DPDK性能优化技术汇总以及学习路线
作者:程序员小灰
出处:
Memory AccessAddress Alignment在内存中存取一个变量最高效的方式是将其放在一个可以被它的长度整除的地址上 。
(void *) --tt-darkmode-bgcolor: #131313;">所谓的按某个长度对齐就是这个意思 。 GCC编译器会自动帮我们处理这些事情 。 比较特殊的方式是将一个大型的结构体 , 或者静态数组按64byte的方式对齐:
int BigArray[1024] __attribute__((aligned(64)));这主要是考虑到CPU的Cache Line长度多为64byte , 变量按64对齐可以使其正好开始于一个Cache Line , 减少Cache Miss/False Sharing以及利用CPU的高级指令集并行计算 。
Note: _attribute _((aligned(x)))有时只对全局变量有效 , 而对局部变量无效 。
Huge Page大页技术是当前流行的一种性能优化技术 。 在Linux系统中有一套复杂的进程虚拟地址和内存物理地址的转换机制 , 复杂的细节我们不去关心 , 只需要知道Linux是通过页(Page)这一机制(Look-up table)来确立两者的对应关系的 。 简单的类比就是在一本2000页的书中找到某一个章节 , 远比在一本2页的书中复杂 。 考虑到传统页面4KB的大小和大页2GB的小大之差 , 这个类比还不是那么恰当 。
在CPU中 , 需要以缓存的形式存储一些转换关系 , 这种缓存成为TLB Cache 。 使用大页可以减少TLB Cache Miss 。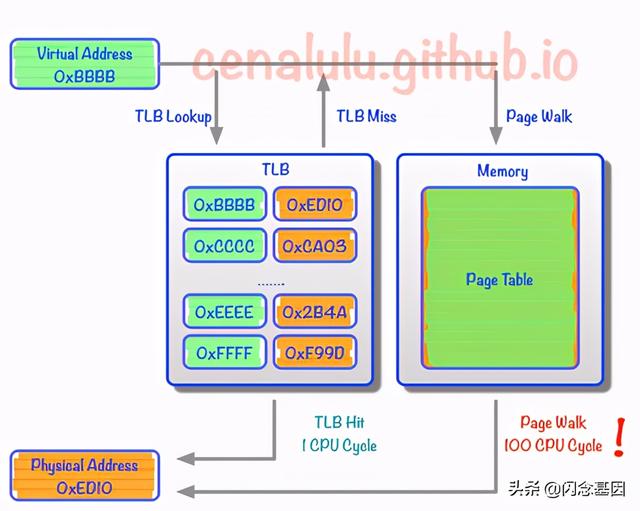 文章插图
文章插图
Virtual addr maps to physical addr
Note: Huge Page可以在绝大部分情况之下提高性能 , 但并不是所有情况下都可以起到提升性能的效果 。 对于内存 , 需要综合考虑各种因素 , 提高性能的基本策略还是以空间换时间 。 详细的分析文章请
DPDK学习路线以及视频讲解+qun832218493获取======================================================
1.dpdk PCI原理与testpmd/l3fwd/skeletion2.kni数据流程3.dpdk实现dns4.dpdk高性能网关实现5.半虚拟化virtio/vhost的加速 文章插图
文章插图
NUMA严格来说NUMA并不是一种性能优化技术 , 而是一种内存架构 。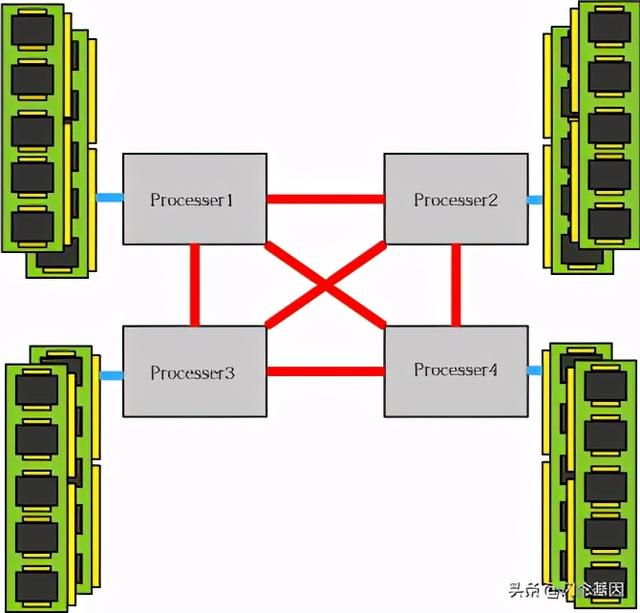 文章插图
文章插图
NUMA Architecture
每一个CPU Core都与它本地连接的内存直接相连 , 独享总线 , 具有最快的读写速度 。 如果去远程(remote)内存去读写的话 , 则需要跨CPU Core执行 。 在DPDK中 , 有一整套精巧且高效的内存分配和管理机制 , 结合大页和NUMA等机制 , 基本原则是 , 将一个CPU Core需要处理的数据都放在离它最近的内存上 。
