quantopian系列—Algorithm( 五 )
查看投资组合状态
在重新平衡之前 , 您可能需要检查您已经持有哪些资产 。 您可以使用Portfolio的属性来查看您的投资组合的状态 。 例如 , 您可以使用context.portfolio.position访问您的算法的Position , 其中包含所有未平仓合约的字典 , 或者使用context.portfolio.cash查看您的投资组合中的当前现金量 。
- 常见的再平衡问题
订购退市证券或在IPO前订购证券的行为会在回测中引发错误 。 Pipeline 只返回在每个模拟日在支持的交易所上市的资产 , 因此从pipeline_output()检索到的任何资产都应该是可以交易的 。 如果你是手动引用资产 , 你可能需要检查该资产是否仍然上市 。 要检查某项资产是否可以在算法中的某一点进行交易 , 使用can_trade()(如果该资产已经上市并至少交易过一次 , 则返回True) 。
陈旧的价格
Quantopian向前填充定价数据 。 然而 , 您的算法可能需要在下单之前知道某只股票的价格是否是最近一分钟的价格 。 如果资产是活的 , 但最新的价格是前一分钟的 , 那么is_stale()方法返回True 。
未完成的订单
您可以使用订单状态函数来获取订单的信息 。 例如 , 您可以通过调用get_order()查看特定订单的状态 , 或者通过调用get_open_orders()查看所有未结订单的列表 。 关于订单状态函数的完整列表 , 请参见 API 参考资料 。
所有未结订单在一天结束时都会被取消 , 无论是在回溯测试还是真实交易中 。 对于通过任何方式(使用Optimize API和手动订单方法)下的订单都是如此 。 您也可以在当天结束前使用cancel_order()取消订单 。
记录与绘图当你运行算法时 , 你可能想记录或绘制那些由backtester自动跟踪的指标以外的自定义指标 。
- 记录
由于性能原因 , 日志记录是有速率限制的(节流) 。 基本限制是每次调用初始化时有两条日志信息 , 每分钟多两条日志信息 。 每个回溯测试有一个额外的20条日志消息的缓冲区 。 一旦超过限制 , 消息将被丢弃 , 直到缓冲区被清空 。 会显示一条消息 , 解释一些消息被丢弃的原因 。
下面是两个例子:
- 假设在initialize()中 , 你记录了22行 。 两行是允许的 , 再加上20条额外的日志信息 , 所以这是可行的 。 但是 , 第23行日志会被丢弃 。
- 假设每分钟运行一个定期函数 , 在该函数中 , 你记录了三行日志 。 每次调用定期函数时 , 允许记录两行 , 加上多出来的20行中的一行被消耗掉了 。 在第21次调用时 , 记录了两行 , 最后一行被丢弃 。 随后的日志行也会被丢弃 , 直到缓冲区被清空 。
- 绘图
在算法中 , 你有一些(有限的)绘图功能 。 使用record() , 您可以通过使用关键字参数传递系列名称和相应的值来创建时间系列图 。 在一个算法中 , 最多可以绘制五个日级粒度的系列图 。 然后 , 时间序列会显示在性能图下方的图表中(如果您点击 "构建算法" , 或者如果您运行完整的回溯测试 , 则显示在 "活动 "标签下) 。
在回溯测试中 , 会使用每天最后记录的值 。 因此 , 我们建议使用schedule_function()每天记录一次值 。
这个最小的例子记录并绘制了MSFT和AAPL每天收市时的价格:
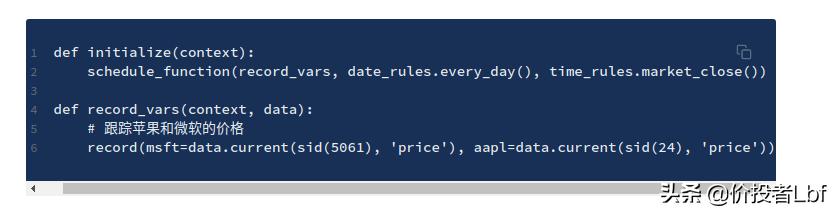 文章插图
文章插图常见错误
- 编写更快的算法
使用Pipeline: Pipeline是Quantopian上访问数据的最有效方式 。 在可能的情况下 , 您应该使用Pipe来执行计算 , 以使您的反向测试尽可能快地运行 。
只有在您需要的时候才会访问分钟数据:您可以通过BarData方法访问分钟频率的价格和交易量数据 , 而且这些数据是按需加载的 。 当您调用数据时 , 您需要支付访问数据的性能成本 。 如果你的算法每分钟都要检查一个价格 , 那就会有性能成本 。 如果你不那么频繁地需要价格数据 , 减少要求它的频率会加快你的算法 。
避免 "for "循环:尽量使用向量化计算 , 而不是for循环 。 Quantopian上的大多数数据结构都支持矢量化计算 , 这通常比for循环快得多 。 在Quantopian上 , numpy数组和pandas数据结构是两个常见的支持向量化计算的实体 。
- 看不上|为什么还有用户看不上华为Mate40系列来看看内行人怎么说
- 采用|消息称一加9系列将推出三款新机,新增一加9E
- 世代|Z星球——腾讯布局Z世代教育社交的新尝试
- 脉搏|把握时代发展脉搏,尽展巴蜀版权风采——2020年成都数字版权交易博览会成功举办
- 系列|首销300000台!红米Note 9系列,或许可以说恭喜你了?
- 系列|联想碰瓷Redmi后正式复活乐檬手机!乐檬K12系列即将到来
- 系列|Redmi Note9系列三剑客来袭,差别到底有多大?该如何选择?
- 超强|RedmiNote9系列发布!天玑800U赋予超强5G性能
- 回顾|华为P系列回顾
- 情况|刚发布就卖出30万台:红米Note9系列稳了,销售情况追赶前代