专治|专治各种不明白,一文带你了解“对抗样本原理”
【 专治|专治各种不明白,一文带你了解“对抗样本原理”】人工智能技术具有改变人类命运的巨大潜能,但同样存在巨大的安全风险。攻击者通过构造对抗样本,可以使人工智能系统输出攻击者想要的任意错误结果。从数学原理上来说,对抗攻击利用了人工智能算法模型的固有缺陷。本文以全连接神经网络为例来介绍对抗样本对人工智能模型作用的本质。
一、背景近年来,随着海量数据的积累、计算能力的提高、机器学习方法与系统的持续创新与演进,人工智能技术取得了重大突破,成功应用于图像处理、自然语言处理、语音识别等多个领域。在图像分类、语音识别等模式识别任务中,机器学习的准确率甚至超越了人类。
人工智能技术具有改变人类命运的巨大潜能,但同样存在巨大的安全风险。这种安全风险存在的根本原因是机器学习算法设计之初普遍未考虑相关的安全威胁,使得机器学习算法的判断结果容易被恶意攻击者影响,导致AI系统判断失准。2013年,Szegedy等人首先在图像分类领域发现了一个非常有趣的“反直觉”现象:攻击者通过构造轻微扰动来干扰输入样本,可以使基于深度神经网络(DNN)的图片识别系统输出攻击者想要的任意错误结果。研究人员称这类具有攻击性的输入样本为对抗样本。随后越来越多的研究发现,除了DNN模型之外,对抗样本同样能成功地攻击强化学习模型、循环神经网络(RNN)模型等不同的机器学习模型,以及语音识别、图像识别、文本处理、恶意软件检测等不同的深度学习应用系统。
从数学原理上来说,对抗攻击利用了人工智能算法模型的固有缺陷,即人工智能算法学习得到的只是数据的统计特征或数据间的关联关系,而并未真正获取反映数据本质的特征或数据间的因果关系,并没有实现真正意义上的“智能”。本文以全连接神经网络为例来介绍对抗样本对人工智能模型作用的本质。
