quantopian系列—Algorithm
在Quantopian上 , "算法 "是使用算法API定义交易逻辑的Python程序 。 算法必须在IDE中开发(而不是在Research中) 。 在Quantopian上 , 一个算法是运行回溯测试所需的工作单位 。 回溯测试是对历史数据的模拟 , 以了解特定策略在现实交易条件下的表现 。
Algorithms与Pipeline不同 , 它专注于定义排序逻辑和组合构建 , 而不是查询数据和构建因子 。 通常情况下 , 算法会 "附加 "一个Pipeline , 然后根据Pipeline中定义的因子来模拟订单填充和组合构建 。
本页介绍了在Quantopian上使用算法API开发算法的过程 。
算法结构在Quantopian上 , 交易算法是Python程序 , 主要分为四个部分 。
- 初始化算法:初始化状态 , 附加一个Pipeline , 定期函数 。
- 对数据进行计算:导入你的算法用来建立你的投资组合的数据 , 然后对数据进行必要的计算 。
- 重新平衡资产组合:根据您导入的数据 , 计算结果购买或出售资产 。
- 记录和绘图:对记账变量进行记录和绘图 , 以便进一步分析 。
本页其余部分将更详细地介绍Quantopian交易算法的四个部分 。
在Quantopian上开发算法时算法API提供了构建交易算法的结构化方法 。 算法API可以在IDE中使用 , 而不是在research中使用 。
初始化算法中的初始化步骤负责运行交易算法中只需要执行一次的代码 。 最常见的是 , 这一步包括初始化状态、附加Pipeline和定期函数 。
在Quantopian上 , 所有的初始化逻辑都是在initialize()方法中定义的 。 initialize()是一个必需的方法 , 只被调用一次 , 在回测开始时 。
下面的章节描述了在initialize()中可以执行的各种操作 , 其中很多是由quantopian.algorithm模块中的函数控制的 。
从技术上讲 , initialize()是算法中唯一需要的函数 , 所以通常最好从定义它开始 。 当然 , 如果不定义其他部分 , 你的算法也不会有什么作用!
- 初始化状态
Context对象是一个类AlgorithmContext的Python字典 。 在整个算法中 , Context对象是用来维护状态的 。 这个对象被传递给initialize() , before_trading_start() , 以及算法中的所有预定函数 。 你应该使用Context而不是全局变量在算法中的各个方法之间传递变量值 。
Context字典已经被增强 , 因此可以使用点符号(context.some_property)以及传统的括号符号来访问属性 。 例如 , 你可以使用上下文来设置一个参数 。
 文章插图
文章插图可以在算法的任何方法中定义和修改Context变量 , 而不仅仅是initialize() 。 然而 , 你应该在initialize()方法中定义初始Context变量值和贯穿整个算法的Context变量 。
- 附加Pipeline
例如 , 下面的代码将把一个空的Pipeline附加到你的算法中 , 名称为my_pipeline 。
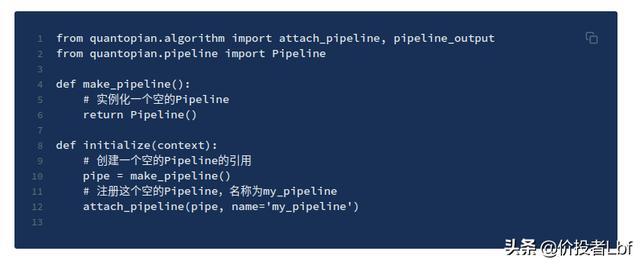 文章插图
文章插图附加Pipeline会将其注册 , 这样它的计算就会在回测的每一个模拟日中实际执行 。 一旦你的Pipeline被附加到算法上 , 你就可以每天通过pipeline_output()访问该Pipeline的输出 。 在算法中使用Pipeline结果的工作将在本文档后面介绍 。
Pipeline API在Research和IDE中是完全一样的 , 所以你可以直接从笔记本中复制你的pipeline定义到你的算法中 。 只要确保删除对 run_pipeline() 的任何引用 , 并将对 symbols() 的任何引用替换为 symbol() (如果您在Pipeline中使用它们的话) , 因为这些函数是它们各自环境的专有函数 。
Pipeline执行
当回溯测试在你限定的日期中进行时 , Pipeline计算不会在每个模拟日执行 。 由于性能原因 , 计算是以 "块 "为单位运行的 。
在回溯测试开始时 , 附加的Pipeline以1周为一个块执行 。 这第一个1周分块预先获取所需的数据 , 并执行回测模拟第一周的计算 。 这1周分块的每一天的结果都会被缓存起来 , 并在回测者进行第一周模拟时适当地进行访问 。 在模拟的第一周之后 , 预计算Pipeline结果的过程会重复进行 , 但后续的Pipeline执行是以6个月为块进行的 。
- 看不上|为什么还有用户看不上华为Mate40系列来看看内行人怎么说
- 采用|消息称一加9系列将推出三款新机,新增一加9E
- 世代|Z星球——腾讯布局Z世代教育社交的新尝试
- 脉搏|把握时代发展脉搏,尽展巴蜀版权风采——2020年成都数字版权交易博览会成功举办
- 系列|首销300000台!红米Note 9系列,或许可以说恭喜你了?
- 系列|联想碰瓷Redmi后正式复活乐檬手机!乐檬K12系列即将到来
- 系列|Redmi Note9系列三剑客来袭,差别到底有多大?该如何选择?
- 超强|RedmiNote9系列发布!天玑800U赋予超强5G性能
- 回顾|华为P系列回顾
- 情况|刚发布就卖出30万台:红米Note9系列稳了,销售情况追赶前代