速度超快!字节跳动开源序列推理引擎LightSeq( 二 )
最后在 WMT14 标准的法英翻译任务上 , 笔者测试了 Transformer big 模型的性能 。 LightSeq 在 Tesla P4 显卡上平均每句翻译延迟为 167ms, Tesla T4 上减小到了 82ms 。 而作为对比 ,TensorFlow 延迟均为 1071ms , LightSeq 分别达到了 6.41 和 13.06 倍加速 。 另外 , 笔者尝试了其他多种模型配置 , 得到了比较一致的加速效率 。 例如更深层的模型结构上(encoder加深至 16 层) , LightSeq 得到的加速比 , 分别是 6.97 和 13.85 倍 。
文本生成性能
上述机器翻译通常采用 Beam Search 方法来解码 ,而在文本生成场景 , 经常需要使用采样( Sampling )来提升生成结果的多样性 。 下图展示了 Transformer base 模型采用 top-k/top-p sampling 的性能测试对比: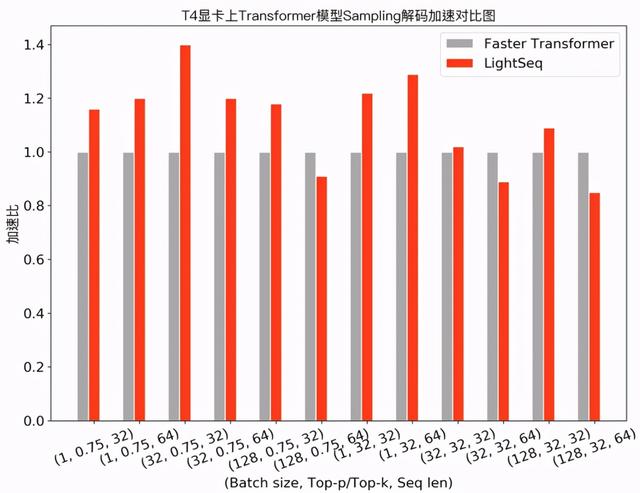 文章插图
文章插图
可以发现 , 在需要使用采样解码的任务中 , LightSeq 在大部分配置下领先于 Faster Transformer , 最多也能达到 1.4 倍的额外加速 。 此外 , 相比于 TensorFlow 实现 , LightSeq 对 GPT 和 VAE 等生成模型也达到了 5 倍以上的加速效果 。
服务压力测试
在云服务上 , 笔者测试了在实际应用中 GPT 场景下 , 模型服务从 Tensorflow 切换到LightSeq 的延迟变化情况(服务显卡使用 NVIDIA Tesla P4) 。 可以观察到 , pct99 延迟降低了 3 到 5 倍 , 峰值从 360 毫秒左右下降到 80 毫秒左右 , 详细结果如下图所示: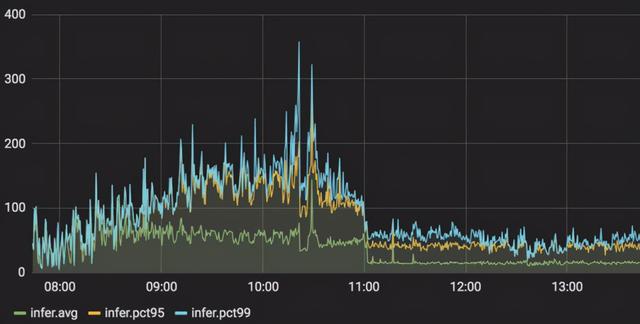 文章插图
文章插图
更多的对比实验结果可以在 LightSeq 性能评测报告 [10] 中查看到 。
技术原理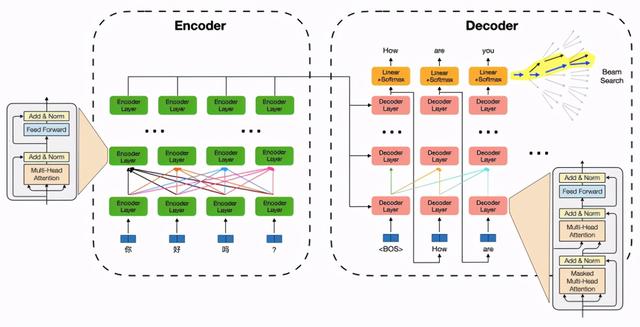 文章插图
文章插图
以 Transformer 为例 , 一个机器翻译/文本生成模型推理过程包括两部分:序列编码模块特征计算和自回归的解码算法 。 其中特征计算部分以自注意力机制及特征变换为核心(矩阵乘法 , 计算密集型) , 并伴随大量 Elementwise(如 Reshape)和 Reduce(如Layer Normalization)等 IO 密集型运算;解码算法部分包含了词表 Softmax、beam 筛选、缓存刷新等过程 , 运算琐碎 , 并引入了更复杂的动态 shape 。 这为模型推理带来了众多挑战:
1. IO 密集型计算的细粒度核函数调用带来大量冗余显存读写 , 成为特征计算性能瓶颈 。
2. 复杂动态 shape 为计算图优化带来挑战 , 导致模型推理期间大量显存动态申请 , 耗时较高 。
3. 解码生成每一步字符过程逻辑复杂 , 难以并行化计算从而发挥硬件优势 。
