DPDK性能优化技术汇总以及学习路线( 三 )
__sync_fetch_and_add(type* ptr, type value)__sync_compare_and_swap(type *ptr, type oldval,type newval)etc...这些操作虽然表面上没有了锁的痕迹 , 但实际上其汇编指令还是存在一个#lock锁总线的操作 。 所以也不必对其性能抱太高期望 。 对于所有关于锁的操作 , 需要强调的是 , 锁本身并不影响性能 , 只有对锁的争抢才影响性能 。
Local Cache如同之前介绍的那样 , 还有一种策略是将任务尽量划分为不相互依赖的各部分 , 分别交给不同的CPU Core去处理 , 仅仅在结果汇总的时候有少量的锁操作 。 在DPDK中大量应用了这种思想 。
Core Affinity将一个任务指定交给某个CPU Core处理 , 可以减少上下文切换和context switch的次数 , 以及提高缓存命中率 。 在Linux程序中可以通过
int sched_setaffinity(pid_tpid, size_t cpusetsize, const cpu_set_t *mask);来设定线程的CPU亲和性 。
False SharingFalse Sharing也是在多线程操作中需要避免的缓存失效的问题 。 如果两个变量分别被两个线程操作 , 但它们出现在同一条Cache Line中 , 则两个线程之间还是会互相影响 。 任何一个线程对该Cache Line的写操作 , 都会失整条Cache Line在另外一个线程处失效 。 如下图: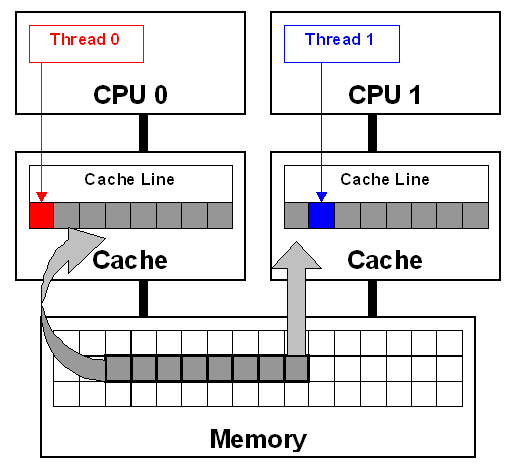 文章插图
文章插图
对此最简单的办法 , 是可以添加Cache Padding将两个变量分隔在不同的Cache Line之中 , 或者以Cache Line Size对齐的方式分配内存 。
作者:程序员小灰
出处:
- 巅峰|realme巅峰之作:120Hz+陶瓷机身+5000mAh 做到了颜值与性能并存
- 优化|微软亚洲研究院发布开源平台“群策 MARO” 用于多智能体资源调度优化
- 华为|骁龙870和骁龙855区别都是7nm芯片吗 性能对比评测
- 器件|苏州纳米所等在高性能柔性储能器件研究中取得进展
- 超强|RedmiNote9系列发布!天玑800U赋予超强5G性能
- iPhoneX|iPhone12和iPhoneX性能对决:差距比想象的大太多
- 人工智能|人工智能只会“优化”,而人类可以“进化”
- Redmi|Redmi Note 9系列发布,搭载天玑800U具备超强5G性能
- 首发|华为或首发联发科6纳米+A78新U:性能超强不输麒麟9000
- 华为|安兔兔10月安卓性能榜:华为Mate40 Pro第一 麒麟9000碾压骁龙865