Java+Redis+ES+Kibana对百万用户数据分析
作者:_artoria_
1. 前言我是一个真正的知乎小白 。
上班的时候 , 自己手头的事情处理完了 , 我除了在掘金摸鱼 , 就是在知乎逛贴 。 在我的认知中 , 知乎是一个高质量论坛 , 基本上各种“疑难杂症”都能在上面找到相应的专业性回答 。 但平时逗留在知乎的时间过多 , 我不知道自己是被知乎上面的精彩故事所吸引 , 还是为知乎上面的高深技术而着迷 。
咱是理科生 , 不太懂过于高深的哲学 , 自然不会深层次地剖析自己 , 只能用数据来说话 。 于是 , 就有了这篇博客 。
相关的项目源码放在:
2. 博客结构图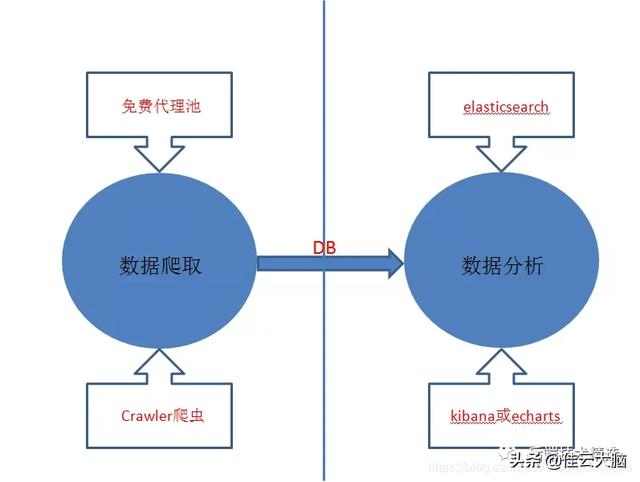 文章插图
文章插图
博客的结构图如上所示 。 这篇博客主要讲述两件事:爬取知乎用户数据和对用户数据进行分析 。 这个结构图基本能够概述分析知乎用户信息的思路 , 具体的思路详述和技术实现细节可看博客后面的内容 。
3. 爬取知乎用户数据3.1 知乎用户页面解析我的知乎主页信息预览如下: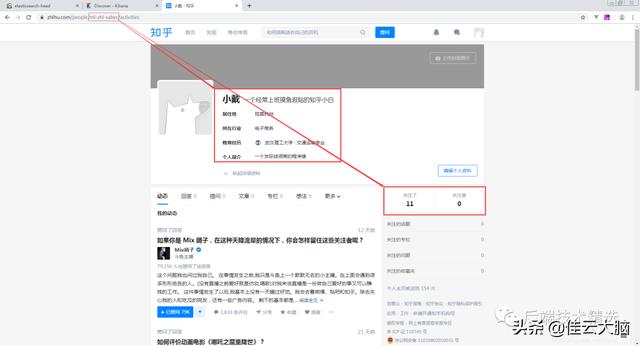 文章插图
文章插图
从该页面的内容来看 , 我当前需要爬取的知乎信息就在两个红框中 。 然后每个知乎用户主页对应的URL路径应该不一样 , 这里URL中标识是我的主页就是mi-zhi-saber , 这个URL标识就是知乎里面的url_token 。 也就是说拿到足够多的url_token , 就可以自己组装URL来获取用户的信息 。
通过分析知乎页面结构 , 我们可以按照如下思路来爬取用户信息:
- 基于用户的个人主页信息 , 爬取、解析并保存用户信息 。
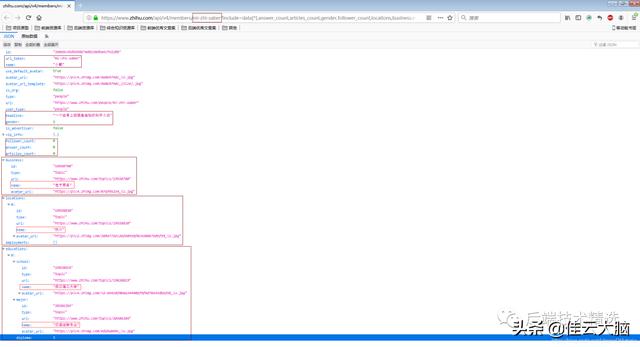 文章插图
文章插图对比这两个页面 , 可以推断出里面部分字段的意义(其实字段名称已经足够见名知意了) 。 综合考虑后 , 我要爬取的字段及其意义如下
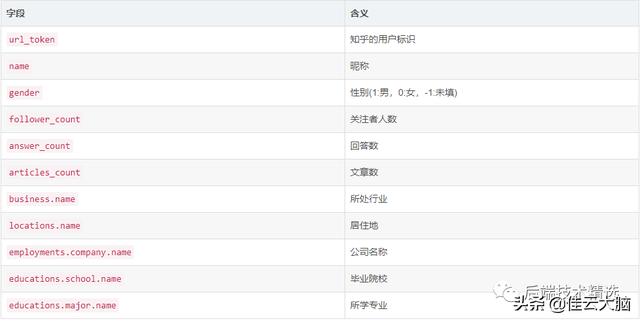 文章插图
文章插图- 基于用户关注的知乎用户信息 , 爬取、解析并保存用户信息 。
 文章插图
文章插图- 基于关注用户的知乎用户信息 , 爬取、解析并保存用户信息 。
 文章插图
文章插图理论上 , 选取一个知乎大V作为根节点 , 迭代爬取关注者和被关注者的信息 , 可以拿到绝大部分的知乎用户信息 。
