速度超快!字节跳动开源序列推理引擎LightSeq( 三 )
动态显存复用
为了避免计算过程中的显存申请释放并节省显存占用 , LightSeq 首先对模型中所有动态的 shape 都定义了最大值(例如最大序列长度) , 将所有动态shape转换为静态 。 接着在服务启动的时候 , 为计算过程中的每个中间计算结果按最大值分配显存 , 并对没有依赖的中间结果共用显存 。 这样对每个请求 , 模型推理时不再申请显存 , 做到了:不同请求的相同 Tensor 复用显存;同请求的不同 Tensor 按 shape 及依赖关系复用显存 。
通过该显存复用策略 , 在一张 T4 显卡上 , LightSeq 可以同时部署多达 8 个 Transformer big 模型(batch_size=8 , 最大序列长度=8 , beam_size=4 , vocab_size=3万) 。 从而在低频或错峰等场景下 , 大大提升显卡利用率 。
层级式解码计算
在自回归序列生成场景中 , 最复杂且耗时的部分就是解码 。 LightSeq 目前已经支持了 beam search、diversity beam search、top-k/top-p sampling 等多种解码方法 , 并且可以配合 Transformer、GPT使用 , 达到数倍加速 。 这里我们以应用最多的 beam search 为例 , 介绍一下 LightSeq 对解码过程的优化 。
首先来看下在深度学习框架中传统是如何进行一步解码计算的:
# 1.计算以每个token为结尾的序列的log probability
log_token_prob = tf.nn.log_softmax(logit) # [batch_size, beam_size, vocab_size]log_seq_prob += log_token_prob # [batch_size, beam_size, vocab_size]log_seq_prob = tf.reshape(log_seq_prob, [-1, beam_size * vocab_size])
# 2. 为每个序列(batch element)找出排名topk的token
topk_log_probs, topk_indices = tf.nn.top_k(log_seq_prob, k=K)
# 3. 根据beam id , 刷新decoder中的self attention模块中的key和value的缓存
refresh_cache(cache, topk_indices)
可以发现 , 为了挑选概率 top-k 的 token, 必须在 [batch_size, beam_size, vocab_size]大小的 logit 矩阵上进行 softmax 计算及显存读写 , 然后进行 batch_size 次排序 。 通常 vocab_size 都是在几万规模 , 因此计算量非常庞大 , 而且这仅仅只是一步解码的计算消耗 。 因此实践中也可以发现 , 解码模块在自回归序列生成任务中 , 累计延迟占比很高(超过 30%) 。
LightSeq 的创新点在于结合 GPU 计算特性 , 借鉴搜索推荐中常用的粗选-精排的两段式策略 , 将解码计算改写成层级式 , 设计了一个 logit 粗选核函数 , 成功避免了 softmax 的计算及对十几万元素的排序 。 该粗选核函数遍历 logit 矩阵两次:
