Elasticsearch|MySQL用得好好的,为什么要转ES?( 三 )
当前订单系统ES采用的是默认Refresh配置 , 故对于那些订单数据实时性比较高的业务 , 直接走数据库查询 , 保证数据的准确性 。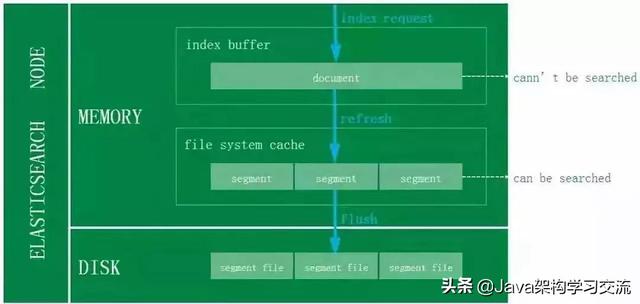 文章插图
文章插图
2、避免深分页查询
ES集群的分页查询支持from和size参数 , 查询的时候 , 每个分片必须构造一个长度为from+size的优先队列 , 然后回传到网关节点 , 网关节点再对这些优先队列进行排序找到正确的size个文档 。
假设在一个有6个主分片的索引中 , from为10000 , size为10 , 每个分片必须产生10010个结果 , 在网关节点中汇聚合并60060个结果 , 最终找到符合要求的10个文档 。
由此可见 , 当from足够大的时候 , 就算不发生OOM , 也会影响到CPU和带宽等 , 从而影响到整个集群的性能 。 所以应该避免深分页查询 , 尽量不去使用 。
3、FieldData与Doc Values
FieldData
线上查询出现偶尔超时的情况 , 通过调试查询语句 , 定位到是跟排序有关系 。 排序在es1.x版本使用的是FieldData结构 , FieldData占用的是JVM Heap内存 , JVM内存是有限 , 对于FieldData Cache会设定一个阈值 。
如果空间不足时 , 使用最久未使用(LRU)算法移除FieldData , 同时加载新的FieldData Cache , 加载的过程需要消耗系统资源 , 且耗时很大 。 所以导致这个查询的响应时间暴涨 , 甚至影响整个集群的性能 。 针对这种问题 , 解决方式是采用Doc Values 。
Doc Values
Doc Values是一种列式的数据存储结构 , 跟FieldData很类似 , 但其存储位置是在Lucene文件中 , 即不会占用JVM Heap 。 随着ES版本的迭代 , Doc Values比FieldData更加稳定 , Doc Values在2.x起为默认设置 。
总结架构的快速迭代源于业务的快速发展 , 正是由于近几年到家业务的高速发展 , 订单中心的架构也不断优化升级 。 而架构方案没有最好的 , 只有最合适的 , 相信再过几年 , 订单中心的架构又将是另一个面貌 , 但吞吐量更大 , 性能更好 , 稳定性更强 , 将是订单中心系统永远的追求 。
关注我 , 后续更多干货奉上!
- 看不上|为什么还有用户看不上华为Mate40系列来看看内行人怎么说
- 采用|消息称一加9系列将推出三款新机,新增一加9E
- 会员|美容院使用会员管理软件给顾客更好的消费体验!
- 行业|现在行业内客服托管费用是怎么算的
- 闲鱼|电诉宝:“闲鱼”网络欺诈成用户投诉热点 Q3获“不建议下单”评级
- 美国|英国媒体惊叹:165个国家采用北斗将GPS替代,连美国也不例外?
- 桌面|日常使用的软件及网站分享 篇一:几个动态壁纸软件和静态壁纸网站:助你美化你的桌面
- 同轴心配合|用SolidWorks画一个直角传动,画四个零件就行
- 先别|用了周冬雨的照片,我会成为下一个被告?自媒体创作者先别自乱阵脚
- 速度|华为P50Pro或采用很吓人的拍照技术:液体镜头让对焦速度更快