DPDK性能优化技术汇总以及学习路线( 二 )
_attaribute_(section(X))将函数显式地置于Read only(program memory)Section X , 方便一起调用 。 同时也可以map文件的形式安排指定 。
Note: 同样的原则也适用于变量 。
CPUAdvanced Instruction Set使用先进的CPU指令集 , 带来的主要好处是可以并行完成向量化的操作 , 也就是所谓的SIMD(Single-Instruction-Multiple-Data)操作 。
当需要对大型数据集执行相同的操作的时候 , 向量操作可以带来明显的性能提升 。 例如图像处理、大型矩阵计算、网络数据包还有内存复制操作等 。
Note: 对于数据间有互相依赖和操作上有继承的运算 , 比如排序 , 并不适合向量操作 。
先进的指令集一般包括 SSE SSE2 AVX AVX512 YMM ZMM。 这些指令集对数据储存的地址都有比较严格的要求 , 比如 256bit-YMM 要求数据按32对齐 ,512-bit ZMM 要求数据按64对齐 。
对于向量操作 , 一般希望符合如下条件:
- 小型的数据类型: char short int float
- 对大型数据集执行类似的操作
- 数据对齐
- 数据集长度可以被向量长度整除
CompilerBranch Predication
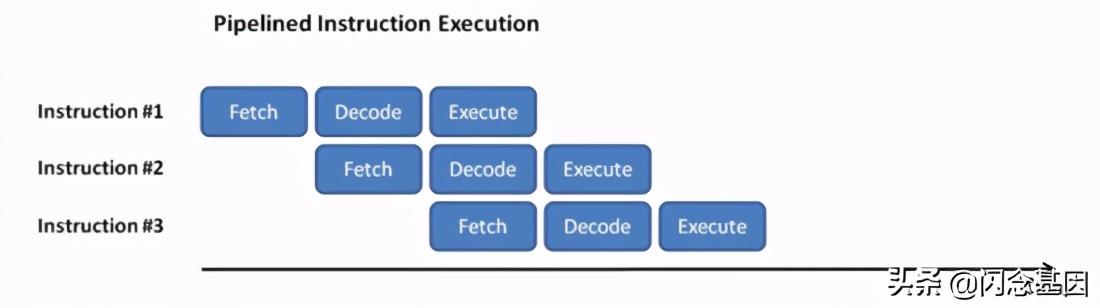 文章插图
文章插图CPU是以流水线的方式执行程序指令 。 所谓流水线 , 可以简单理解为在执行一个指令的同时 , 读取下一条指令 。 对于程序中大量出现的 if else while for ? : 等含有条件判断的情景 , CPU需要能够正确提取下一条指令以便流水线可以流畅执行下去 。 一旦提取的是错误分支的指令 , 虽然不影响程序运行的结果 , 但整条流水线都会被清空 , 再重新读入正确分支的指令 , 对程序运行效率影响颇大 。
CPU一般都有硬件分支预测器 , 但我们也可以用 likely()/unlikely() 等方式显示指定 , 另外在设计程序的时候也以使分支判断具有一定的规律性为好 , 比如一组经过排序的输入数据 。
Branchless Code为了最大限度减小Branch mispredication对性能带来的影响 , 可以将一些常见的分支判断转换为Branchless的形式 。 比如返回两个数中较大的值 , 一般可以写做:
int max = (x > y) ? x : y;【DPDK性能优化技术汇总以及学习路线】这里其实隐含了一个条件判断 。 如果用branchless的形式 , 同样的功能可以写做为:int max = x ^ ((x ^ y) 当有大量调用 , 同时输入无甚规律性的时候可以考虑采用Branchless code 。 一个比较全面的技巧合计在: Click。loop-unrollingLoop-unrolling的一大好处就是可以减少循环分支预测的次数 。 对于简单的循环 , CPU其实可以很好的完成分支预测的工作 , 但对于嵌套的循环 , 或者循环内部会改变循环次数的循环 , 分支预测就变得困难 。 loop-unrolling的特点可以用如下的例子说明:
int i;for (i = 0; i < 20; i++) {if (i % 2 == 0) {FuncA(i);} else {FuncB(i);}FuncC(i);}上面这个执行了20次的循环可以用loop-unrolling展开:int i;for (i = 0; i < 20; i += 2) {FuncA(i);FuncC(i);FuncB(i + 1);FuncC(i + 1);}ifNote: Loop-unrolling也需要考虑适用场合 。 主要适用于循环体的分支是主要的性能热点的时候 。Anti-aliasing当有多个指针指向同一处物理内存(变量)的时候 , 称为pointer aliasing 。 作为编译器 , 并不能确认两个相同类型的指针是否指向同一处地址 , 即对其他指针的操作 , 是否会影响另外的指针所指向的内存 。 这就要求每次碰到这两个指针其中的任何一个的时候 , 都需要重新从内存中读取当前值 。 示例如下:
void Func1 (int a[], int *p) {int i;for (i = 0; i < 100; i++) {a[i] = *p + 2;}}void Func2() {int list[100];Func1(list, }在 Func1 中 , 有必要每次都重新读入 *p, 并且重新计算 *p + 2, 因为在 Func2 的调用中 , 与 list[8] 发生aliasing 。 对编译器来讲 , 它需要考虑这种“理论上的可能” , 从而付出大量的重复劳动 。当程序可以确认两个指针不会发生aliasing的时候 , 可以用关键字 __restrict__ 给编译器以明确的指示 。
Prefetch使用prefetch指令可以帮助我们提前预存一个将要使用的变量至CPU缓存:
_mm_prefetch但在实际使用过程中要特别小心 , 现代CPU都有自己的硬件prefetch机制 , 如果不是经过测试 , 确认性能有所提高 , 尽量不要轻易使用该指令 。 这里有一篇资料对此有详细解释: ClickNote:需要确认CPU支持SSE指令集
Multi-threadsLock-less一般将GCC提供的一些原子操作视为“Lock-less code” 。 这些操作包括一些原子自增 , CAS等操作 。
- 巅峰|realme巅峰之作:120Hz+陶瓷机身+5000mAh 做到了颜值与性能并存
- 优化|微软亚洲研究院发布开源平台“群策 MARO” 用于多智能体资源调度优化
- 华为|骁龙870和骁龙855区别都是7nm芯片吗 性能对比评测
- 器件|苏州纳米所等在高性能柔性储能器件研究中取得进展
- 超强|RedmiNote9系列发布!天玑800U赋予超强5G性能
- iPhoneX|iPhone12和iPhoneX性能对决:差距比想象的大太多
- 人工智能|人工智能只会“优化”,而人类可以“进化”
- Redmi|Redmi Note 9系列发布,搭载天玑800U具备超强5G性能
- 首发|华为或首发联发科6纳米+A78新U:性能超强不输麒麟9000
- 华为|安兔兔10月安卓性能榜:华为Mate40 Pro第一 麒麟9000碾压骁龙865