「计算机组成原理」:高速缓存存储器
一旦从存储器读入一个数据对象时 , 就尽可能使用它 , 使得时间局部性最大 。 特别是局部变量 , 编译器会将其保存在寄存器中 。这一章主要介绍存储器层次结构中的高速缓存部分 , 包含在CPU中 , 使用SRAM存储器实现 , 完全由硬件管理 。
- 当高速缓存大小大于数据的大小 , 如果分配良好 , 则只会出现冷不命中 。
- 缓存不命中比内存访问次数影响更大
- 由内存系统的设计来决定块大小 , 是内存系统的固定参数 。 首先决定块大小 , 然后决定期望的缓存大小 , 然后再决定关联性 , 最终就能知道组的数目 。
- 块的目的就是利用空间局部性
- 缓存是硬件自动执行的 , 没有提供指令集对其进行操作
- 建议:将注意力集中在内循环中 , 因为大部分的计算和内存访问都集中在这里按照数据对象存储在内存中的顺序 , 以步长为1来读数据 , 使得空间局部性最大 。 比如步长为2的命中率就比步长为1的命中率降低一半 。 一旦从存储器读入一个数据对象时 , 就尽可能使用它 , 使得时间局部性最大 。 特别是局部变量 , 编译器会将其保存在寄存器中 。
1 高速缓存存储器较早期的计算机系统的存储器层次结构只有三层:CPU寄存器、主存和磁盘 , 但是随着CPU的发展 , 使得主存和CPU之间的读取速度逐渐拉大 , 由此在CPU和主存之间插入一个小而快速的SRAM高速缓存存储器 , 称为L1高速缓存 , 随着后续的发展 , 又增加了L2高速缓存和L3高速缓存 。
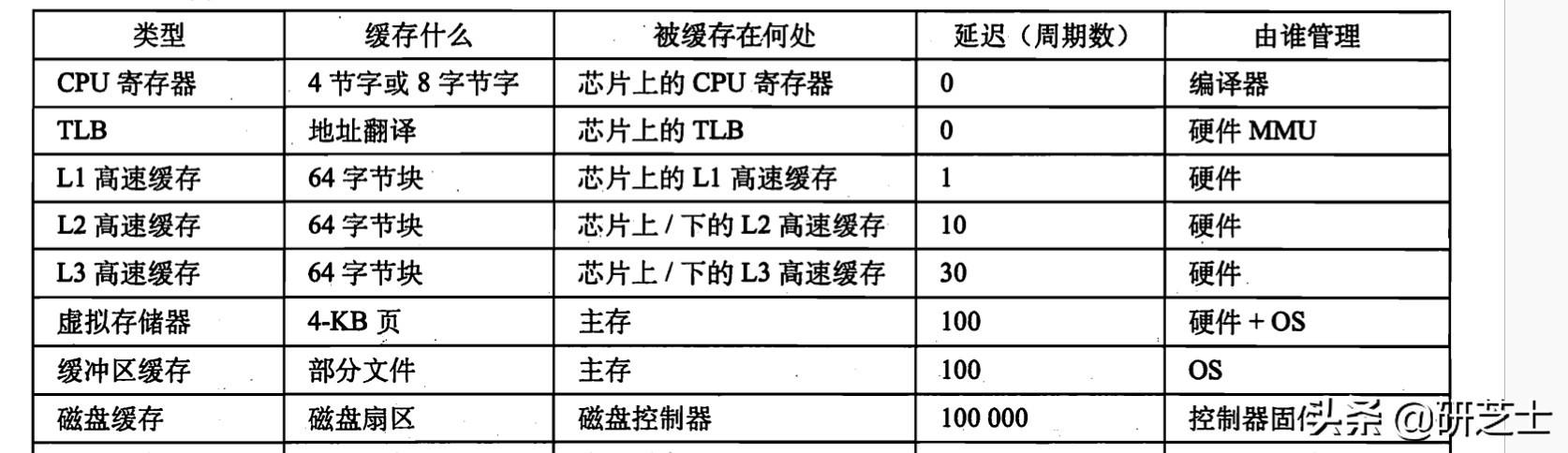 文章插图
文章插图1.1 通用的高速缓存存储器组织结构
 文章插图
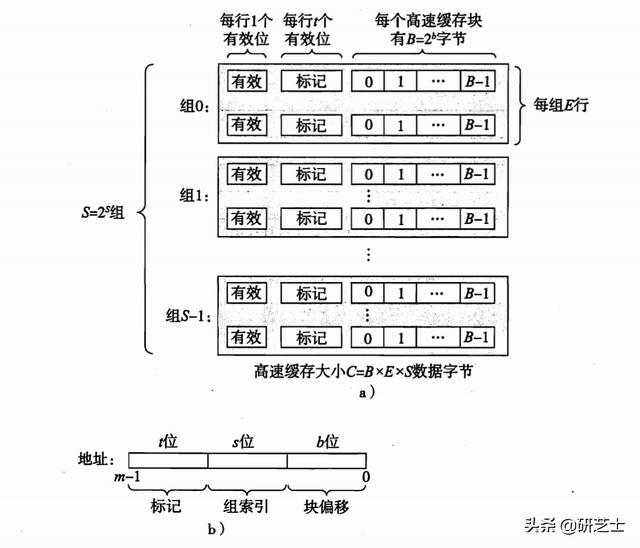
文章插图如上图的b中所示 , 会将m位的的址划分成三部分:
- s位:高速缓存被组织成一个数组 , 而该数组通过 $$ S=2^{s} $$ 进行索引 。
- b位:每个组中包含E个高速缓存行(Cache Line) , 每个行有一个 $$ B=2^{b} $$ 字节的数据块(Block)组成 。
- t位:每一个高速缓存行有一个 $$ t=m-(s+b) $$ 位的标记位(Valid Bit) , 唯一表示存储在这个高速缓存行中的数据块 , 用于搜索数据块 。
 文章插图
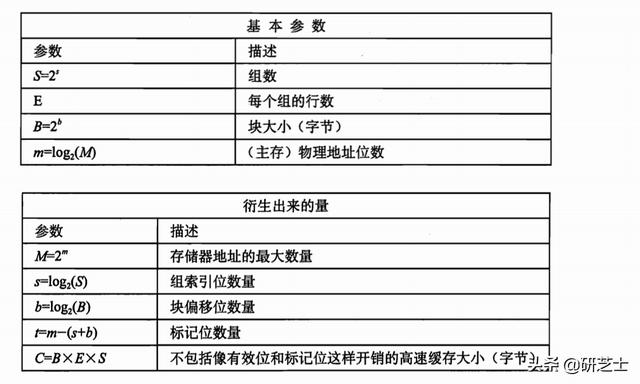
