按关键词阅读: 台积电 芯片 索尼公司 日本政府 工厂 补贴 量产

文章插图
如表1所示,对话测试集包含主语省略,标点省略,错别字等问题;语音测试集包含口语词,错别字等 ASR 引起的问题;WMT14 则包含由规则构造的随机插入,随机删除,重复等问题。
实验结果如表2所示。除了 Secoco 之外,作者还和3种方法进行了对比,分别是将合成的噪声数据加入原始数据中一起训练 (BASE+synthetic);使用修复模型加上翻译模型的 pipeline 级联结构 (REPAIR);以及多编码器-单解码器的结构 [1] (RECONSTRUCTION)。可以看出,所有的方法相较于基线模型都有所提升。Secoco 在三个测试集上都获得了最好的效果。

文章插图
此外,在这三个测试集中,对话测试集明显包含更多的噪声,Secoco 最多可以带来3个 BLEU 的提升。语音测试集由于是由 ASR 导出的,因此最好的结果也仅有12.4。
文章插图
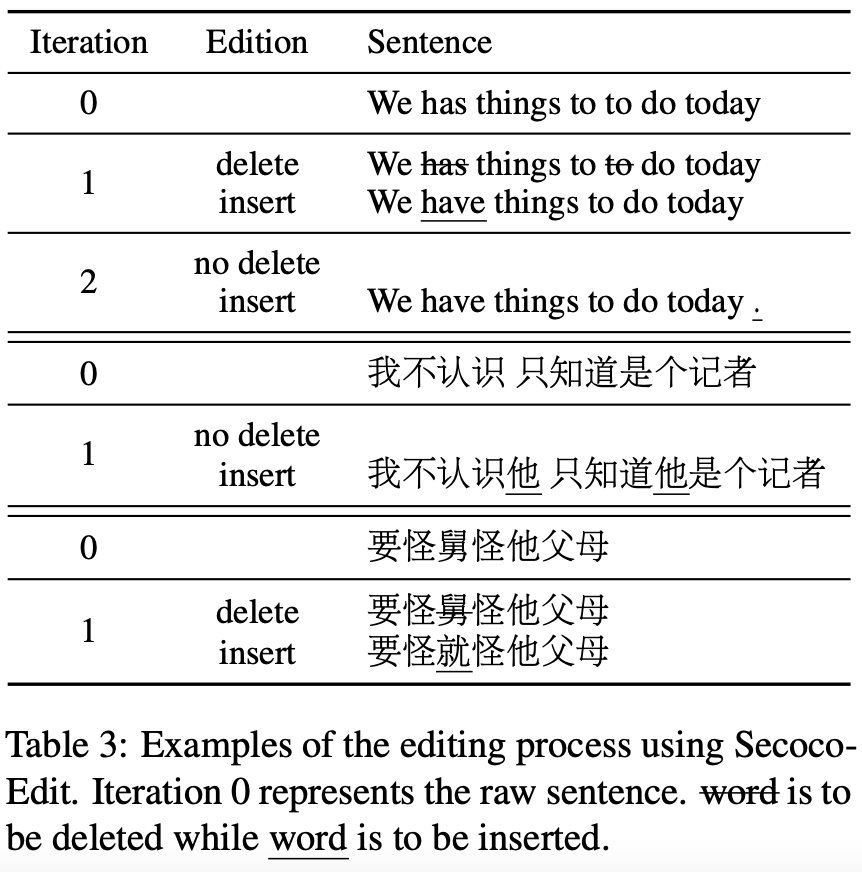
表格3中给出了一些迭代编辑的具体例子。针对每一句输入,模型对其进行迭代删除和插入操作,直到文本不再发生变化。从例子中可以看到,一次编辑操作可以同时删除或者插入多个词。此外,对于上述的测试集,平均每个句子需要2-3次编辑操作。

文章插图
雷峰网
![]()
稿源:(雷峰网)
【傻大方】网址:/c/1125a51C2021.html
标题:模型|EMNLP2021 Findings|字节火山翻译提出:基于自修正编码器的神经机器翻译( 二 )