? 第一次遍历 , 对每个 beam , 将其 logit 值随机分成k组 , 每组求最大值 , 然后对这k个最大值求一个最小值 , 作为一个近似的top-k值(一定小于等于真实top-k值) , 记为R-top-k 。 在遍历过程中 , 同时可以计算该beam中logit的log_sum_exp值 。
? 第二次遍历 , 对每个 beam , 找出所有大于等于 R-top-k 的 logit 值 , 将(logit - log_sum_exp + batch_id * offset, beam_id * vocab_size + vocab_id)写入候选队列 , 其中 offset 是 logit 的下界 。
在第一次遍历中 , logit 值通常服从正态分布 , 因此算出的R-top-k值非常接近真实top-k值 。 同时因为这一步只涉及到寄存器的读写 , 且算法复杂度低 , 因此可以快速执行完成(十几个指令周期) 。 实际观察发现 , 在top-4设置下 , 根据R-top-k只会从几万token中粗选出十几个候选 , 因此非常高效 。 第二次遍历中 , 根据R-top-k粗选出候选 , 同时对 logit 值按 batch_id 做了值偏移 , 多线程并发写入显存中的候选队列 。
粗选完成后 , 在候选队列中进行一次排序 , 就能得到整个batch中每个序列的准确top-k值 , 然后更新缓存 , 一步解码过程就快速执行完成了 。
下面是k=2 , 词表大小=8的情况下一个具体的示例(列代表第几个字符输出 , 行代表每个位置的候选) 。 可以看出 , 原来需要对 16 个元素进行排序 , 而采用层级解码之后 , 最后只需要对 5 个元素排序即可 , 大大降低了排序的复杂度 。 文章插图
文章插图
可视化分析计算延迟
为了验证上面几种优化技术的实际效果 , 笔者用 GPU profile 工具 , 对 LightSeq 的一次推理过程进行了延迟分析 。 下图展示了 32 位浮点数和 16 位浮点数精度下 , 各计算模块的延迟占比: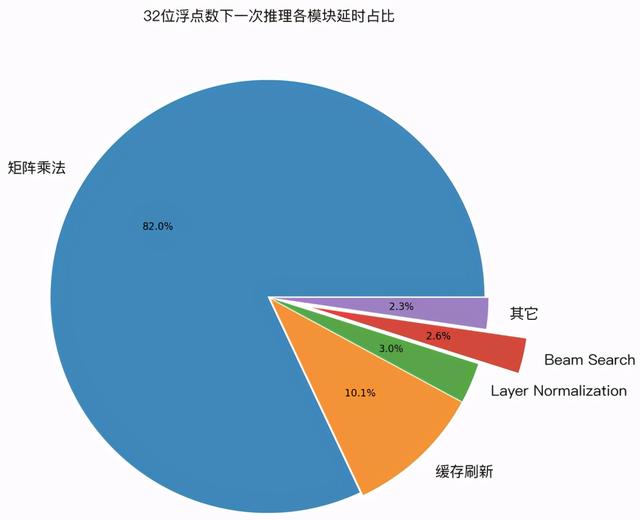 文章插图
文章插图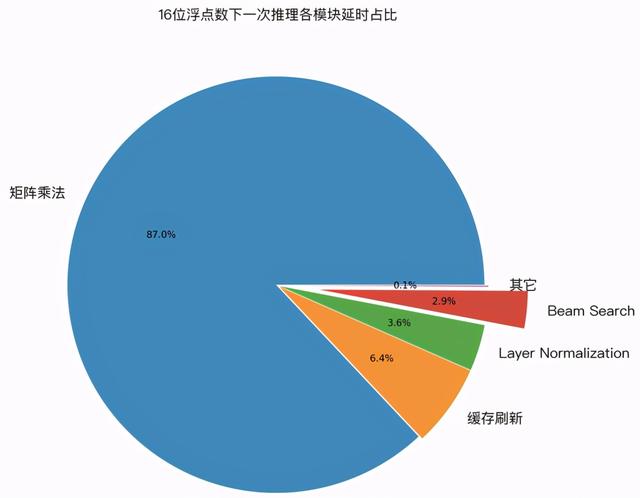 文章插图
文章插图
可以发现 , 在两种计算精度下:
1. 经过优化后 , cuBLAS 中的矩阵乘法计算延迟分别占比 82% 和 88%, 成为推理加速新的主要瓶颈 。 而作为对比 , 我们测试了 Tensorflow 模型 , 矩阵乘法计算延迟只占了 25%。 这说明 LightSeq 的 beam search 优化已经将延迟降到了非常低的水平 。
- 速度|华为P50Pro或采用很吓人的拍照技术:液体镜头让对焦速度更快
- 硬盘|七八年前的电脑,运行速度缓慢,卡顿,更换两个硬件就能快如闪电
- 加急|古代8百里加急究竟有多快?需要骑马20个小时,速度媲美顺丰快递!
- 公园|长沙五一广场、烈士公园…湖南5G速度最快的地方是?
- 首创|网易有道词典笔3发布:首创毫秒级超快点查、识别率超98%
- P50|全新液体镜头专利:华为P50系列首发人眼级对焦速度
- 5G|5G速度到底有多快?用过这些手机你才知道
- 对焦速度|Mate40Pro之后,华为还有“硬菜”,或将再次领先行业?
- 跳动|收购支付牌照,字节跳动储备新域名,官方称为防恶意侵权
- 快点|有道词典笔3上市,推出超快点查、互动点读两项新功能