文章插图该高速缓存的结构可以通过元组(S, E, B, m)来描述 , 且容量C为所有块的大小之和 ,C= S \times E \times BC=S×E×B。
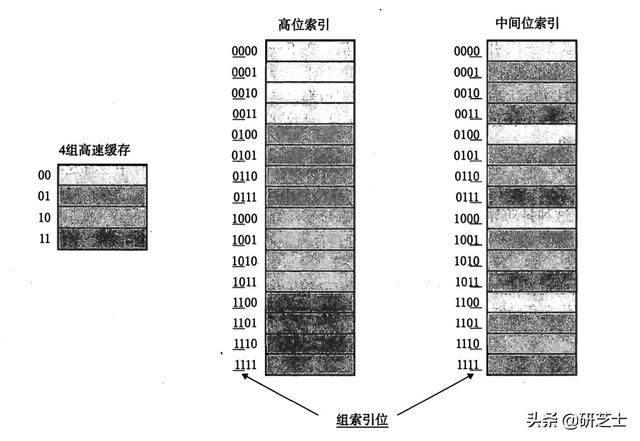
注意:如果将组索引放在最高有效位 , 则连续的内存块就会映射到相同的高速缓存组中 , 通过将组索引放在中间 , 可以使得连续的内存块尽可能分散在各个高速缓存组中 , 可以充分利用各个高速缓存组
 文章插图
文章插图当一条加载指令指示CPU从主存地址A中读取一个字w时 , 会将该主存地址A发送到高速缓存中 , 则高速缓存会根据以下步骤判断地址A是否命中:
- 组选择:根据地址划分 , 将中间的s位表示为无符号数作为组的索引 , 可得到该地址对应的组 。
- 行匹配:根据地址划分 , 可得到t位的标志位 , 由于组内的任意一行都可以包含任意映射到该组的数据块 , 所以就要线性搜索组中的每一行 , 判断是否有和标志位匹配且设置了有效位的行 , 如果存在 , 则缓存命中 , 否则缓冲不命中 。
- 字抽取:如果找到了对应的高速缓存行 , 则可以将b位表示为无符号数作为块偏移量 , 得到对应位置的字 。
注意:为了使得地址中的b位能够编码块偏移量 , 要求从下一层存储器中 , 根据块偏移量的值从中截取出块大小的数据块 。
该编码方式具有以下特点:
- 能够通过组索引位来唯一确定高速缓存组
- 映射到同一个高速缓存组的块由标志位唯一地标识
- 标记位和组索引位能够唯一的表示内存中的每个块
- 有可能会存在多个块映射到同一个高速缓存组中(只要地址的组索引相同)
- 计算机学科|机器视觉系统是什么
- 合并|Andre Cronje主导批量「合并」DeFi项目,是好事情吗?
- mini|电影、mini 与「当日完稿」工作流
- 字化转型|疫情重构经济,传统企业「数字化」的通关密码是什么?
- iPhone12|iPhone12「超大杯」拍照解禁:与Pro拉不开差距
- 供应链|一座快手「重镇」的货端升级
- 项目|DeFi「分叉运动」退潮,我们能从中学到什么?
- 纪念版|「同价选机」K30至尊纪念版 vs Note9 Pro,选谁
- 文案|「热点传递」为什么别人卖点写的“勾人”?
- 系列|OPPO Reno5 真机曝光, 「Reno Glow」晶钻设计再升级