15张图来了解「树」,面试再也不怕被刷了( 三 )
由前文可知前缀表达式的表达方式就是 *+cab, 我们常规的表达式的计算是中序的 , 其表达式就是(a+b)*c 。
我们可以理解为将表达式利用二叉树化 , 然后通过中序遍历的方式进行提取 , 如果需要发生组合时 , 需要我们借助括号的形式表示优先级 , 这样也有一个弊端 , 就是当多个嵌套的时候需要的括号较多 。
树的遍历之后序遍历二叉树简介
- 后序遍历:左右根
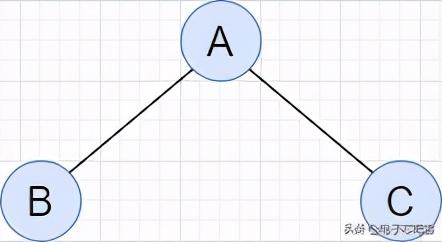 文章插图
文章插图多个结点相互嵌套构成的二叉树如下图所示 , 在访问遍历一开始的时候 , 先访问左节点B再访问右结点C最后访问A;
由于B结点其中也包含了新的结点 , 在面对处理的结点后还存在有与之相联的结点的时候 , 需要优先处理其的子结点 , 这也是“递归”的基本思路;
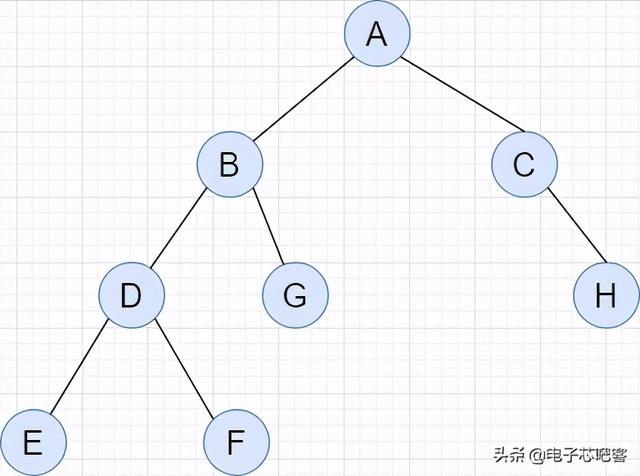
因此 , 由于B属于DG的根结点 , 相较于B , 应该先访问D结点 , 而又由于D结点属于EF的根结点 , 就又变成先访问E结点 , E属于最末端了 , 根据后序遍历左右根的访问顺序 , 依次生成EFDGB作为一个整体;
接着我们需要访问C , 由于C又是^HC之中的根结点 , 我们先访问这个空结点 , 又因为其是一个空的结点 , 我们会跳过 , 就变成了HC的访问顺序;
最后在汇总的时候EFDGB作为左节点 , HC作为右结点 , A作为根结点 , 完成我们最终的遍历顺序EFDGBHCA 。
 文章插图
文章插图代码实现
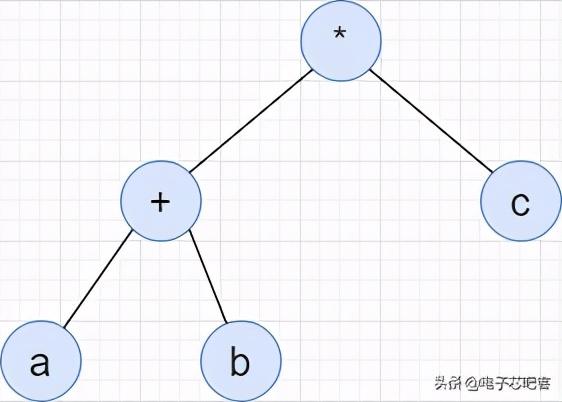
//树的后序遍历 Post-order traversalvoid postorder(Node* node){if (node != NULL){inorder(node->left);inorder(node->right);printf("%d ",node->data);}}后缀表达式后缀表达式与前缀表达式不同 , 前缀表达式采用先序遍历的方式遍历访问我们的公式顺序 , 常规式则就是中序方式 , 而后缀表达式采用后续遍历的方式进行访问 。如图 , 为常规表达式:(a+b)*c
其二叉树的表现形式为:
 文章插图
文章插图而后缀表达式的表达方式就是ab+c*, 相较于前缀表达式 , 后缀表达式则就是将符号进行后移 , 其在计算机中的读取运算概念也符合栈的思路 , 因此没有什么特殊的不同 。
总结树的概念还有很多 , 比如DFS(深度优先搜索) , 森林与树 , 哈夫曼树等等 , 这里小编讲一些树的基础 , 帮助大家入门了解 。 我们下一期 , 再见!
- 看不上|为什么还有用户看不上华为Mate40系列来看看内行人怎么说
- 空调|让格力、海尔都担忧,中国取暖“新潮物”强势来袭,空调将成闲置品?
- 手机基带|为了5G降低4G网速?中国移动回应来了:罪魁祸首不是运营商
- 占营收|华为值多少钱
- 页面|如何简单、快速制作流程图?上班族的画图技巧get
- 逛逛|淘宝内容化再升级:“买家秀”变身“逛逛”试图冲破算法局限
- 计费|5G是如何计费的?
- 公式|?有人把 5G 讲得这么简单明了
- 截长|手机截图怎么截长图
- 精英|业务流程图怎么绘制?销售精英的经验之谈