二、对抗样本简介神经网络是目前人工智能系统中应用最广泛的一种模型,是一种典型的监督学习模型。尽管例如生成式对抗网络(Generative Adversarial Networks, GAN)等模型号称是无监督算法,但是其本质是将神经网络进行组合而来,模型中每个神经网络仍然是监督学习算法。对于最基本的神经网络来说,其训练过程如图1所示。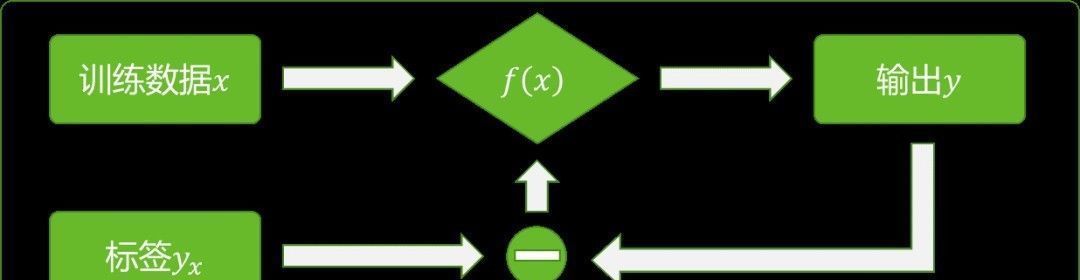
文章插图
图1 神经网络训练过程
神经网络模型可以被看成是一个从数据集到标签集的映射,用y=f(x)表示,其中,x 为神经网络的输入数据,y为输出数据,yx为数据x对应的标签。在训练过程中,对于输入数据x,比较神经网络的输出y与标签yx,根据二者的差值来更新神经网络模型y=f(x)中的参数,即权重和偏置的值。训练好的模型即可以用来进行分类。对抗样本对模型y=f(x)的影响如图 2所示。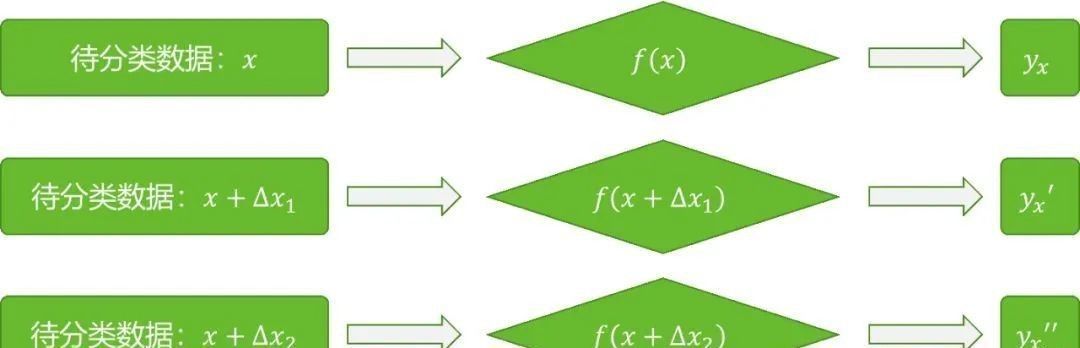
文章插图
图2 对抗样本对神经网络模型的影响
对输入数据x中加入一个扰动量(图2中的?x1和?x2),可以使模型y=f(x)的输出发生较大的变化。通常,扰动量‖?x1‖和‖?x2‖都很小。例如在图像识别的应用中,只改变输入图像中的少部分像素,甚至只修改一个像素的值,就可能使分类器做出错误的判断。对于一个已经训练好的模型y=f(x)来说,并不是对所有的输入数据x进行扰动都可以使其输出发生较大的改变,同时,对于一个输入数据x,往往也需要加入特定类型的扰动才会使模型输出发生变化。也就是说对抗样本的生成需要具备一定的条件。那么对抗样本与模型的关系是什么呢?接下来通过具体的案例来说明。