3.2 选取爬虫框架要想对知乎用户进行画像 , 必须拿到足够多的知乎用户数据 。 简单来说 , 就是说要用java爬虫爬取足够多的知乎用户数据 。
工欲善其事 , 必先利其器 。 常见的Java爬虫框架有很多如:webmagic,crawler4j,SeimiCrawler,jsoup等等 。 这里选用的是SpringBoot + SeimiCrawler , 这个方式可以几乎零配置地使用爬虫爬取知乎用户数据 。 具体如何使用可见于SeimiCrawler官方文档 , 或者参考我的源码 。
搜索Java知音公众号 , 回复“后端面试” , 送你一份Java面试题宝典
3.3 使用反反爬手段论坛是靠内容存活的 。 如果有另外一个盗版论坛大量地爬取知乎内容 , 然后拷贝到自己的论坛上 , 知乎肯定会流失大量用户 。 不用想就知道 , 知乎肯定是采取了一些反爬手段的 。
最常见的反爬手段就是User Agent识别和IP限流 。 简单解释一下 , 就是知乎会基于用户访问记录日志 , 分析哪个用户(IP)用哪个浏览器(UA)访问知乎网站的 , 如果某个用户极其频繁地访问知乎网站 , 知乎就会把该用户标记为“疑似爬虫的机器人” , 然后让该用户进行登录验证或直接将该用户对应的IP地址进行封禁 。
然后 , 所谓的“反反爬手段” , 就是应对上面所说的反爬手段的 。 我采取的“反反爬手段”是:
- 收集一些常用的UA , 然后每次调用接口访问知乎网站的时候会刷新所使用的UA 。
- 自己在项目中维护一个可高用的免费代理池 , 每次调用接口访问知乎网站的时候会使用高可用代理池的随机一个代理 。
- 纠结|硬杠红米Note9Pro?iQOO Z1跌至1575,对比之后纠结了!
- 对手|一加9Pro全面曝光,或是小米11最大对手
- 作家|逾万名作家联名反对亚马逊有声书轻松退换政策
- 芯片|华米GTS2mini和红米手表哪个好 参数功能配置对比
- 速度|华为P50Pro或采用很吓人的拍照技术:液体镜头让对焦速度更快
- 时尚先生|小米雷军成2020年最出圈企业家:获时尚双刊年度人物
- 电信|巴西电信协会及运营商发文 反对限制华为5G
- 化妆产品|直播带货年入百万,这8个行业告诉你:是真的
- 华为|骁龙870和骁龙855区别都是7nm芯片吗 性能对比评测
- 区企联企协|谋求更高质量的转型发展!区企联企协与区科技局成功举办科技考察对接活动