Elasticsearch|MySQL用得好好的,为什么要转ES?( 二 )
那备用集群应该怎么来搭?主备之间数据如何同步?备用集群应该存储什么样的数据?
考虑到ES集群暂时没有很好的主备方案 , 同时为了更好地控制ES数据写入 , 我们采用业务双写的方式来搭设主备集群 。 每次业务操作需要写入ES数据时 , 同步写入主集群数据 , 然后异步写入备集群数据 。 同时由于大部分ES查询的流量都来源于近几天的订单 , 且订单中心数据库数据已有一套归档机制 , 将指定天数之前已经关闭的订单转移到历史订单库 。
所以归档机制中增加删除备集群文档的逻辑 , 让新搭建的备集群存储的订单数据与订单中心线上数据库中的数据量保持一致 。 同时使用ZK在查询服务中做了流量控制开关 , 保证查询流量能够实时降级到备集群 。 在此 , 订单中心主从集群完成 , ES查询服务稳定性大大提升 。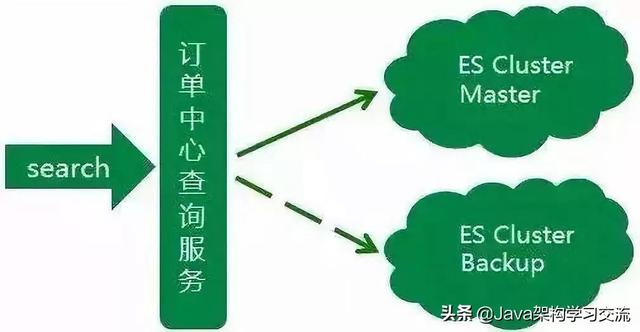 文章插图
文章插图
5、现今:实时互备双集群阶段
期间由于主集群ES版本是较低的1.7 , 而现今ES稳定版本都已经迭代到6.x , 新版本的ES不仅性能方面优化很大 , 更提供了一些新的好用的功能 , 所以我们对主集群进行了一次版本升级 , 直接从原来的1.7升级到6.x版本 。
集群升级的过程繁琐而漫长 , 不但需要保证线上业务无任何影响 , 平滑无感知升级 , 同时由于ES集群暂不支持从1.7到6.x跨越多个版本的数据迁移 , 所以需要通过重建索引的方式来升级主集群 , 具体升级过程就不在此赘述了 。
主集群升级的时候必不可免地会发生不可用的情况 , 但对于订单中心ES查询服务 , 这种情况是不允许的 。 所以在升级的阶段中 , 备集群暂时顶上充当主集群 , 来支撑所有的线上ES查询 , 保证升级过程不影响正常线上服务 。 同时针对于线上业务 , 我们对两个集群做了重新的规划定义 , 承担的线上查询流量也做了重新的划分 。
备集群存储的是线上近几天的热点数据 , 数据规模远小于主集群 , 大约是主集群文档数的十分之一 。 集群数据量小 , 在相同的集群部署规模下 , 备集群的性能要优于主集群 。
然而在线上真实场景中 , 线上大部分查询流量也来源于热点数据 , 所以用备集群来承载这些热点数据的查询 , 而备集群也慢慢演变成一个热数据集群 。 之前的主集群存储的是全量数据 , 用该集群来支撑剩余较小部分的查询流量 , 这部分查询主要是需要搜索全量订单的特殊场景查询以及订单中心系统内部查询等 , 而主集群也慢慢演变成一个冷数据集群 。
同时备集群增加一键降级到主集群的功能 , 两个集群地位同等重要 , 但都可以各自降级到另一个集群 。 双写策略也优化为:假设有AB集群 , 正常同步方式写主(A集群)异步方式写备(B集群) 。 A集群发生异常时 , 同步写B集群(主) , 异步写A集群(备) 。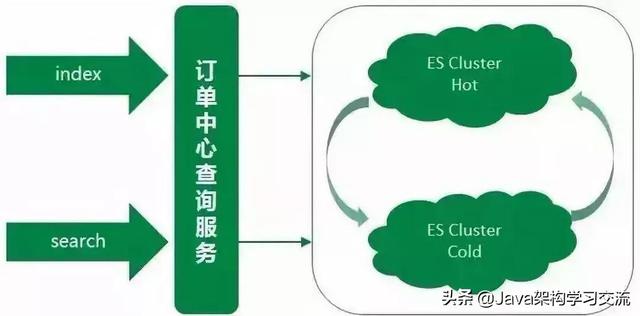 文章插图
文章插图
ES 订单数据的同步方案MySQL数据同步到ES中 , 大致总结可以分为两种方案:
- 方案1:监听MySQL的Binlog , 分析Binlog将数据同步到ES集群中 。
- 方案2:直接通过ES API将数据写入到ES集群中 。
由于ES订单数据的同步采用的是在业务中写入的方式 , 当新建或更新文档发生异常时 , 如果重试势必会影响业务正常操作的响应时间 。
所以每次业务操作只更新一次ES , 如果发生错误或者异常 , 在数据库中插入一条补救任务 , 有Worker任务会实时地扫这些数据 , 以数据库订单数据为基准来再次更新ES数据 。 通过此种补偿机制 , 来保证ES数据与数据库订单数据的最终一致性 。
遇到的一些坑1、实时性要求高的查询走DB
对于ES写入机制的有了解的同学可能会知道 , 新增的文档会被收集到Indexing Buffer , 然后写入到文件系统缓存中 , 到了文件系统缓存中就可以像其他的文件一样被索引到 。
【Elasticsearch|MySQL用得好好的,为什么要转ES?】然而默认情况文档从Indexing Buffer到文件系统缓存(即Refresh操作)是每秒分片自动刷新 , 所以这就是我们说ES是近实时搜索而非实时的原因:文档的变化并不是立即对搜索可见 , 但会在一秒之内变为可见 。
- 看不上|为什么还有用户看不上华为Mate40系列来看看内行人怎么说
- 采用|消息称一加9系列将推出三款新机,新增一加9E
- 会员|美容院使用会员管理软件给顾客更好的消费体验!
- 行业|现在行业内客服托管费用是怎么算的
- 闲鱼|电诉宝:“闲鱼”网络欺诈成用户投诉热点 Q3获“不建议下单”评级
- 美国|英国媒体惊叹:165个国家采用北斗将GPS替代,连美国也不例外?
- 桌面|日常使用的软件及网站分享 篇一:几个动态壁纸软件和静态壁纸网站:助你美化你的桌面
- 同轴心配合|用SolidWorks画一个直角传动,画四个零件就行
- 先别|用了周冬雨的照片,我会成为下一个被告?自媒体创作者先别自乱阵脚
- 速度|华为P50Pro或采用很吓人的拍照技术:液体镜头让对焦速度更快