速度超快!字节跳动开源序列推理引擎LightSeq
机器之心发布
机器之心编辑部
这应该是业界第一款完整支持 Transformer、GPT 等多种模型高速推理的开源引擎 。
2017 年 Google 提出了 Transformer [1] 模型 , 之后在它基础上诞生了许多优秀的预训练语言模型和机器翻译模型 , 如 BERT [2] 、GPT 系列[13]等 , 不断刷新着众多自然语言处理任务的能力水平 。 与此同时 , 这些模型的参数量也在呈现近乎指数增长(如下图所示) 。 例如最近引发热烈讨论的 GPT-3 [3] , 拥有 1750 亿参数 , 再次刷新了参数量的记录 。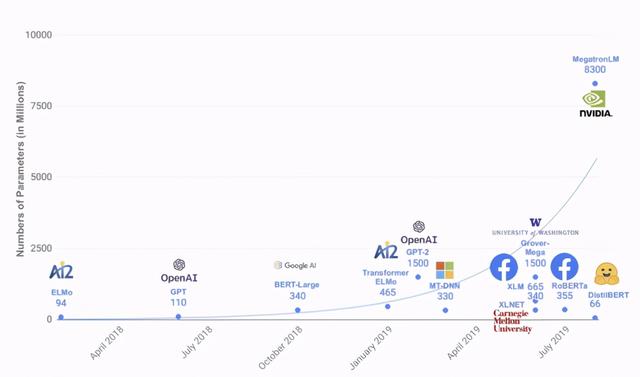 文章插图
文章插图
如此巨大的参数量 , 也为模型推理部署带来了挑战 。 以机器翻译为例 , 目前 WMT[4]比赛中 SOTA 模型已经达到了 50 层以上 。 主流深度学习框架下 , 翻译一句话需要好几秒 。 这带来了两个问题:一是翻译时间太长 , 影响产品用户体验;二是单卡 QPS (每秒查询率)太低 , 导致服务成本过高 。
因此 , 今天给大家安利一款速度非常快 , 同时支持非常多特性的高性能序列推理引擎——LightSeq 。 它对以 Transformer 为基础的序列特征提取器(Encoder)和自回归的序列解码器(Decoder)做了深度优化 , 早在 2019 年 12 月就已经开源 , 应用在了包括火山翻译等众多业务和场景 。 据了解 , 这应该是业界第一款完整支持 Transformer、GPT 等多种模型高速推理的开源引擎 。
LightSeq 可以应用于机器翻译、自动问答、智能写作、对话回复生成等众多文本生成场景 , 大大提高线上模型推理速度 , 改善用户的使用体验 , 降低企业的运营服务成本 。
相比于目前其他开源序列推理引擎 , LightSeq具有如下几点优势:
1. 高性能
LightSeq推理速度非常快 。 例如在翻译任务上 , LightSeq相比于Tensorflow实现最多可以达到14倍的加速 。 同时领先目前其他开源序列推理引擎 , 例如最多可比Faster Transformer快1.4倍 。
2. 支持模型功能多
LightSeq支持BERT、GPT、Transformer、VAE 等众多模型 , 同时支持beam search、diverse beam search[5]、sampling等多种解码方式 。 下表详细列举了Faster Transformer[7]、Turbo Transformers[6]和LightSeq三种推理引擎在文本生成场景的功能差异: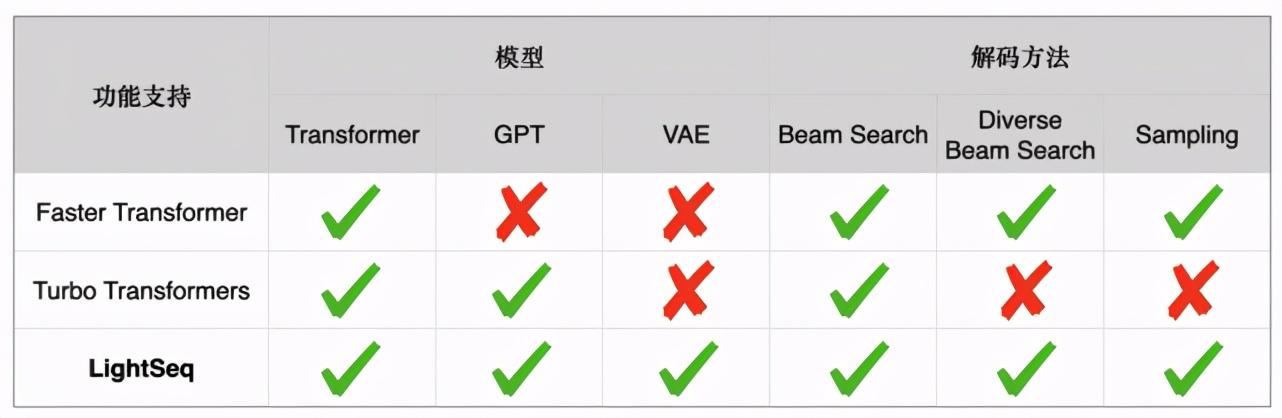 文章插图
文章插图
3. 简单易用 , 无缝衔接Tensorflow、PyTorch等深度学习框架
LightSeq通过定义模型协议 , 支持各种深度学习框架训练好的模型灵活导入 。 同时包含了开箱即用的端到端模型服务 , 即在不需要写一行代码的情况下部署高速模型推理 , 同时也灵活支持多层次复用 。
使用方法
