深层网络的隐式语义数据扩增( 五 )
在 ImageNet 上 , 我们使用与 CIFAR 相同的 L2 权重衰减和动量来训练 300 个迭代的所有模型 。 初始学习率设置为 0.2 , 并用余弦进行退火 。 批大小设置为 512 。 我们对 DenseNets 采用 λ0 =1 , ResNet 和 ResNeXts 采用 λ0=7.5 , ResNet-101 使用的是 λ0=5 。
所有基线均采用上述相同的训练配置 。 如果它在基本模型中没有应用 , 则将 Dropout 率设置为 0.3 , 以便进行比较 , 遵循[37]中的说明 。 对于干扰标签中的噪声率 , 在 CIFAR-10 和 CIFAR-100 数据集上的 Wide-ResNet-28-1 和在 CIFAR10 上的 ResNet-110 中采用 0.05 , 而 CIFAR100 上的 ResNet-110 使用 0.1 。 Focus loss 包含两个超参数 α 和 γ 。 大量的组合已经在验证集上进行了测试 , 我们最终选择 α=0.5 和 γ=1 进行所有四个实验 。 对于 Lqloss , 虽然[16]指出 q=0.7 在大多数情况下都能达到最佳性能 , 但我们建议在我们的实验中 , q=0.4 更适合 , 因此采用 q=0.4 。 对于中心损失 , 我们发现它的性能很大程度上受中心损失模块的学习率的影响 , 因此它的初始学习率设置为 0.5 , 以获得最佳的泛化性能 。
对于基于生成器的增强方法 , 我们采用了[39,40,41,42]]中引入的 GANS 结构来训练生成器 。 对于 WGAN , 在 CIFAR-10 数据集中为每个类训练一个生成器 。 对于 CGAN、ACGAN 和 infoGAN , 只需要一个模型就可以生成所有类的图像 。 采用标准正态分布的 100 维噪声作为输入 , 生成与其标签相对应的图像 。 特别地 , infoGAN 具有两个维度的额外输入 , 它们代表整个训练集的特定属性 。 合成图像在每一个批处理中都有固定的比例 。 基于验证集的实验 , 将广义图像的比例设为 1/6 。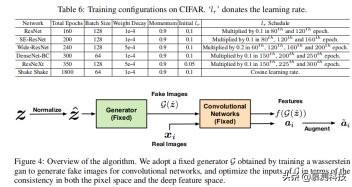 文章插图
文章插图
C 反向卷积网络
为了明确说明 ISDA 所产生的语义变化 , 我们提出了一种将深度特征映射回像素空间的算法 。 一些额外的可视化结果如图 5 所示 。
图 4 显示了该算法的概述 。 由于卷积网络(如 ResNet 或 DenseNet)没有闭合形式的逆函数 , 映射算法的作用类似于[43]和[9] , 通过固定模型和调整输入来找到与给定特征相对应的图像 。 然而 , 考虑到 ISDA 本质上增强了图像的语义 , 我们发现直接优化像素空间中的输入是无关紧要的 。 因此 , 我们添加了一个固定的预训练生成器 G , 它是通过训练 wasserstein GAN[39]获得的 , 以生成分类模型的图像 , 并优化生成器的输入 。 这种方法使得用增强语义有效地重建图像成为可能 。
映射算法可分为两个步骤: 文章插图
文章插图
所提出的算法是在单个批处理上执行的 。 在实际应用中 , 采用 ResNet-32 网络作为卷积网络 。我们采用标准梯度下降(GD)算法进行 10000 次迭代来解决 Eq.15 16 。 对于步骤一和步骤二 , 初始学习速率分别设置为 10 和 1 , 每 2500 次迭代除以 10 。 我们应用了 0.9 的动量和 1e-4 的 l2 重量衰减 。
D 附加实验结果
最新方法和 ISDA 的测试误差曲线如图 6 所示 。 ISDA 的性能一直优于其他方法 , 并且在所有情况下都表现出最好的泛化性能 。 值得注意的是 , ISDA 在 CIFAR-100 中降低了测试误差 , 这表明我们的方法更适合于样本较少的数据集 。 这一观察结果与本文的结果一致 。 除此之外 , 在 CIFAR-10 上 , 中心损失方法与 ISDA 相比具有一定的竞争力 , 但它并不能显著提高 CIFAR-100 的泛化能力 。 文章插图
文章插图
致谢本文由南京大学 ISE 实验室 2020 级硕士李彤宇转述翻译
- 智能手机市场|华为再拿第一!27%的份额领跑全行业,苹果8%排在第四名!
- 会员|美容院使用会员管理软件给顾客更好的消费体验!
- 行业|现在行业内客服托管费用是怎么算的
- 闲鱼|电诉宝:“闲鱼”网络欺诈成用户投诉热点 Q3获“不建议下单”评级
- 人民币|天猫国际新增“服务大类”,知舟集团提醒入驻这些类目的要注意
- 国外|坐拥77件专利,打破国外的垄断,造出中国最先进的家电芯片
- 技术|做“视频”绿厂是专业的,这项技术获人民日报评论点赞
- 面临|“熟悉的陌生人”不该被边缘化
- 峰会|这场峰会厉害了!政府企业专家媒体共议网络内容生态治理
- 中国|浅谈5G移动通信技术的前世和今生