Java+Redis+ES+Kibana对百万用户数据分析( 三 )
而使用布隆算法 , 需要的空间:n * 1670000 bit, 使用的hash方法一般是3-10个左右 , 即一般至多只需要15.9KB左右的空间(我在项目中使用的是2 << 24 bit即16KB的容量) 。 如果数据量继续增大 , 布隆算法的优势会越来越大 。
算法的缺点: 地 , 这种hash映射存储的方式肯定会有误判的情况 。 即bitSet容器中明明没有存储该数据 , 却认为之前已经存储过该数据 。 但是只要hash方法的个数以及其实现设计得合理 , 那么这个误判率能够大大降低(笔者水平有限 , 具体怎么降低并计算误判率可自行谷歌或百度) 。 而且基于大数据分析来说 , 一定数据的缺失是可以允许的 , 只要保证过滤后有足够的不重复的数据进行分析就行 。
项目中屏蔽了布隆算法实现的复杂性 , 直接调用接口localhost:8980/users/filter , 即可将DB中的用户数据进行去重 。
【Java+Redis+ES+Kibana对百万用户数据分析】过滤之后 , 还有160万左右不重复的数据 , 说明布隆算法误判率导致的数据流失 , 对大量的数据来说影响是可以接受的 。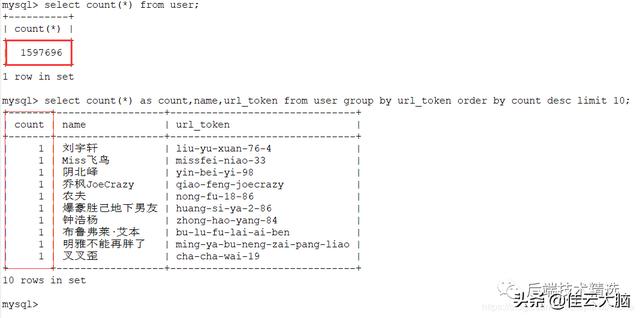 文章插图
文章插图
4.2 数据导入ElasticSearchmysql是一个用来持久化数据的工具 , 直接用来进行数据分析明显效果不太好(而且数据量较大时 , 查询效率极低) , 这里就需要使用更加合适的工具—ElasticSearch 。 简单学习一下ElasticSearch , 可以参考elasticsearch官网 。
配置好ElasticSearch环境 , 然后修改配置文件中ElasticSearch相关的配置 。 调用接口localhost:8980/users/transfer , 即可将DB中的用户数据迁移到ES中 。
SpringBoot整合ElasticSearch非常简单 , 直接在项目中导入ElasticSearch的自动配置依赖包
数据导入ES后 , 可以在head插件或者kibana插件中查看ES中的数据(head插件或kibana插件可以看去重之后导入ES中的数据有1597696条) 。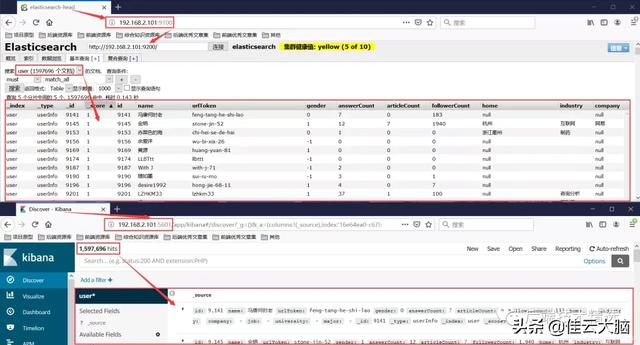 文章插图
文章插图
4.3 kibana分析知乎数据我们已经拿到足够多的用户数据了 , 现在需要利用kibana插件来分析数据 。 我们在Management > Kibana > Index Patterns中将创建关联的索引user后 , 即可使用kibana插件辅助我们来分析数据 。
搜索Java知音公众号 , 回复“后端面试” , 送你一份Java面试题宝典
下面举几个例子来表示如何使用Kibana来分析大数据 。