LightSeq 取得这么好的推理加速效果 , 对这些挑战做了哪些针对性的优化呢?笔者分析发现 , 核心技术包括这几项:融合了多个运算操作来减少 IO 开销、复用显存来避免动态申请、解码算法进行层级式改写来提升推理速度 。 下面详细介绍下各部分的优化挑战和 LightSeq 的解决方法 。
算子多运算融合
近年来 , 由于其高效的特征提取能力 , Transformer encoder/decoder 结构被广泛应用于各种 NLP 任务中 , 例如海量无标注文本的预训练 。 而多数深度学习框架(例如 Tensorflow、Pytorch 等)通常都是调用基础运算库中的核函数(kernel function)来实现 encoder/decoder 计算过程 。 这些核函数往往粒度较细 , 通常一个组件需要调用多个核函数来实现 。
以层归一化(Layer Normalization)为例 , Tensorflow 是这样实现的:
mean = tf.reduce_mean(x, axis=[-1], keepdims=True)variance = tf.reduce_mean(tf.square(x - mean), axis=[-1], keepdims=True)result = (x - mean) * tf.rsqrt(variance + epsilon) * scale + bias
可以发现 , 即使基于编译优化技术(自动融合广播(Broadcast)操作和按元素(Elementwise)运算) , 也依然需要进行三次核函数调用(两次 reduce_mean , 一次计算最终结果)和两次中间结果的显存读写(mean 和 variance) 。 而基于 CUDA , 我们可以定制化一个层归一化专用的核函数 , 将两次中间结果的写入寄存器 。 从而实现一次核函数调用 , 同时没有中间结果显存读写 , 因此大大节省了计算开销 。 有兴趣的同学可以在文末参考链接中进一步查看具体实现[11] 。
基于这个思路 , LightSeq 利用 CUDA 矩阵运算库 cuBLAS[12]提供的矩阵乘法和自定义核函数实现了 Transformer , 具体结构如下图所示: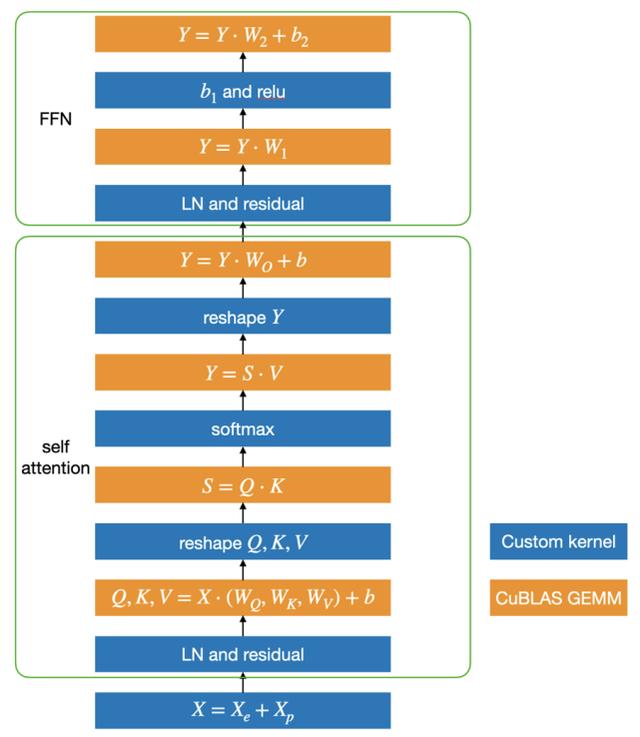 文章插图
文章插图
蓝色部分是自定义核函数 , 黄色部分是矩阵乘法 。 可以发现 , 矩阵乘法之间的运算全部都用一个定制化核函数实现了 , 因此大大减少了核函数调用和显存读写 , 最终提升了运算速度 。
- 速度|华为P50Pro或采用很吓人的拍照技术:液体镜头让对焦速度更快
- 硬盘|七八年前的电脑,运行速度缓慢,卡顿,更换两个硬件就能快如闪电
- 加急|古代8百里加急究竟有多快?需要骑马20个小时,速度媲美顺丰快递!
- 公园|长沙五一广场、烈士公园…湖南5G速度最快的地方是?
- 首创|网易有道词典笔3发布:首创毫秒级超快点查、识别率超98%
- P50|全新液体镜头专利:华为P50系列首发人眼级对焦速度
- 5G|5G速度到底有多快?用过这些手机你才知道
- 对焦速度|Mate40Pro之后,华为还有“硬菜”,或将再次领先行业?
- 跳动|收购支付牌照,字节跳动储备新域名,官方称为防恶意侵权
- 快点|有道词典笔3上市,推出超快点查、互动点读两项新功能