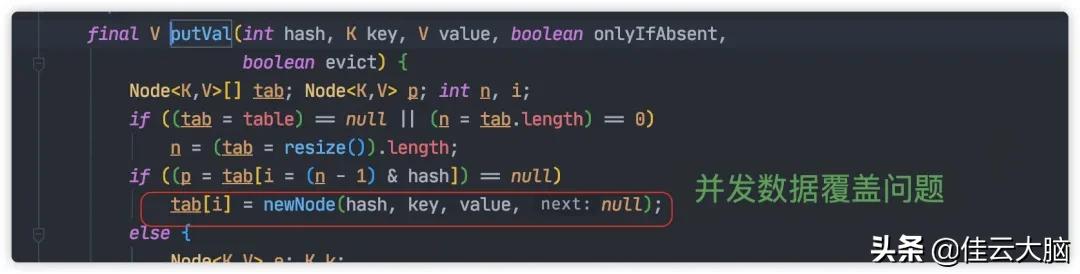 文章插图
文章插图并发的情况下 , 一个线程的赋值可能被另一个线程覆盖 , 这就导致对象的丢失 。
size 计算问题
 文章插图
文章插图img
每次元素增加完成之后 , size 将会加 1 。 这里采用 ++i方法 , 天然的并发不安全 。
面试题关于并发 , 这里可以提到很多面试题 。
可以是线程相关的 , 也可以是并发编程相关 。
不过如果面试官既然已经提到这里 , 我们可以试着将他引导他如何解决 HashMap 并发编程的问题 , 从而我们下面开始回答出 ConcurrentHashMap 。
最后经过上面一顿分析 , 我们可以看到小小一个 HashMap 其实涉及到很多知识点 , 这些点拆开来讲就可以变成一道道面试题 。
另外这些点在平常编程的过程中也要特别注意 , 一不小心我们就会踩一个大坑 。
【为什么不管大厂还是小厂,面试总是要提到 HashMap?】今天这篇文章主要提及一下 , HashMap 涉及的知识点 , 所以阿粉没有过多深入的分析 , 这里感兴趣的同学可以在深入学习准备一下 。
- 看不上|为什么还有用户看不上华为Mate40系列来看看内行人怎么说
- 制药领域|为什么AI制药这么火,为什么是现在?
- 手机壳里头|为什么要在手机壳里面夹钱?10个有9个不懂,我才知道大有讲究
- 短视频|全球最火APP?抖音爆火背后离不开这几剂“猛药”为什么抖音能够这么火?
- 电商快递|包邮不香吗,为什么还有人加49元让小哥穿西装专车送快递?
- 团队|为什么项目管理非常重要?
- 猫腻|为什么拼多多上商品价格那么便宜还包邮?有什么猫腻?看完明白了
- 刷机|前几年满大街的“刷机”服务去哪里了,为什么大家都不爱刷机了?
- 手机|便宜没好货!为什么二手iPhone很便宜,这些手机都来自哪儿?
- 中国|相对论Vol.48丨一个“歪果仁”,为什么要在海外电商平台直播带中国货