AlphaGo原来是这样运行的,一文详解多智能体强化学习( 七 )
 文章插图
文章插图
图 11:AlphaGo 在 2016 年击败人类玩家 。 图源:
实时战略游戏
MARL 的另一种重要的游戏应用领域 , 是实时战略游戏 , 包括星际争霸 , DOTA , 王者荣耀 , 吃鸡等 。 该类游戏相比于前面提到的国际象棋、围棋等回合制类型的游戏 , 游戏 AI 训练的难度更大 , 不仅因为游戏时长过长、对于未来预期回报的估计涉及到的步数更多 , 还包括了多方同时参与游戏时造成的复杂空间维度增大 , 在一些游戏设定中可能无法获取完整的信息以及全局的形势(比如在星际争霸中 , 不知道迷雾区域是否有敌方的军队) , 在考虑队内合作的同时也要考虑对外的竞争 。
OpenAI Five 是 OpenAI 团队针对 Dota 2 研发的一个游戏 AI [13] , 智能体的策略的学习没有使用人类玩家的数据、是从零开始的(learn from scratch) 。 考虑游戏中队内英雄的协作 , 基于每个英雄的分布式控制方式(即每个英雄都有各自的决策网络模型) , 在训练过程中 , 通过一个超参数 “team spirit” 对每个英雄加权、控制团队合作 , 并且使用基于团队整体行为的奖励机制来引导队内合作 。 考虑和其他团队的对抗 , 在训练过程中使用自我对抗的方式(也称为虚拟自我博弈 , fictitious self-play ,FSP)来提升策略应对复杂环境或者是复杂对抗形势的能力 。 这种自我对抗的训练方式 , 早在 2017 年 OpenAI 就基于 Dota2 进行了相关的研究和分析 , 并发现智能体能够自主地学习掌握到一些复杂的技能;应用在群体对抗中 , 能够提升团队策略整体对抗的能力 。
AlphaStar 是 OpenAI 团队另一个针对星际争霸 2(Starcraft II)研发的游戏 AI , 其中在处理多智能体博弈问题的时候 , 再次利用了 self-play 的思想并进一步改进 , 提出了一种联盟利用探索的学习方式(league exploiter discovery) 。 使用多类个体来建立一个联盟(league) , 这些个体包括主智能体(main agents)、主利用者(main exploiters)、联盟利用者(league exploiters)和历史玩家(past players)四类 。 这几类智能体的策略会被保存(相当于构建了一个策略池) , 在该联盟内各类智能体按照一定的匹配规则与策略池中的其他类智能体的策略进行对抗 , 能够利用之前学会的有效信息并且不断增强策略的能力 , 解决普通的自我博弈方法所带有的 “循环学习” 问题(“Chasing its tail”) 。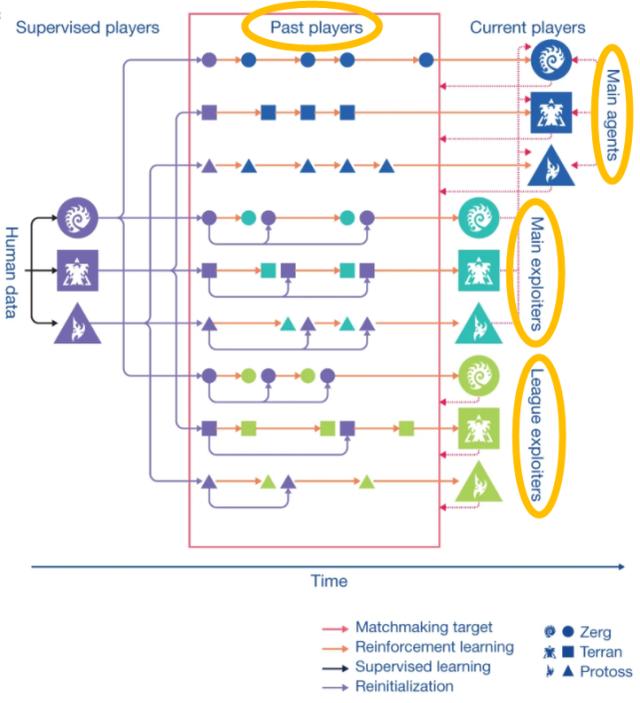 文章插图
文章插图
图 12:联盟利用者探索(league exploiter discovery)的学习框架 。 图源:[14]
3.2. 多机器人避碰