利用 LightSeq 部署线上服务比较简便 。 LightSeq 支持了 Triton Inference Server[8] , 这是 Nvidia 开源的一款 GPU 推理 server, 包含众多实用的服务中间件 。 LightSeq 支持了该 server 的自定义推理引擎 API。 因此只要将训练好的模型导出到 LightSeq 定义的模型协议[9]中 , 就可以在不写代码的情况下 , 一键启动端到端的高效模型服务 。 更改模型配置(例如层数和 embedding 大小)都可以方便支持 。 具体过程如下:
首先准备好模型仓库 , 下面是目录结构示例 , 其中 transformer.pb 是按模型协议导出的模型权重 , libtransformer.so 是 LightSeq 的编译产物 。
- model_zoo/- model_repo/- config.pbtxt- transformer.pb- 1/- libtransformer.so
然后就可以启动Triton Inference Server[8] , 搭建起模型服务 。
1. trtserver --model-store=${model_zoo}
性能测试
在 NVIDIA Tesla P4 和 NVIDIA Tesla T4 显卡上 , 笔者测试了 LightSeq 的性能 , 选择了深度学习框架 Tensorflow v1.13 和解码场景支持较为丰富的 Faster Transformer v2.1 实现作为对比 。 Turbo Transformers 解码方法比较单一(只支持 Beam Search, 不支持文本生成中常用的采样解码) , 尚未满足实际应用需求 , 因此未作对比 。
机器翻译性能
在机器翻译场景下 , 笔者测试了 Transformer base 模型(6层 encoder、6层 decoder 、隐层维度 512 )采用 beam search 解码的性能 , 实验结果如下: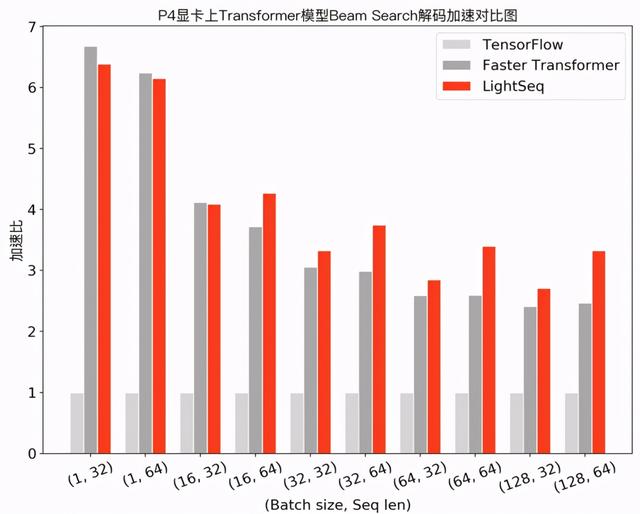 文章插图
文章插图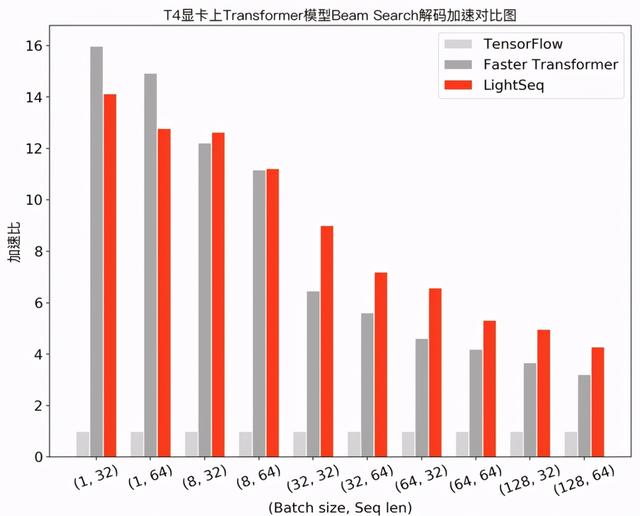 文章插图
文章插图
可以发现 , 在小 batch 场景下 , Faster Transformer 和 LightSeq 对比 Tensorflow 都达到了 10 倍左右的加速 。 而随着 batch 的增大 , 由于矩阵乘法运算占比越来越高 , 两者对 Tensorflow 的加速比都呈衰减趋势 。 LightSeq 衰减相对平缓 , 特别是在大 batch 场景下更加具有优势 , 最多能比 Faster Transformer 快 1.4 倍 。 这也对未来的一些推理优化工作提供了指导:小 batch 场景下 , 只要做好非计算密集型算子融合 , 就可以取得很高的加速收益;而大 batch 场景下则需要继续优化计算密集型算子 , 例如矩阵乘法等 。
- 速度|华为P50Pro或采用很吓人的拍照技术:液体镜头让对焦速度更快
- 硬盘|七八年前的电脑,运行速度缓慢,卡顿,更换两个硬件就能快如闪电
- 加急|古代8百里加急究竟有多快?需要骑马20个小时,速度媲美顺丰快递!
- 公园|长沙五一广场、烈士公园…湖南5G速度最快的地方是?
- 首创|网易有道词典笔3发布:首创毫秒级超快点查、识别率超98%
- P50|全新液体镜头专利:华为P50系列首发人眼级对焦速度
- 5G|5G速度到底有多快?用过这些手机你才知道
- 对焦速度|Mate40Pro之后,华为还有“硬菜”,或将再次领先行业?
- 跳动|收购支付牌照,字节跳动储备新域名,官方称为防恶意侵权
- 快点|有道词典笔3上市,推出超快点查、互动点读两项新功能