- 查询关注数在100万及以上的用户
# 查询关注数在100万及以上的用户GET user/userInfo/_search{"query": {"range" : {"followerCount" : {"gte": 1000000}}}}查询结果图如下: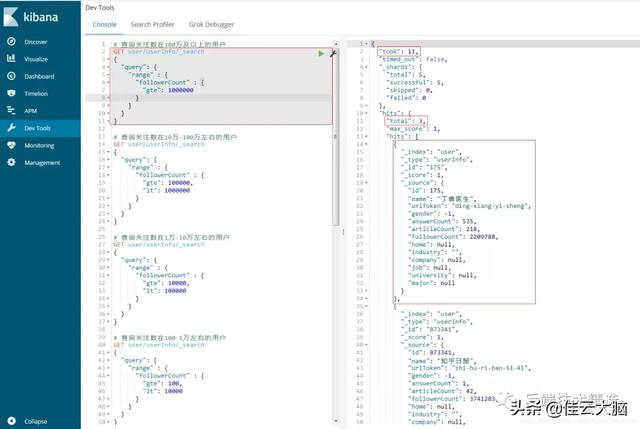 文章插图
文章插图简单地解释一下结果集中部分字段的意义 。 took是指本次查询的耗时 , 单位是毫秒 。 hits.total表示的是符合条件的结果条数 。 hits._score表示的是与查询条件的相关度得分情况 , 默认降序排序 。
- 聚合查询知乎用户的性别比
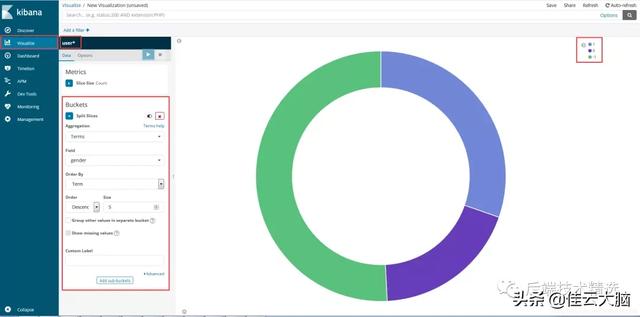
# 查询知乎用户男女性别比GET /user/userInfo/_search{"size": 0,"aggs": {"messages": {"terms": {"field": "gender"}}}}查询结果图如下: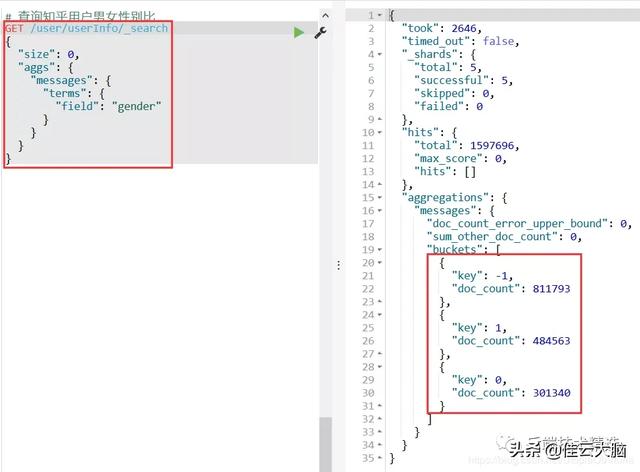 文章插图
文章插图直接看数据可能不太直观 , 我们还可以直接通过kibana插件不画相应的结果图(-1:未填 , 1:男 ,0:女):
 文章插图
文章插图从结果图来看 , 目前知乎的男女比还不算离谱 , 比例接近3:2(这里让我有点儿怀疑自己爬取的数据有问题) 。
- 聚合查询人口最集中的前10个城市
# 查询现居地最多的前10个城市GET /user/userInfo/_search{"size": 0,"aggs": {"messages": {"terms": {"field": "home","size": 10}}}}查询结果图如下: 文章插图
文章插图从这里的查询结果 , 很容易就可以看出 , “深圳”和“深圳市”、“广州”和“广州市”其实各自指的都是同一地方 。 但是当前ES不能智能地识别并归类(ps: 可能有方法可以归类但笔者不会…) 。 因此这里需要后续手动地将类似信息进行处理归类 。
- 纠结|硬杠红米Note9Pro?iQOO Z1跌至1575,对比之后纠结了!
- 对手|一加9Pro全面曝光,或是小米11最大对手
- 作家|逾万名作家联名反对亚马逊有声书轻松退换政策
- 芯片|华米GTS2mini和红米手表哪个好 参数功能配置对比
- 速度|华为P50Pro或采用很吓人的拍照技术:液体镜头让对焦速度更快
- 时尚先生|小米雷军成2020年最出圈企业家:获时尚双刊年度人物
- 电信|巴西电信协会及运营商发文 反对限制华为5G
- 化妆产品|直播带货年入百万,这8个行业告诉你:是真的
- 华为|骁龙870和骁龙855区别都是7nm芯片吗 性能对比评测
- 区企联企协|谋求更高质量的转型发展!区企联企协与区科技局成功举办科技考察对接活动