三、案例分析理想的二分类问题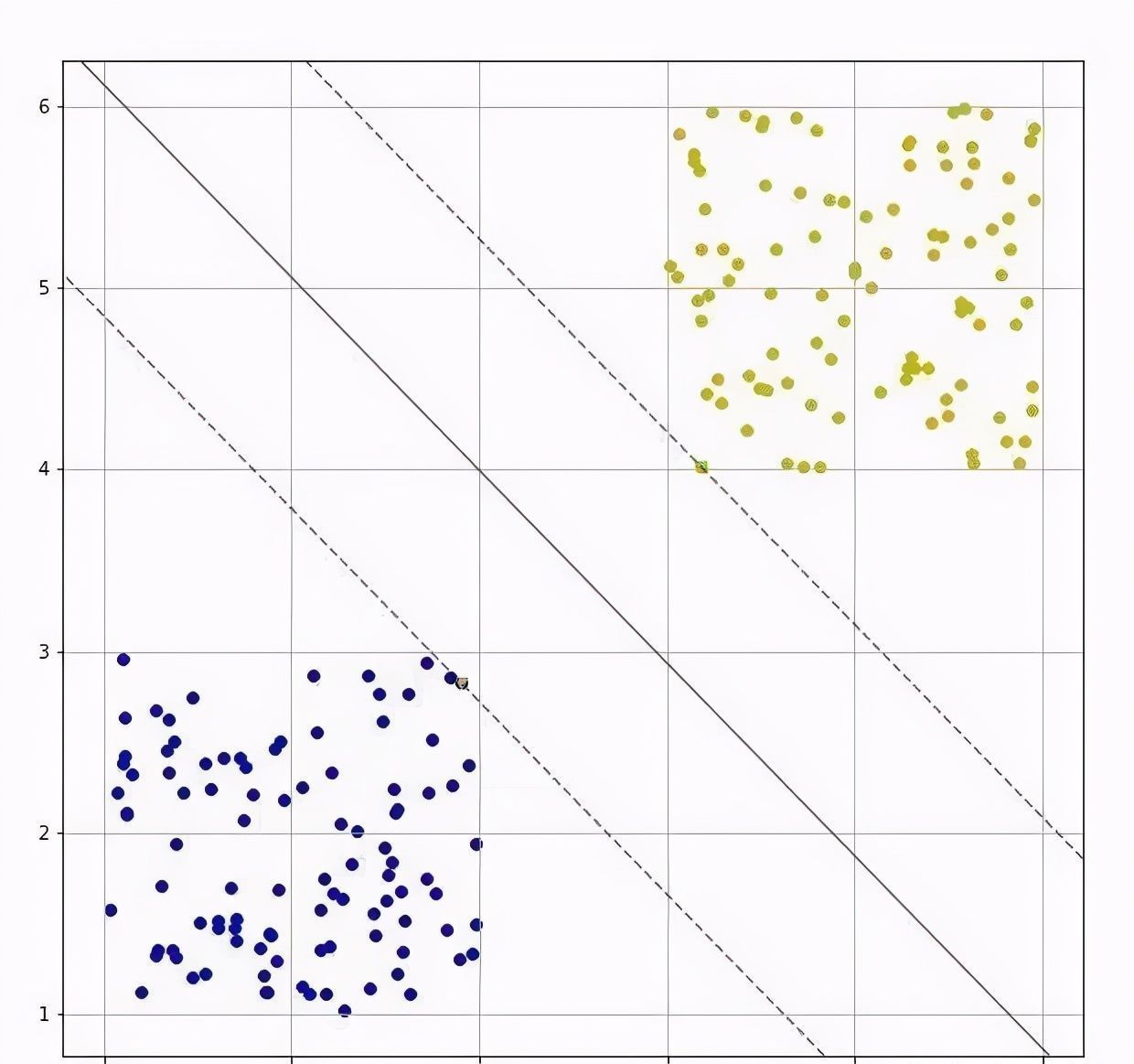
文章插图
图3 理想的二分类问题
图3所示是一个线性二分类问题。两个类别之间差异度较大,因此可以较容易的找出两个类别的分类边界。而对于实际的问题来说,待分类数据的分布情况往往不可知。同时,实际问题的复杂性,噪声干扰等因素导致待分类数据集中不同类别数据之间的区分度并不明显。下面针对几种典型的数据集的二分类问题分别讨论。
线性二分类问题
考虑如图4所示的数据集。该数据集中的两个类别都是高斯分布。由于特征提取,数据噪声等原因,与图3中的数据集相比,该数据集中两类数据的距离较近,且有部分数据互相交叉,也就是说两类数据的区分度不明显。对该数据集采用神经网络模型进行分类,其模型的等高线图如图5所示。
- 看不上|为什么还有用户看不上华为Mate40系列来看看内行人怎么说
- 闲鱼|电诉宝:“闲鱼”网络欺诈成用户投诉热点 Q3获“不建议下单”评级
- 整形美容|双十一医美不良事件高发 热玛吉风险高 业内:医美职业打假人太少
- 美国|英国媒体惊叹:165个国家采用北斗将GPS替代,连美国也不例外?
- 手机基带|为了5G降低4G网速?中国移动回应来了:罪魁祸首不是运营商
- 面临|“熟悉的陌生人”不该被边缘化
- 车企|华为不造车!但任正非加了一个有效期,3年
- 当初|这是我的第一部华为手机,当初花6799元买的,现在“一文不值”?
- 不负众望|12小时卖了30万部!Redmi Note9不负众望,卢伟冰开心了?
- 蛋壳公寓|官媒发声:绝不能让“割韭菜者”一跑了之!