部署|3年部署3000套PG实例的架构设计与踩坑经验( 四 )
文章插图
但是Gin也不是万能的,它也有一些短板,有些场景下使用Gin索引会适得其反。概况起来主要有以下几点,需要注意:
两边界的范围查询效率很低;
按上下边界分别扫描,效率很低。但优化器的估算cost却严重偏低,容易误走gin索引
高基数字段的索引的效率不如btree;
- 空间占用
查询速度
Fast update list过大的会影响点查询的QPS(可通过gin_pending_list_limit控制)
- 对固定的多字段AND组合查询(比如 a=1 and b=2),效率不如btree;
不支持唯一索引;
不支持使用索引优化like前缀匹配,比如like ‘abc%‘(pg_trgm支持);
不支持使用索引优化组合字段的oredr by,group by(单字段支持);
对更新的性能影响比btree更大;
比btree更容易膨胀。
PostgreSQL是多进程架构,每一个连接对于一个进程。每个进程的私有内存空间中会缓存一些元数据,比如系统表数据,表定义,执行计划等等。如果使用不当,可能会由于后端进程私有内存占用过大导致系统内存不足,导致内存SWAP等问题。

文章插图
我们可以用下面的命令查看某个后端进程的私有内存分配情况:
gdb --batch-silent -ex ‘call MemoryContextStatsDetail(TopMemoryContext,100)’ -p ${后端进程号}
执行上面的命令后,相关输出反应在PostgreSQL的日志文件中。
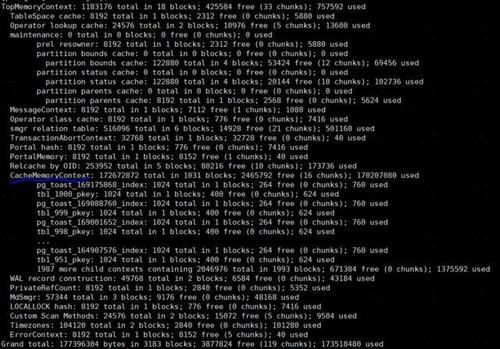
文章插图
上面这个图里,私有内存的大部分被元数据缓存占用了,即CacheMemoryContext。
通常,元数据缓存中占用内存最多的是下面两个系统表
- pg_statistic
pg_attribute
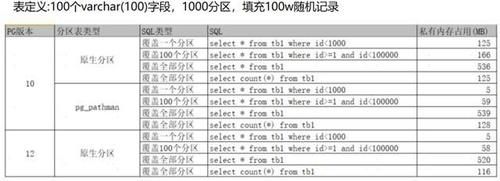
文章插图
从上面的数据我们可以知道,表相关的元数据缓存占用内存的大小主要和下面几个因素有关:
- 查询实际访问的表或分区的数量
查询实际访问的字段的数量
- 调小应用端连接池大小(max pool size和min pool size);
部署pgbouncer连接池;
减少分区数;
访问不同表或分区的连接尽量隔离,比如需要访问全部分区的连接使用单独的连接池;
通过ALTER TABLE SET STATISTICS对不需要通过柱状图评估选择性的字段,减少收集的统计信息;
拆分负载。
- 读写分离
sharding
PostgreSQL的MVCC实现机制和其它传统的关系数据库不太一样。更新记录时不是在原地更新并且把修正的前镜像记录到UNDO日志,而是在数据文件中把原来的记录标记为“被删除”再插入一条新的记录,以后再通过VACUUM把这些”被删除“记录占用的空间回收掉。也就是说PostgreSQL中只有REDO日志,没有UNDO日志。在这种MVCC设计下,PostgreSQL回滚事务可以立即完成,和事务大小无关,回滚事务时只需要在CLOG事务状态文件中标记这个事务的状态为ABORTED即可。
PostgreSQL的MVCC实现机制带来的问题是如果垃圾回收不及时容易导致数据文件膨胀,这也是很多人吐槽PostgreSQL的地方。不过,不能单纯地把PostgreSQL的MVCC机制视作一个槽点,只是MVCC的不同实现方式而已。不知道大家注意到没有,很多新兴的分布式数据库库,也都采用了类似PostgreSQL标记删除的MVCC机制。
作为PostgreSQL的使用者,我们需要做的事是要确保PostgreSQL的垃圾回收工作能够正常运作。具体有下面几件事情要做。
1)autovacuum参数调优
PostgreSQL中有一个后台的autovacuum进程专门负责回收垃圾,我们可以根据数据库的配置和业务特点对autovacuum进行合理的参数设置,确保autovacuum回收垃圾的速度足够快,对数据库负载冲击又比较平滑。
比如下面几个参数:
其中,最需要修改的是autovacuum_vacuum_cost_limit,其含义是一次回收最多消耗多少cost则暂停一会(autovacuum_vacuum_cost_delay的设定值)。默认值为200,这个值对于现代的设备显得太小,容易导致垃圾回收速度跟不上垃圾产生的速度,使用SSD时可以考虑把它设置为10000。
另外,autovacuum默认在表中被更新的元组比率达到20%的时候启动垃圾回收,对于亿级别的大表,会导致一个问题。就是一次垃圾回收的任务太大,垃圾回收时间过长。
所以建议采用以下优化措施:
- 车企|华为不造车!但任正非加了一个有效期,3年
- 部署模式|5G toB大戏拉开帷幕,公网专用正当其时
- 谁给了|3年价格翻5倍,快“用不起”的共享充电宝,谁给了它涨价的底气
- 好评|1933年的一份“快递”,1949年才送到,虽相隔16年,却得国人好评
- 提问|比特币创近3年新高,再迎终极提问:比特币是钱吗?
- 软件定义存储之ScaleIO,VMWare环境详细部署和使用
- Rancher 部署服务测试
- YAPI接口文档部署教程 Ubuntu 16.04
- GPU|干货|基于 CPU 的深度学习推理部署优化实践
- 未来3年,传统电商将大量淘汰:取而代之的是“IP电商”