相关的实现可以参考DPDK中 memseg memzone 等内存机制相关代码的实现 , 这里可以有专门文章介绍 。
Polling Mode Drive(PMD)是DPDK实现的优化Linux网络接收发送性能的模块 , 官方有详细的介绍资料 。Click
Memory Pool对于需要频繁填充释放的内存空间可以采用内存池的方式预先动态分配一整块内存区域 , 然后统一进行管理 , 从而省去频繁的动态分配和释放过程 , 既提高了性能 , 同时也减少了内存碎片的产生 。
内存池多以队列的形式组织空闲或占用内存 。 在DPDK中 , 还考虑了地址对齐 , 以及CPU core local cache等因素 , 以提升性能 。
这里提到的内存对齐不同于前面仅仅将变量放在一个合适的地址“数目”上 , 而是综合考虑了内存通道(channel)和rank , 将变量(比如一个三层网络的Pkt) , 平均分布于不同的channel之上(多依靠padding) , 可以减少channel拥塞 , 显著提升性能 。 如图: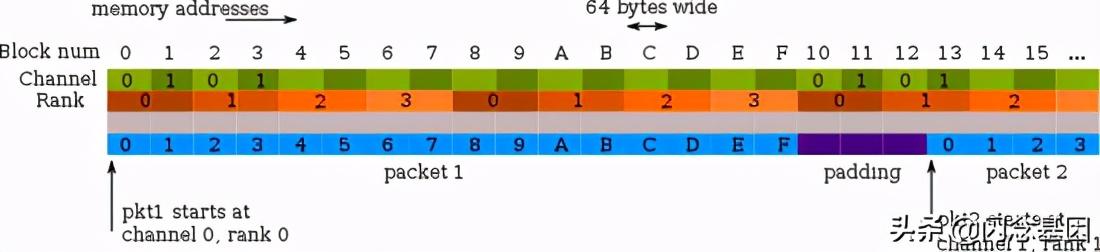 文章插图
文章插图
Two Channels and Quad-ranked DIMM Example
对于供多个线程同时使用的内存池 , 为了减少对内存池的读写冲突 , 可以考虑Local Cache的机制 。 即内存池为每一个线程/CPU Core维护一个Local Cache , 本地的CPU Core对其操作是没有竞争的 。 每个CPU Core都是以bulk的形式从内存池中请求数据写入Local Cache或者将Local Cache的数据写入内存池 。 这样便大幅减少了读写冲突 。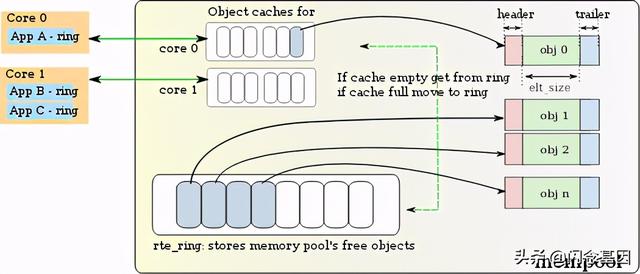 文章插图
文章插图
Local cache per core
Linker Considerations可以理解的一个简单事实是 , 如果经常使用的函数被储存在指令内存的同一区域 , 甚至存储顺序和调用顺序一致 , 那么程序整体执行的效率将会有所提升 。
一个简单的方法就是尽量使用 static 函数:
static void f(void)将同一模块中的函数在链接阶段放在一起 。 但很多时候 , 处于程序模块化编程考虑 , 模块之间互相调用的函数和方法并没有被显式地置于同一处指令内存 , 此时可以在关键函数集中采用:
- 巅峰|realme巅峰之作:120Hz+陶瓷机身+5000mAh 做到了颜值与性能并存
- 优化|微软亚洲研究院发布开源平台“群策 MARO” 用于多智能体资源调度优化
- 华为|骁龙870和骁龙855区别都是7nm芯片吗 性能对比评测
- 器件|苏州纳米所等在高性能柔性储能器件研究中取得进展
- 超强|RedmiNote9系列发布!天玑800U赋予超强5G性能
- iPhoneX|iPhone12和iPhoneX性能对决:差距比想象的大太多
- 人工智能|人工智能只会“优化”,而人类可以“进化”
- Redmi|Redmi Note 9系列发布,搭载天玑800U具备超强5G性能
- 首发|华为或首发联发科6纳米+A78新U:性能超强不输麒麟9000
- 华为|安兔兔10月安卓性能榜:华为Mate40 Pro第一 麒麟9000碾压骁龙865