按关键词阅读:
台积电
芯片
索尼公司
日本政府
工厂
补贴
量产

文章插图
随着网络上各种信息的指数级增长,以及跨语言获取信息的需求不断增加,机器翻译逐渐成为网上冲浪??♀?时必不可少的工具。网页翻译让我们在 Reddit 等外国论坛里和网友谈笑风生;火山同传等智能字幕翻译系统让我们无需等待字幕组,直接观看“生肉”剧集;聊天翻译让我们建立跨国贸易,结交外国友人。然而,上面提到的场景往往有一个共同点,那就是被翻译的文本往往是不规范的。无论是聊天时手误导致的错别字,还是视频语音原文识别的错误,都会极大地影响译文质量。因此,实际应用场景下的机器翻译对翻译模型的鲁棒性有很高的要求。
今天就为大家介绍一篇由字节跳动人工智能实验室火山翻译团队发表在 EMNLP 2021 Findings 的短文 - Secoco: Self-Correcting Encoding for Neural Machine Translation。这篇论文让翻译模型在学习翻译任务的同时,学习如何对输入的带噪文本进行纠错,从而改善翻译质量。

文章插图
论文地址:https://arxiv.org/abs/2108.12137代码地址:https://github.com/rgwt123/Secoco神经机器翻译在近些年取得了很大进展,但是大部分工作都是基于干净的数据集。在现实生活中,神经机器翻译系统面对的输入往往都是包含噪声的,这对翻译模型的鲁棒性提出了很大挑战。
之前的翻译鲁棒性工作主要分为三类:
- 第一类是针对模型生成对抗样例,这些生成的对抗样例被用于一起重新训练模型。
- 第二类是针对训练数据,通过过滤训练数据中的噪声来提升模型质量。
- 第三类则是专注于处理输入中包含的天然噪声,他们使用规则,回翻等方法来合成噪声,并混合到原始数据中一起训练。
可以看到,大部分的工作都专注于如何生成噪声,很少探究如何进一步使用它们;本文则想要通过建模从噪声数据到干净数据的修正过程,从而增强模型的鲁棒性。
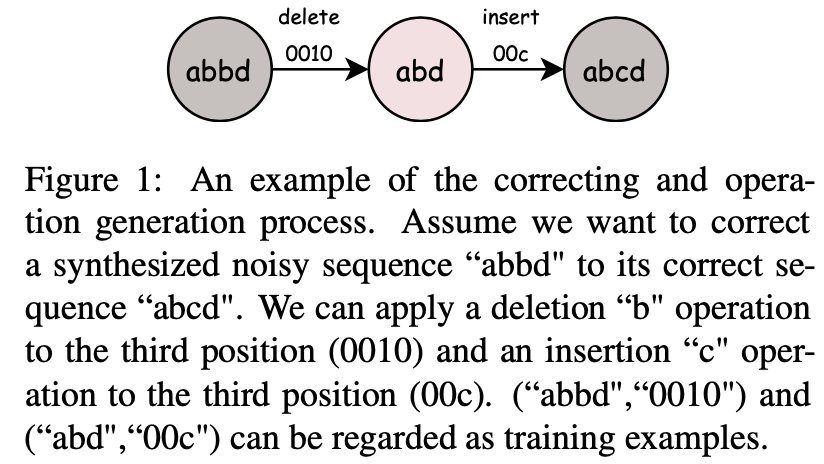
文章插图
如图 1 所示,如果想要把一个带噪序列 "abbd" 修正为 "abcd" ,那么可以先删除第三个位置的 "b",再在第三个位置插入 "c"。也就是说,可以将对带噪文本的修正转化为插入和删除的序列,并在编码器端显式地建模这一过程。作者针对神经机器翻译提出了具有鲁棒性的自修正框架Secoco (Self-correcting Encoding)。
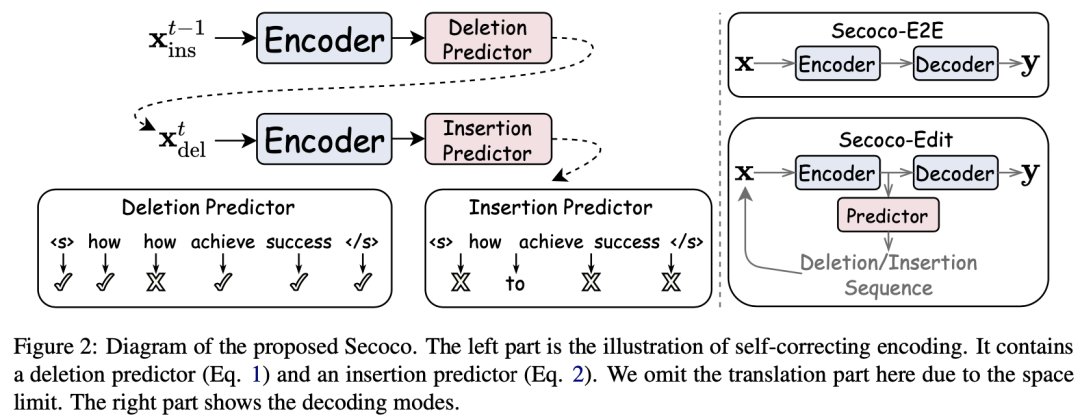
文章插图
图2 整体模型架构
正如图2左侧所示,Secoco 和普通的翻译模型不同之处在于 Secoco 有两个修正操作的预测模块,这些预测模块基于输入序列的表示生成相应的操作序列。删除预测器 (Deletion Predictor) 根据当前词的表示预测是否要删除,而插入预测器 (Insertion Predictor) 则根据两个连续的词的表示预测中间是否要插入新的词。虽然这种迭代编辑的过程每一步都需要前面的操作,但是为了简化训练过程,插入预测器和删除预测器都是相互独立的,并与普通的翻译任务同时进行训练。
一个关键的问题是如何生成这些训练数据?关键点在于获取从带噪数据转化为干净数据的编辑操作。作者提供了两种方式。一种是针对有带噪数据和对应干净 reference 数据的情况,一种是没有带噪数据的情况。
对于有reference的数据,可以使用类似计算最短编辑距离的方法,获取从带噪数据转化为干净数据的最短编辑过程,然后将替换操作转化为删除-插入操作。
对于没有reference的数据,可以使用基于规则的方法生成伪数据。针对不同的场景,可以设计对应的规则,然后从干净的数据中生成带噪数据,最后反向这个过程就可以得到编辑过程。
【 模型|EMNLP2021 Findings|字节火山翻译提出:基于自修正编码器的神经机器翻译】训练完成后,便可以进行解码。正如图2右侧展示的,Secoco 有两种解码方式。第一种是仅使用编码器-解码器结构直接进行翻译 (Secoco-E2E),另一种则是对输入进行迭代编辑后再进行翻译 (Secoco-Edit)。
稿源:(雷峰网)
【傻大方】网址:/c/1125a51C2021.html
标题:模型|EMNLP2021 Findings|字节火山翻译提出:基于自修正编码器的神经机器翻译