在现实生活中 , 多机器人的应用场景主要是通过多个机器人的协作来提升系统的性能和效率 , 此时多智能体强化学习的关注重点主要在于机器人(智能体)之间的合作 。
在移动机器人方面 , 自主避障导航是底层应用的关键技术 , 近几年通过强化学习的方法来学习单机器人导航策略这方面的工作成果比较多;而当环境中存在多个移动机器人同时向各自目标点移动的时候 , 需要进一步考虑机器人之间的相互避碰问题 , 这也是 MARL 在多机器人导航(multi-robot navigation)领域的主要研究问题 。 Jia Pan 教授团队 [13] 在控制多机器人避碰导航问题上使用了集中式学习和分布式执行的机制 , 在学习过程中机器人之间共享奖励、策略网络和值函数网络 , 通过共享的经验样本来引导相互之间达成隐式的协作机制 。 文章插图
文章插图
图 13:多机器人向各自目标点移动过程中的相互避碰 。 仓库物件分发是该问题的常见场景 , 多个物流机器人在向各自指定的目标点移动过程当中 , 需要避免和仓库中的其他物流机器人发生碰撞 。 图源:[15]
另外 , 不仅有机器人和机器人之间的避碰问题 , 有一些工作还考虑到了机器人和人之间的避碰问题 , 如 SA-CADRL(socially aware collision avoidance deep reinforcement learning)。 根据该导航任务的具体设定(即机器人处在人流密集的场景中) , 在策略训练是引入一些人类社会的规则(socially rule) , 相当于要让机器人的策略学习到前面 1.2.3 部分提到显式的协调机制 , 达成机器人与人的行为之间的协作 。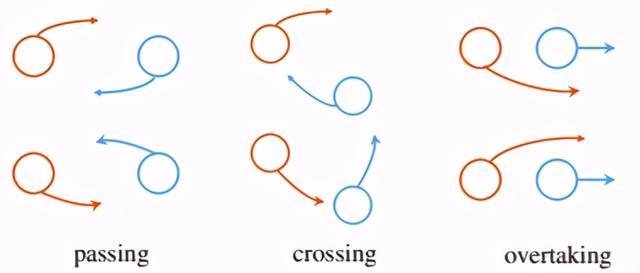 文章插图
文章插图
图 14:左图展示了相互避碰时的两种对称规则 , 上面为左手规则 , 下面为右手规则 。 右图是在 SA-CADRL 方法中模型引入这样的对称性信息 , 第一层中的红色段表示当前智能体的观测值 , 蓝色块表示它考虑的附近三个智能体的观测值 , 权重矩阵的对称性是考虑了智能体之间遵循一定规则的对称行为 。 图源:[16]
- 对手|一加9Pro全面曝光,或是小米11最大对手
- 行业|现在行业内客服托管费用是怎么算的
- 王兴称美团优选目前重点是建设核心能力;苏宁旗下云网万店融资60亿元;阿里小米拟增资居然之家|8点1氪 | 美团
- 手机基带|为了5G降低4G网速?中国移动回应来了:罪魁祸首不是运营商
- 技术|做“视频”绿厂是专业的,这项技术获人民日报评论点赞
- 互联网|苏宁跳出“零售商”重组互联网平台业务 融资60亿只是第一步
- 体验|闭上眼睛点外卖是什么感觉?时隔一年再次体验,进步令人欣慰
- 再次|华为Mate40Pro干瞪眼?P50再次曝光,这次是真香!
- 当初|这是我的第一部华为手机,当初花6799元买的,现在“一文不值”?
- 无国界|嘴上说着支持华为,却为苹果贡献了2000亿!还真是科技无国界啊?